
ACL 2022丨香港大学&华为诺亚方舟新工作:生成式预训练语言模型的量化压缩
点击上方“视学算法”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者丨陶超凡
生成式预训练语言模型 (pre-trained language models, PLM) 的规模不断扩大,极大地增加了对模型压缩的需求。尽管有各种压缩 BERT 或其变体的方法,压缩生成式 PLM (例如GPT)的尝试很少,潜在的困难仍不清楚。
在本文中,我们通过量化压缩生成 PLM。我们发现以前的量化方法在生成任务上失败,是由于模型容量减少导致的词嵌入同质化,以及不同模块的权重分布差异。
相应地,我们提出了一种令牌级的对比蒸馏损失函数来学习可区分的词嵌入, 以及模块级动态适应的量化器,以使量化器适应不同的模块。
各种任务的实证结果表明我们提出的方法优于最先进的压缩生成式 PLM 方法的优势明显。凭借与全精度模型相当的性能,我们在 GPT-2 和 BART 上分别实现了 14.4倍 和 13.4倍的压缩率。
我们把提出的量化GPT模型、BART模型分别取名「QuantGPT」与「QuantBART」。

论文地址: https://arxiv.org/abs/2203.10705
代码和模型即将开源。
基于 Transformer 的生成式预训练语言模型表现出强大的多任务和小样本学习能力,并在各种任务上取得显著成绩。但是,由于大量参数以及逐个令牌(token)的生成过程,它们在计算和内存方面通常都很昂贵。目前学术界提出了许多方法来压缩 PLM,但主要集中在理解任务上,比如使用 BERT 进行句子分类。
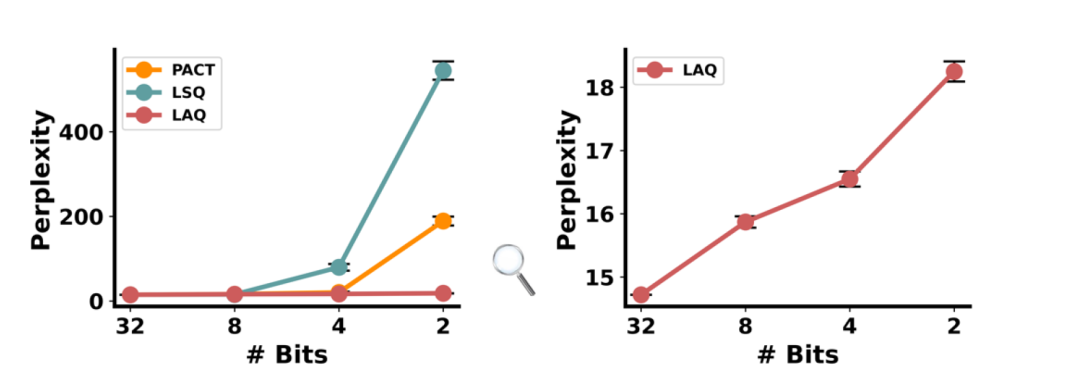
图1:不同量化方法的2bit GPT-2在PTB数据集的语言建模表现
在本文中,我们首先从量化角度来探索压缩生成式PLM。我们发现,将以前为 BERT 或计算机视觉任务设计的量化方法直接应用于生成式PLM 会导致性能不佳。如图1所示,随着权重比特数的减小,模型的性能急剧下降。这促使我们去研究量化生成式PLM的难点,并提出相应的解决策略。
