
INT8量化训练
【GiantPandaCV导读】本文聊了两篇做INT8量化训练的文章,量化训练说的与quantization-aware Training有区别,量化训练指的是在模型训练的前向传播和后向传播都有INT8量化。两篇文章都是基于对梯度构建分析方程求解得到解决量化训练会引起的训练崩溃和精度损失严重的情况。
论文:《Distribution Adaptive INT8 Quantization for Training CNNs》
会议:AAAI 2021
论文:《Towards Unified INT8 Training for Convolutional Neural Network》
会议:CVPR 2020
引言:什么是量化训练
谷歌在2018年《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference》文章中,提出了量化感知训练(Quantization-aware Training,QAT),QAT只在前向传播中,加入模拟量化,这个模型量化指的是把模型参数进行线性量化,然后在做矩阵运算之前,把之前量化的模型参数反量化回去浮点数。而量化训练则是在前向传播和后向传播都加入量化,而且做完矩阵运算再把运算的结果反量化回去浮点数。《Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference》详细的内容在链接中:
MXNet实现卷积神经网络训练量化
Pytorch实现卷积神经网络训练量化(QAT)
一、Distribution Adaptive INT8
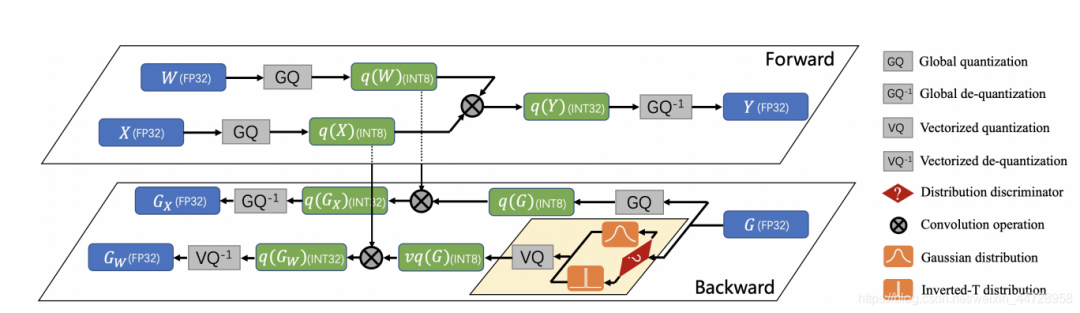
文章的核心idea是:Unified INT8发现梯度的分布不遵从一个分布即不能像权重一样归于高斯分布,Distribution Adaptive INT8认为梯度可以channel-wise看,分成两种分布,一个高斯分布,一个是倒T形分布,这样去minimize量化后梯度与原来梯度的量化误差Error,就可以了。Unified INT8也是类似minimize量化后梯度与原来梯度的量化误差Error的思想,与Distribution Adaptive INT8不同的是通过收敛性分析方程,发现可以通过降低学习率和减少梯度量化误差。总结:Distribution Adaptive INT8比Unified INT8多了一个先验,来构建分析方程。方法上,都是对梯度下手,修正梯度的值,都有对梯度进行截断。
Distribution Adaptive INT8采用了两个方法:Gradient Vectorized Quantization和Magnitude-aware Clipping Strategy。
对称量化:
这里, 是阈值范围,就是range
反量化:
公式(1)与之前常见的对称量化长的有一点不一样:
(2)
反量化: ,这里的s指的是scale,c是clipping阈值
其实公式(1)和(2)是等价变化,把公式(2)的s计算出来,就是 ,代入公式(2)
也就是等于公式(1)
Gradient Vectorized Quantization:这就是channel-wise的筛选哪些梯度的分布属于高斯分布还是倒T分布(a sharp with long-tailed shape distribution(Inverted-T distribution))。所以这两种分布:
通过实验设置为0.3
Magnitude-aware Clipping Strategy:
这个cliiping是在寻找最优截断阈值s
量化误差分析:(3)
是梯度的分布。
通过两个假设:
,误差分析方差变换为:
只要求导 就可以找出找出最优值 。然后分不同的梯度的分布进行讨论。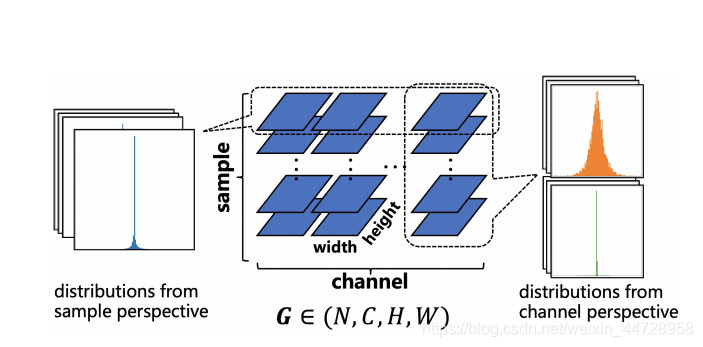
对于高斯分布:
对于倒T分布:倒T分布用分段均匀分布来表示
经过一顿公式推导得出: ,引进了 和 这两个超参数。
所以 和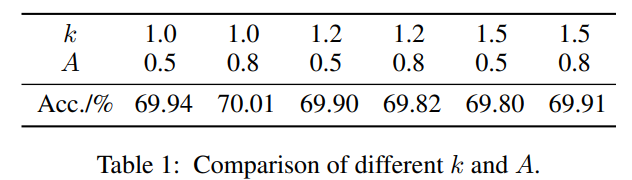
整个Distribution Adaptive INT8的pipeline:
SpeedUp: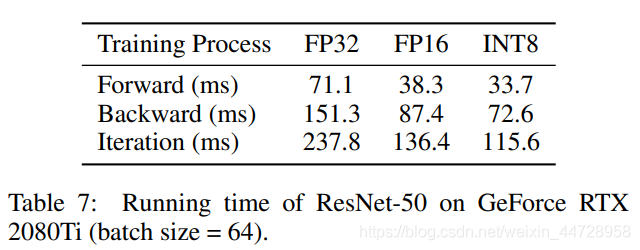
