
时间序列预测的7种Python工具包,总有一款适合你!
时间序列问题是数据科学中最难解决的问题之一。传统的处理方法如 ARIMA、SARIMA 等,虽然是很好,但在处理具有非线性特性或非平稳时间序列问题时很难取得满意的预测效果。
为了获得更好的预测效果,并且可以简单高效的完成任务,本文中我将分享给大家7个用于处理时间序列问题的 Python 工具包。
1、tsfresh

tsfresh 是一个很棒的 python 包,它可以自动计算大量的时间序列特性,包含许多特征提取方法和强大的特征选择算法。
让我们以获取航空公司乘客的标准数据集为例,来了解tsfresh
# Importing libraries
import pandas as pd
from tsfresh import extract_features, extract_relevant_features, select_features
from tsfresh.utilities.dataframe_functions import impute, make_forecasting_frame
from tsfresh.feature_extraction import ComprehensiveFCParameters, settings
# Reading the data
data = pd.read_csv('../input/air-passengers/AirPassengers.csv')
# Some preprocessing for time component:
data.columns = ['month','Passengers']
data['month'] = pd.to_datetime(data['month'],infer_datetime_format=True,format='%y%m')
data.index = data.month
df_air = data.drop(['month'], axis = 1)
# Use Forecasting frame from tsfresh for rolling forecast training
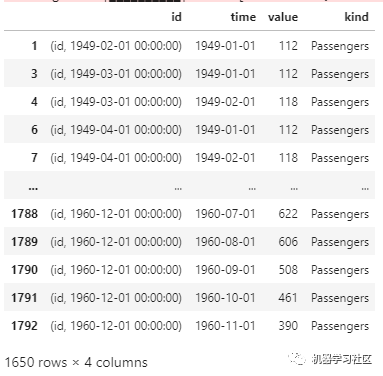
df_shift, y_air = make_forecasting_frame(df_air["Passengers"], kind="Passengers", max_timeshift=12, rolling_direction=1)
print(df_shift)
数据需要被格式化为如下格式:
# Getting Comprehensive Features
extraction_settings = ComprehensiveFCParameters()
X = extract_features(df_shift, column_id="id", column_sort="time", column_value="value", impute_function=impute,show_warnings=False,default_fc_parameters=extraction_settings)
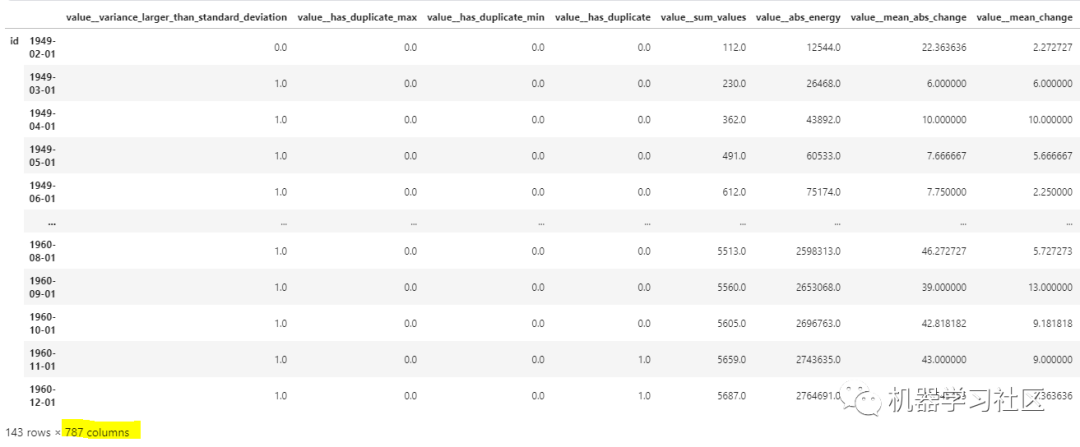 从上面的输出中,我们可以看到大约创建了800个特征。tsfresh还有助于基于p值的特征选择。更多详细信息可以查看Github:
从上面的输出中,我们可以看到大约创建了800个特征。tsfresh还有助于基于p值的特征选择。更多详细信息可以查看Github:https://github.com/blue-yonder/tsfresh官方文档 https://tsfresh.readthedocs.io/en/latest/index.html
2、autots

AutoTS 是一个自动化的时间序列预测库,可以使用简单的代码训练多个时间序列模型,此库的一些最佳功能包括:
利用遗传规划优化方法寻找最优时间序列预测模型。 提供置信区间预测值的下限和上限。 它训练各种各样的模型,如统计的,机器学习以及深度学习模型 它还可以执行最佳模型的自动集成 它还可以通过学习最优NaN插补和异常值去除来处理混乱的数据 它可以运行单变量和多变量时间序列
让我们以苹果股票数据集为例,更详细地了解一下:
# Loading the package
from autots import AutoTS
import matplotlib.pyplot as plt
import pandas as pd
# Reading the data
df = pd.read_csv('../input/apple-aapl-historical-stock-data/HistoricalQuotes.csv')
# Doing some preprocessing
def remove_dollar(x):
return x[2:]
df[' Close/Last'] = df[' Close/Last'].apply(remove_dollar)
df[' Close/Last'] = df[' Close/Last'].astype(float)
df['Date'] = pd.to_datetime(df['Date'])
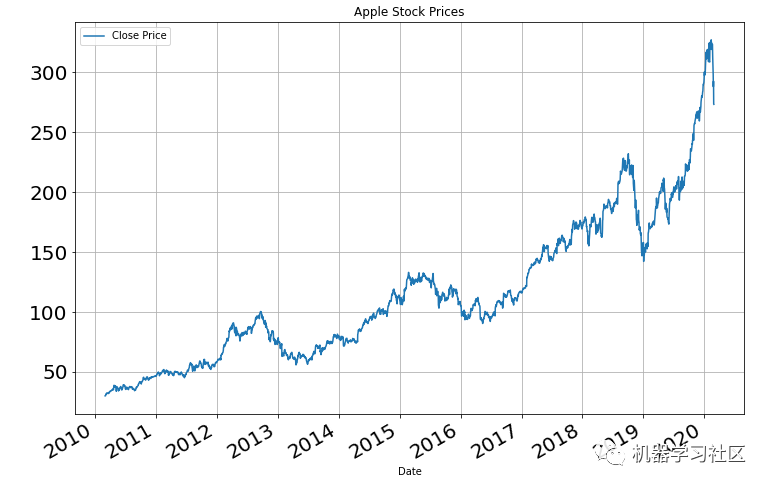
# Plot to see the data:
df = df[["Date", " Close/Last"]]
df["Date"] = pd.to_datetime(df.Date)
temp_df = df.set_index('Date')
temp_df[" Close/Last"].plot(figsize=(12, 8), title="Apple Stock Prices", fontsize=20, label="Close Price")
plt.legend()
plt.grid()
plt.show()
model = AutoTS(forecast_length=40, frequency='infer', ensemble='simple', drop_data_older_than_periods=100)
model = model.fit(df, date_col='Date', value_col=' Close/Last', id_col=None)
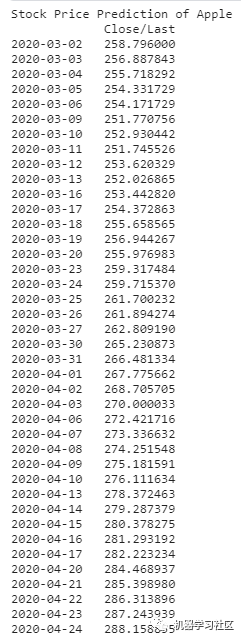
这将运行数百个模型。你将在输出窗格中看到运行的各种模型。让我们看看模型如何预测:
prediction = model.predict()
forecast = prediction.forecast
print("Stock Price Prediction of Apple")
print(forecast)
temp_df[' Close/Last'].plot(figsize=(15,8), title= 'AAPL Stock Price', fontsize=18, label='Train')
forecast[' Close/Last'].plot(figsize=(15,8), title= 'AAPL Stock Price', fontsize=18, label='Test')
plt.legend()
plt.grid()
plt.show()
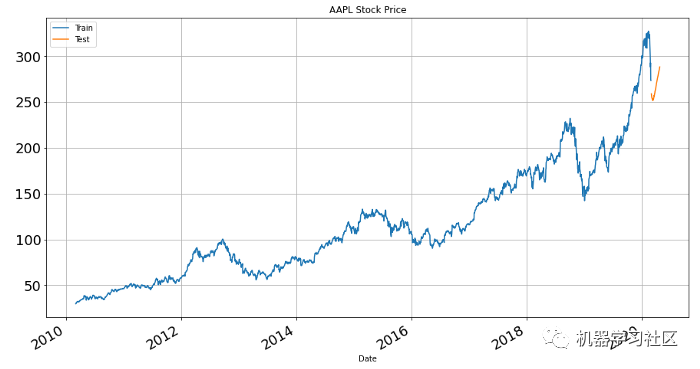 更多详细信息可以查看
更多详细信息可以查看Github: https://github.com/winedarksea/AutoTS官网文档: https://winedarksea.github.io/AutoTS/build/html/source/tutorial.html
3、Prophet
Prophet是Facebook研究团队开发的知名时间序列软件包,于2017年首次发布,适用于具有强烈季节性影响的数据和多个季节的历史数据。它具有高度的用户友好性和可定制性,只需进行最少的设置。
让我们看一个简单的例子:
# Loading the library
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
# Loading the data from the repo:
df = pd.read_csv("https://raw.githubusercontent.com/facebook/prophet/master/examples/example_wp_log_peyton_manning.csv")
# Fitting the model
model = Prophet()
model.fit(df) #fit the model.
# Predict
future = model.make_future_dataframe(periods=730) # predicting for ~ 2 years
forecast = model.predict(future) # Predict future
# Plot results
fig1 = model.plot(forecast) # Plot the fit to past data and future forcast.
fig2 = model.plot_components(forecast) # Plot breakdown of components.
plt.show()
forecast # Displaying various results in table format.
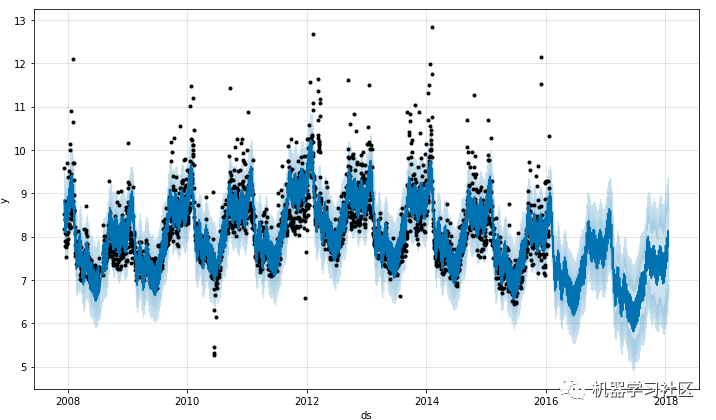 趋势图和季节性图如下所示:
趋势图和季节性图如下所示: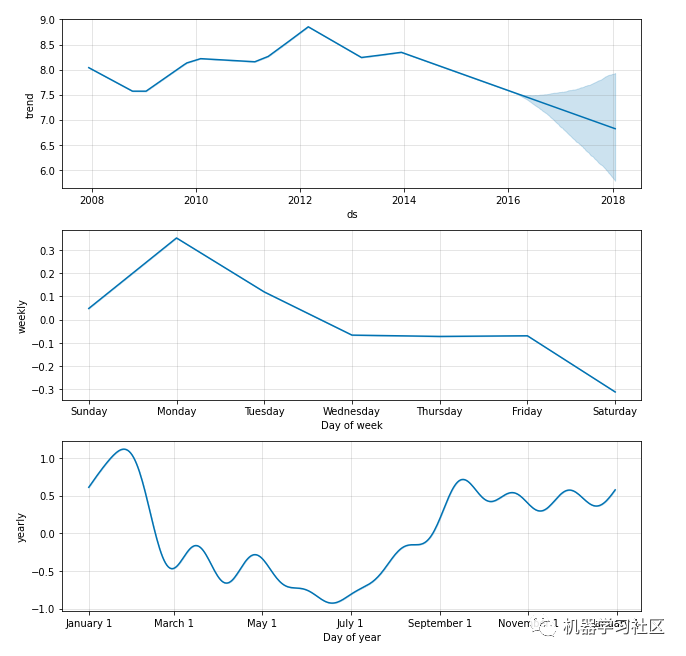 我们还可以看到预测以及所有的置信区间
我们还可以看到预测以及所有的置信区间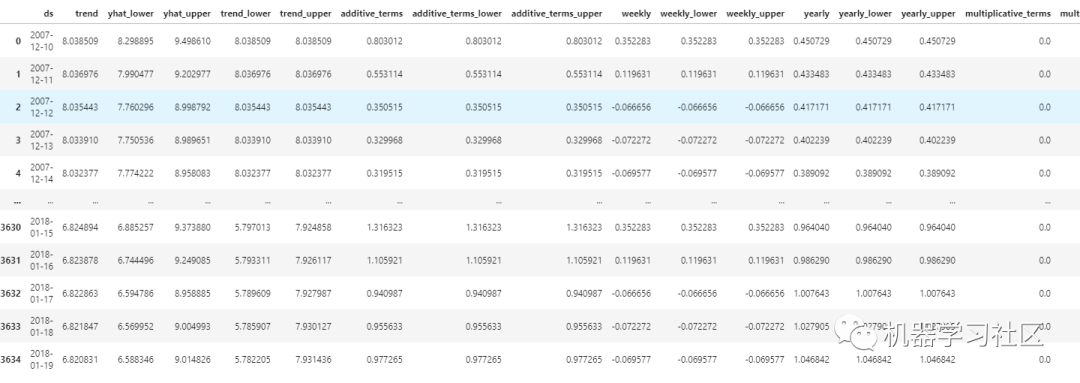 更多详细信息可以查看Github:
更多详细信息可以查看Github: https://github.com/facebook/prophet文档: https://facebook.github.io/prophet/
4、darts:
Darts 是另一个 Python 包,它有助于时间序列的操作和预测。语法是“sklearn-friendly”,使用fit和predict函数来实现目标。此外,它还包含了从 ARIMA 到神经网络的各种模型。
该软件包最好的部分是它不仅支持单变量,而且还支持多变量时间序列和模型。该库还可以方便地对模型进行回溯测试,并将多个模型的预测和外部回归组合起来。让我们举一个简单的例子来了解它的工作原理:
#Loading the package
from darts import TimeSeries
from darts.models import ExponentialSmoothing
import matplotlib.pyplot as plt
# Reading the data
data = pd.read_csv('../input/air-passengers/AirPassengers.csv')
series = TimeSeries.from_dataframe(data, 'Month', '#Passengers')
print(series)
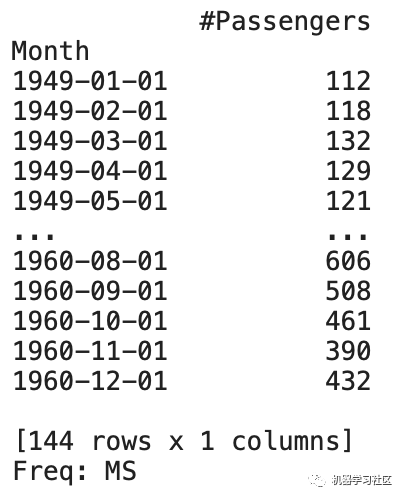
# Splitting the series in train and validation set
train, val = series.split_before(pd.Timestamp('19580101'))
# Applying a simple Exponential Smoothing model
model = ExponentialSmoothing()
model.fit(train)
# Getting and plotting the predictions
prediction = model.predict(len(val))series.plot(label='actual')
prediction.plot(label='forecast', lw=3)
plt.legend()
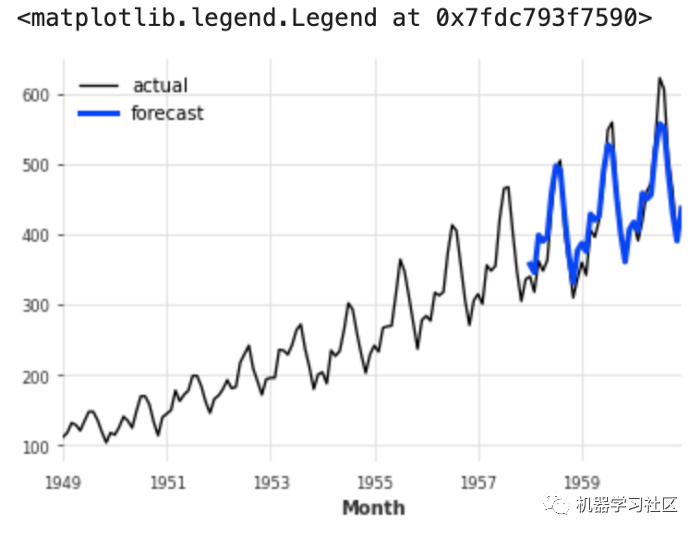
更多详细信息可以查看Github: https://github.com/unit8co/darts文档: https://unit8co.github.io/darts/README.html
5、AtsPy
AtsPy 代表Python 中的自动时间序列模型。该库的目标是预测单变量时间序列。你可以加载数据并指定要运行的模型,如下例所示:
# Importing packages
import pandas as pd
from atspy import AutomatedModel
# Reading the data:
data = pd.read_csv('../input/air-passengers/AirPassengers.csv')
# Preprocessing data
data.columns = ['month','Passengers']
data['month'] = pd.to_datetime(data['month'],infer_datetime_format=True,format='%y%m')
data.index = data.month
df_air = data.drop(['month'], axis = 1)
# Select the models you want to run:
models = ['ARIMA','Prophet']
run_models = AutomatedModel(df = df_air, model_list=models, forecast_len=10)
该软件包提供了一组完全自动化的不同模型。以下是可用型号的截图: Github:
Github: https://github.com/firmai/atspy
6、kats:
Kats 是 Facebook 研究团队最近开发的另一个专门处理时间序列数据的库。该框架的目标是为解决时间序列问题提供一个完整的解决方案。使用此库,我们可以执行以下操作:
时间序列分析 模式检测,包括季节性、异常值、趋势变化 产生65个特征的特征工程模块 对时间序列数据建立预测模型,包括Prophet、ARIMA、Holt Winters等。
它刚刚发布了第一个版本。一些教程可以在这里找到https://github.com/facebookresearch/Kats/tree/master/tutorials
7、sktime:
Sktime 库是一个统一的 python 库,它适用于时间序列数据,并且与 scikit-learn 兼容。它有时间序列预测、回归和分类模型,开发的主要目标是与 scikit-learn 进行互操作。
举个预测例子来介绍 sktime 的使用方法
from sktime.datasets import load_airline
from sktime.forecasting.base import ForecastingHorizon
from sktime.forecasting.model_selection import temporal_train_test_split
from sktime.forecasting.theta import ThetaForecaster
from sktime.performance_metrics.forecasting import mean_absolute_percentage_error
y = load_airline()
y_train, y_test = temporal_train_test_split(y)
fh = ForecastingHorizon(y_test.index, is_relative=False)
forecaster = ThetaForecaster(sp=12) # monthly seasonal periodicity
forecaster.fit(y_train)
y_pred = forecaster.predict(fh)
mean_absolute_percentage_error(y_test, y_pred)
>>> 0.08661467738190656
Github:https://github.com/alan-turing-institute/sktime
资料分享
Python 程序员深度学习的“四大名著”: 这四本书内容着实很不错,非常适合学习机器学习、深度学习方向的小伙伴!我们都知道现在这方面的资料太多了,面对海量资源,往往陷入到“无从下手”的困惑出境,而且并非所有的书籍都是优质资源,浪费大量的时间是得不偿失的。
这四本书内容着实很不错,非常适合学习机器学习、深度学习方向的小伙伴!我们都知道现在这方面的资料太多了,面对海量资源,往往陷入到“无从下手”的困惑出境,而且并非所有的书籍都是优质资源,浪费大量的时间是得不偿失的。
获得方式:
扫码或者长按下方二维码,点击右上方关注; 后台回复关键词:4books;