2.1难点1:词嵌入同质化 (Homogeneous Word Embedding)

图2:在 PTB 数据集上训练的全精度和不同 2bit的最高频率的 500 个词嵌入的 T-SNE 可视化。不同量化方法的词嵌入显示出不同程度的同质化。
可以看出,全精度模型的词嵌入是分散可区分的,而之前的量化方法 PACT、LSQ 和 LAQ 学习的是同质的词嵌入,是聚集的且不易区分,特别是对于 PACT 和 LSQ。考虑BERT做句子分类问题,量化后的BERT只需要让句子整体的表征是准确的。但是对于GPT这种生成问题,GPT 以从左到右的顺序计算每个令牌,并且前一个令牌中产生的量化误差将传递给未来的令牌。所以量化GPT模型需要尽可能对每个量化后的词嵌入都学习准确。文章附录提供了不同量化方法的生成Demo,同质化的词嵌入会导致模型生成重复且无逻辑的句子。
2.2难点2:不同模块的权重分布差异 (Varied Distribution of Weights)
这里简单补充一下量化的背景知识。对一个模型的权重w,我们要学习一个量化器Q( )把全精度权重w量化为低比特的权重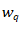 。其中α是量化器的一个参数,用于把权重的数值范围限定在[-α,α]。α的选取对量化器的效果是重要的。过小的α会导致很大一部分的权重被估计成-α或者α,损失了这些权重的全精度信息;而过大的α会导致过多的全精度数值被考虑到量化器的有效范围,导致量化器的量化间隔(quantization level)较大,量化的结果不准。
。其中α是量化器的一个参数,用于把权重的数值范围限定在[-α,α]。α的选取对量化器的效果是重要的。过小的α会导致很大一部分的权重被估计成-α或者α,损失了这些权重的全精度信息;而过大的α会导致过多的全精度数值被考虑到量化器的有效范围,导致量化器的量化间隔(quantization level)较大,量化的结果不准。
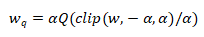
图3:在一个预训练的GPT中,同一个transformer block里两个不同模块的权重分布。竖线是PACT和我们方法学出的量化器的clipping factor α
从图3可以看出,不同模块的权重分布差异很大,这对α的估计造成了较大的挑战。
3.1令牌级对比学习
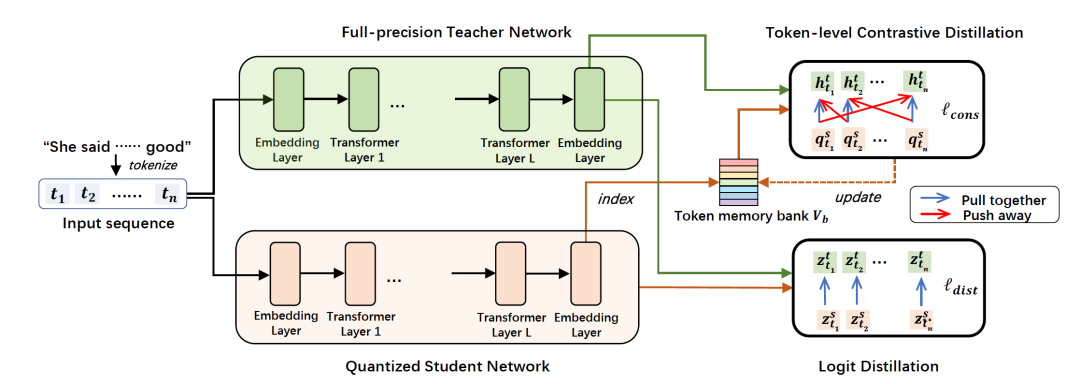
我们采取了全精度模型作为老师,量化模型作为学生的蒸馏学习框架。为了让学生模型可以在令牌粒度上学习到老师模型的信息。我们设计了令牌级对比学习:在一个句子里,同一个令牌在老师模型和学生模型中产生的表征应该被拉近,视为一对正样本;而同一个句子里不同令牌的表征视为负样本,应该被拉远。为了让学习模型产生的令牌表征平滑过渡,我们设计了一个memory bank存储词表里每个令牌的表征,用于对比学习中负样本的计算。
具体地,对于一个长度为n的句子,令牌级的对比学习为:
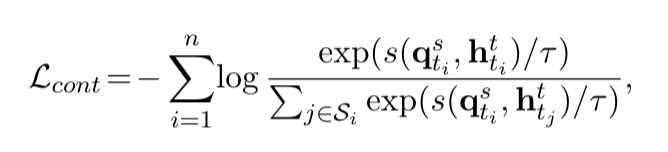
其中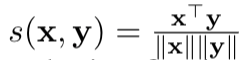 计算了相似度,
计算了相似度,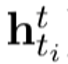 表示老师模型产生的令牌特征,
表示老师模型产生的令牌特征,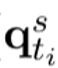 是学生模型产生的令牌特征的滑动平均版本(最后一个decoder的输出再经过一个线性映射)。的更新方式为
是学生模型产生的令牌特征的滑动平均版本(最后一个decoder的输出再经过一个线性映射)。的更新方式为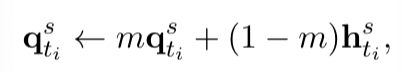
3.2 模块级动态适应的量化器
我们根据每个模块权重的统计数据提出了一种简单而有效的动态缩放。具体来说,我们不是直接对所有模块初始化一个相同的clipping factor α,而是转而学习一个新的缩放因子 γ,它与平均权重大小相乘获得clipping factor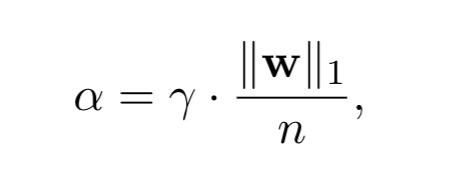 γ被初始化为1。这不仅简化了初始化,而且确保了初始的α不会远离全精度权重,无论不同模块的权重分布的差异有多大。我们进而推出了这个新的缩放因子γ的更新公式。
γ被初始化为1。这不仅简化了初始化,而且确保了初始的α不会远离全精度权重,无论不同模块的权重分布的差异有多大。我们进而推出了这个新的缩放因子γ的更新公式。
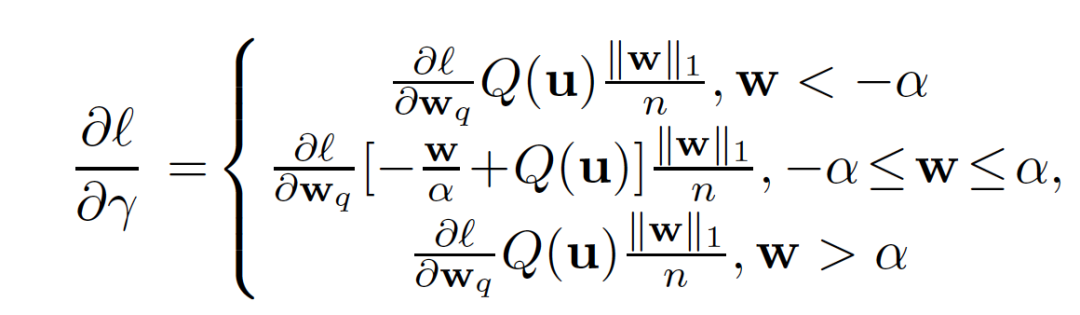
这个更新公式不仅考虑到了在[-α,α]范围内的权重对的影响,也考虑在[-α,α]范围外权重的影响。结果证明这样学习clipping factor,比之前工作中更新时只考虑[-α,α]范围外权重的效果更好。
首先,我们在GPT-2上分别做了PTB,wikitext-2,wikitext-103数据集的语言建模任务和Persona-Chat数据集的对话理解任务。我们的方法QuantGPT在生成文本预训练模型的量化任务上效果提升明显。其中W-E-A表示权重-嵌入层-激活值的量化比特数。
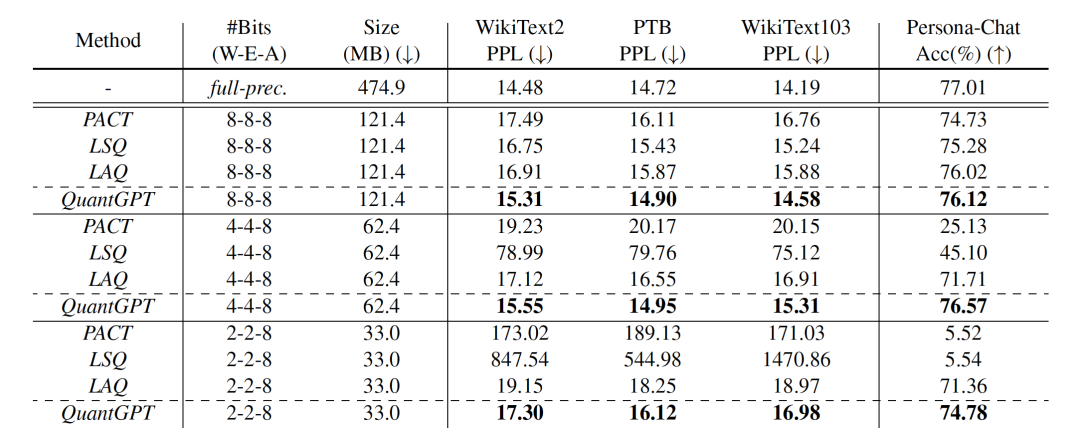
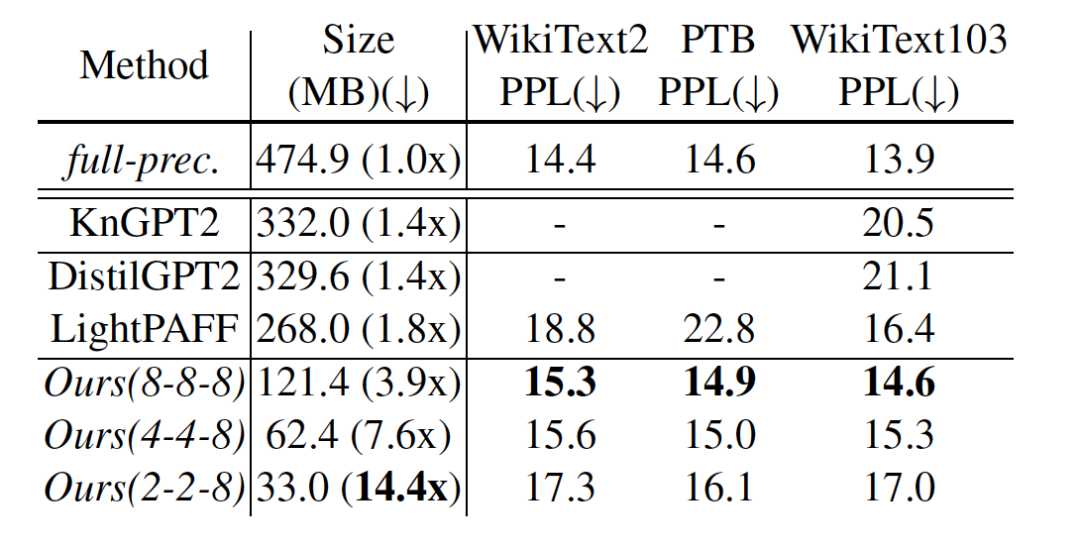
我们也和最新的GPT-2压缩方案对比,包括KnGPT2(基于张量分解),DistilGPT2, LightPAFF(基于蒸馏),我们的方法QuantGPT在模型大小和效果上优势明显。
除了考虑decoder-only的生成模型GPT,我们也考虑了encoder-decoder的生成模型BART。下表中看出,分别在8/4/2bit的实验设置下,我们模型QuantBART在摘要任务上提升明显。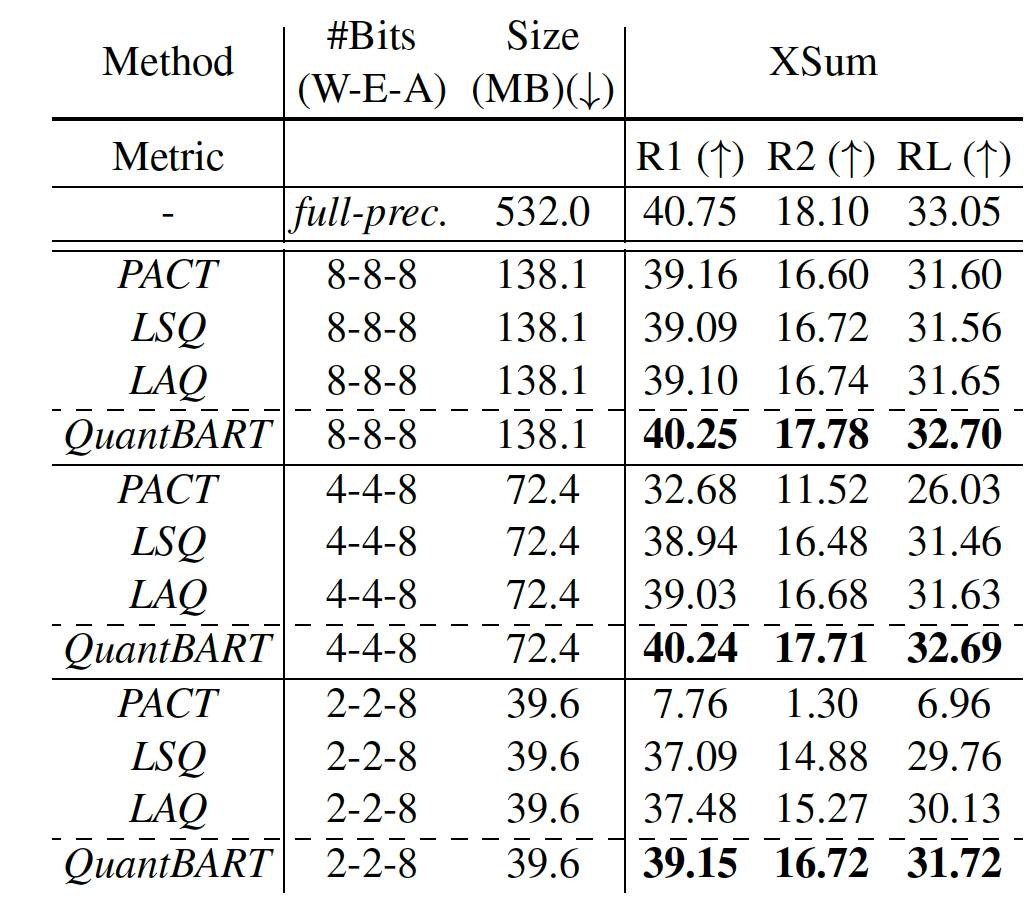
本文研究了预训练语言生成模型的低比特量化。我们发现量化生成预训练语言生成模型的困难在于同质化的词嵌入和不同模块的权重分布差异很大。为了缓解这两个问题,我们提出了令牌级对比学习来学习可区分的词嵌入,以及一个模块粒度动态缩放的量化器,以适应不同模块的权重分布。语言建模、话语理解和摘要的实验证明了我们提出的方法的有效性。
我们希望这个工作能够对生成任务的压缩有启发作用,也可以尝试把这个工作提出的量化器用在判别任务的压缩里。

点个在看 paper不断!