实验: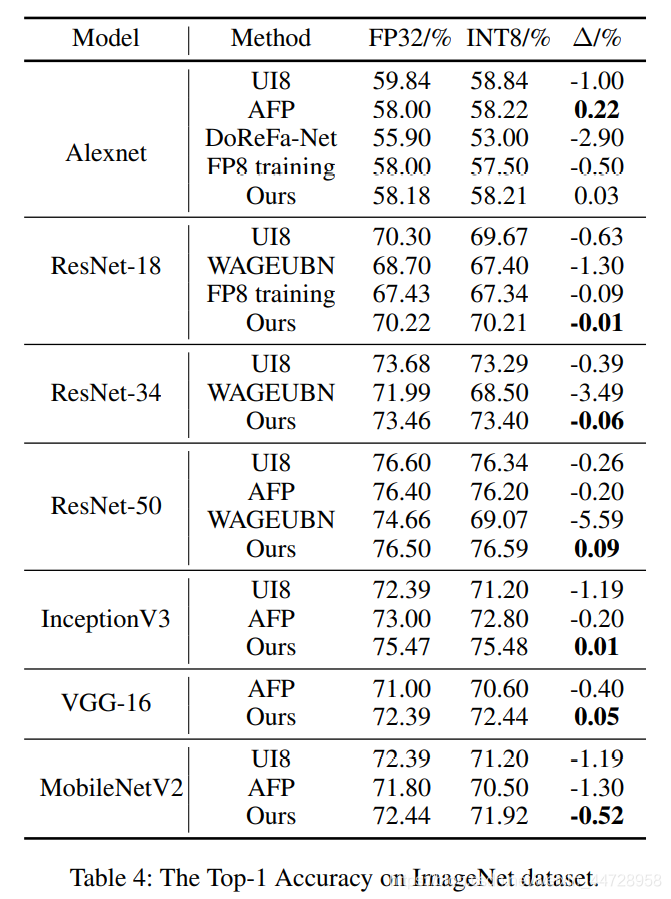
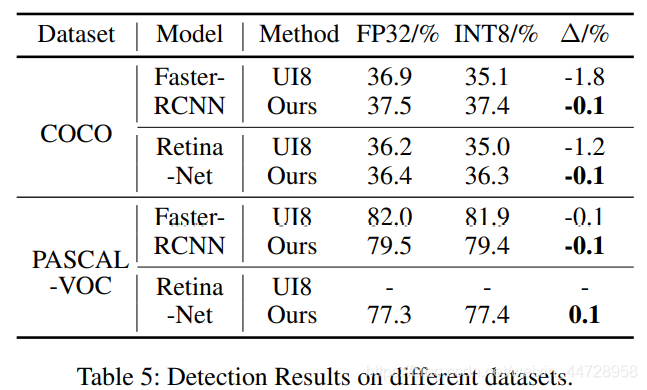
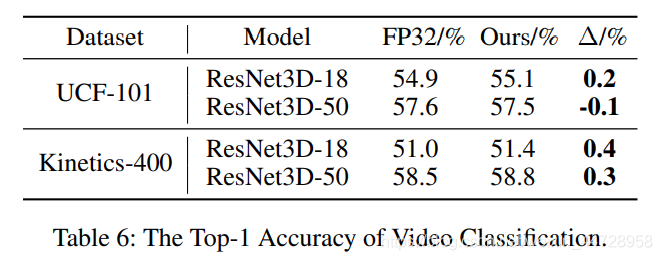
二、Unified INT8 Training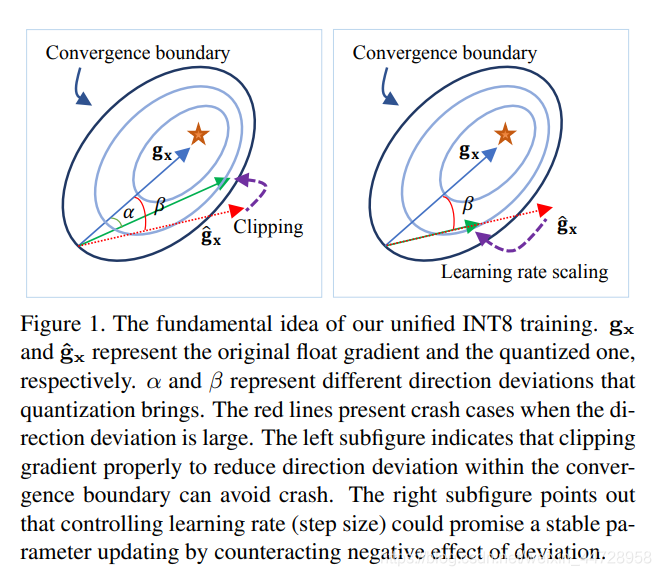
前面已经讲了Unified INT8的整体思路了。Unified INT8也是类似minimize量化后梯度与原来梯度的量化误差Error的思想,Unified INT8是通过收敛性分析方程,发现了可以通过降低学习率和减少梯度量化误差。另外,Unified INT8对梯度误差分析是layer-wise的,即不是上述Distribution Adaptive INT8那种channel-wise的方式。
通过收敛性证明: (4)
基于这两个假设:
公式(4)变换为:
因为T是迭代次数,T会不断增大,导致Term(1)趋向于0;
是误差,Term(2)说明,要最小化量化误差;
是量化-反量化后的梯度, 是学习率,Term(3)说明要降低学习率。
所以Unified INT8提出两个方法:Direction Sensitive Gradient Clipping和Direction Sensitive Gradient Clipping。
Direction Sensitive Gradient Clipping:
用余弦距离来度量量化前后梯度的偏差。
Deviation Counteractive Learning Rate Scaling:
这两个策略最终的用在了调整学习率,实验得出, 取0.1,取20。
整个pipeline:
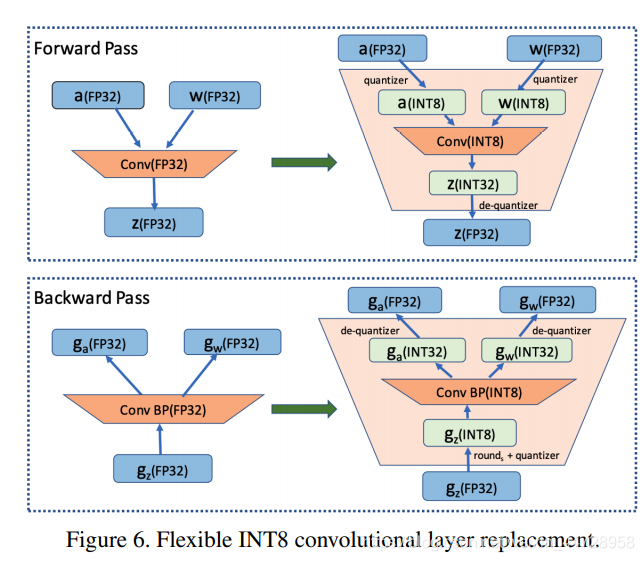
SpeedUp: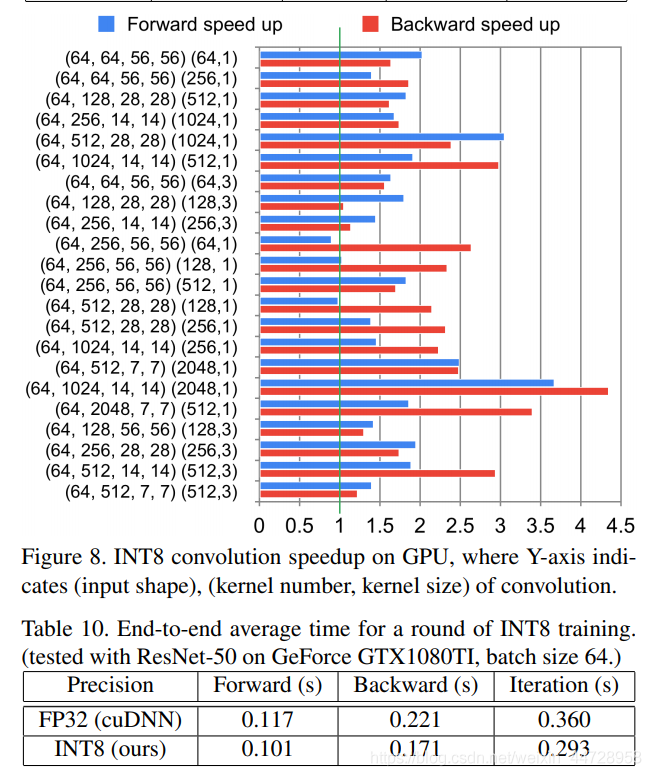
这里有个重要的cuda层的优化: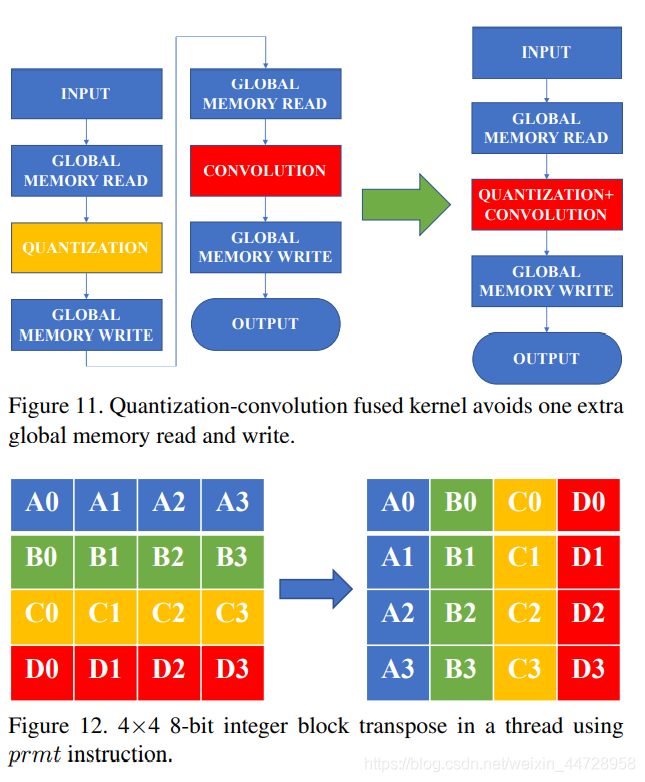
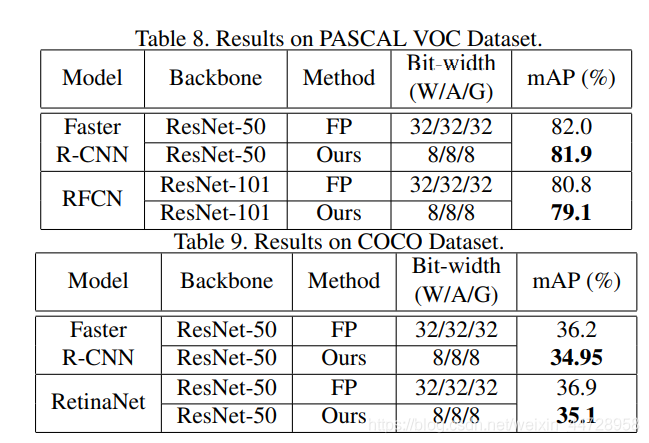
实验: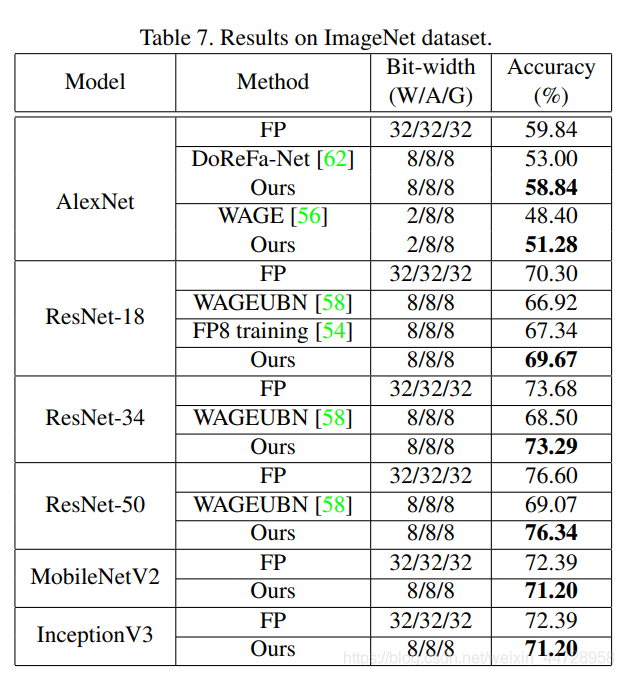
知乎链接:
(量化 | INT8量化训练)https://zhuanlan.zhihu.com/p/364782854
为了感谢读者的长期支持,今天我们将送出三本由 北京大学出版社 提供的:《机器学习入门 基于数学原理的Python实战》 。点击下方抽奖助手参与抽奖。没抽到并且对本书有兴趣的也可以使用下方链接进行购买。

书籍封面
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信: