
AI 实战: CNN 和 RNN 联手实现让图像说话
来自 | medium.com 作者 | Krunal Kshirsagar
链接 | http://suo.im/6fIxgI
编辑 | 机器学习与数学翻译组
通过一个实例,即识别图像中的内容并生成一个描述性句子来展示如何联合使用卷积神经网络 CNN 和递归神经网络 RNN。
该任务一般使用的模型是 CNN(卷积神经网络)和 RNN(递归神经网络)这两种独立架构的组合。在这种情况下,LSTM(长短期记忆网络)是一种包含存储单元的特殊 RNN 类型单元,以便长时间记忆和保持信息。该混合模型的基本原理是: 使用 CNN 从图像中提取物体及它们的空间信息的特征向量,然后将特征向量经过全连接的线性层输入 RNN 网络中,以生成序列数据(如单词序列),最终生成对图像的描述。
01用于训练模型的数据集
由于 Udacity 已经为我们提供了 MS-COCO 数据集,它是 Microsoft Common Objects COntext 的简称。这是一个高级数据集,其中每个图像都与描述该特定图像内容的五个相关标题配对。例如,如果要求编写描述以下图片的标题,你将如何做?

首先,你观察图像并注意到不同的物体,例如不同的人和风筝以及蓝天。
然后,根据这些物体在图像中的放置方式以及它们之间的关系,你可能会认为这些人在放风筝。 他们在一个大草丛中,所以他们可能在公园里。 之后,收集这些视觉观察结果,你可以将短语描述为
人们在公园放风筝。
我们将空间观察和文字序列描述来编写标题,而这正是联合使用 CNN 和 RNN 两种不同架构网络的正确姿势。
02数据集示例

03CNN-RNN 架构
端到端,我们希望字幕模型输入图像并输出该图像的文字描述。输入图像将由 CNN 处理,并将 CNN 的输出输入给 RNN,这将使我们能够生成描述性文本。

因此,为了生成描述,我们将特定图像输入到预训练的 ResNet 类模型 CNN 中。该网络的末尾是一个 softmax 分类器,它输出类分数的向量,但我们不想对图像进行分类,而是想要一组代表图像中空间内容的特征。为了获得这种空间内容,我们将删除对图像进行分类的最后一个全连接的层,然后查看它在较早的层中提取的图像中的空间信息。
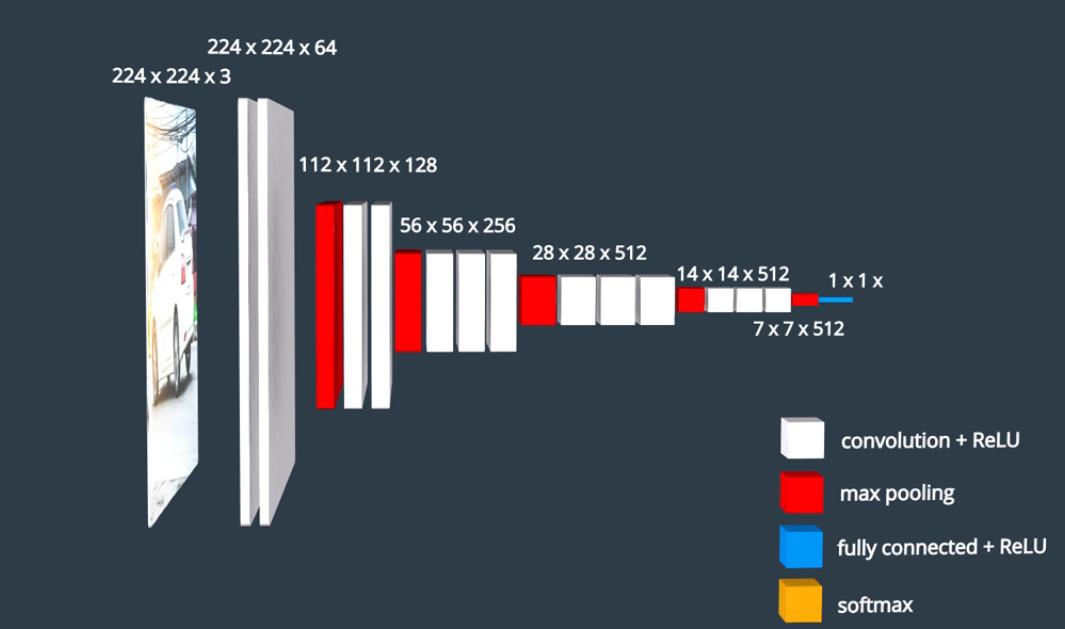
04编码器 - CNN
现在,我们将 CNN 用作特征提取器,将原始图像中包含的内容提取压缩为较小的表示形式。该 CNN 通常称为编码器,因为它会将图像的内容编码为较小的特征向量。然后,我们可以处理此特征向量,并将其用作后续 RNN 的初始输入。
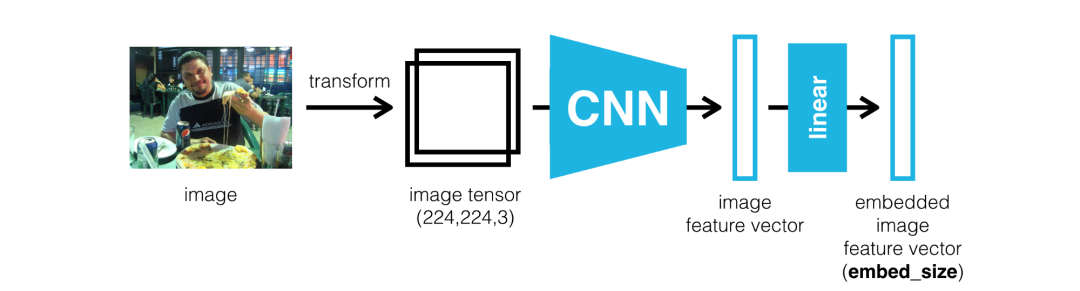
05解码器 - RNN
RNN 的工作是解码输入的特征向量并将其转换为文字序列。因此,网络的这一部分通常称为解码器。

06加载字幕/分词
字幕网络的 RNN 组件是根据 COCO 数据集中的字幕进行训练的。我们旨在训练 RNN,以根据前一个词来预测句子的下一个词。但是,如何精确地训练字符串数据呢?神经网络并不直接适用于字符串。它们需要定义明确的数值,以有效执行反向传播并学习产生相似的输出。因此,我们必须将图像字幕转换为分词列表。这种分词化处理将任何字符串变成单词列表。

07分词工作
首先,我们遍历所有训练标题,并创建一个字典,将所有唯一的单词映射到数字索引。因此,我们遇到的每个单词都会有一个对应的整数值,可以在此字典中找到。这本词典中的单词称为我们的词汇。词汇表通常还包含一些特殊标记。
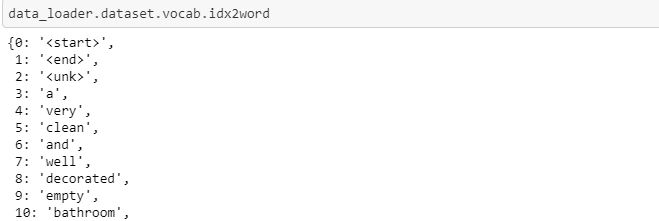

08嵌入层
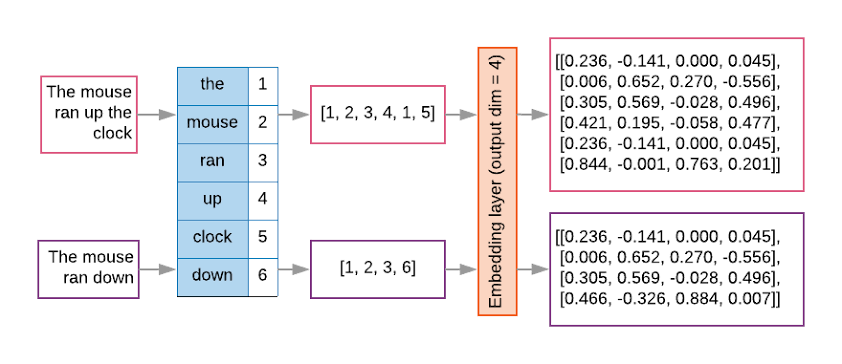
在将这些单词作为输入到 RNN 之前,还有一个步骤,那就是嵌入层,后者将标题中的每个单词转换为大小一致的向量。
09单词到向量
至此,我们知道你不能直接将单词输入 LSTM 并期望它能够训练或产生正确的输出。首先必须将这些单词转换为数字表示形式,以便网络可以使用正常的损失函数和优化器来计算预测单词和真实单词的接近程度(来自已知的训练标题)。因此,我们通常将一系列单词转换为一系列数值;数字向量,其中每个数字都映射到我们词汇表中的特定单词。
10训练 RNN 解码器模型
解码器将由 LSTM 单元组成,这有利于记住冗长的单词序列。每个 LSTM 单元期望在每个时间步长看到相同形状的输入向量。第一个单元连接到 CNN 编码器的输出特征向量。RNN 的所有未来时间步长的输入将是训练标题的各个单词。因此,在训练开始时,我们从 CNN 和初始状态的 LSTM 单元获得了一些输入。现在,RNN 承担两项职责,
记住输入特征向量中的空间信息。 预测下一个单词。
我们知道,它产生的第一个单词应该始终是
注意:如果无法获得预期的结果,请务必修改超参数。这里将超参数设置为固定的特定值。另外,请确保不要在transforms.Normalize() 中更改均值和标准差的值,因为这些值是默认值,是在对 ImageNet 数据集进行基于 ResNet 网络的训练后才确定的。

由于上述结果来自训练集,因此请在测试/验证集上测试模型以检查是否过拟合。
11预测
函数(get_prediction)用于循环测试数据集中的图像并打印模型的预测字幕。让我们来看看模型表现不错时的结果,
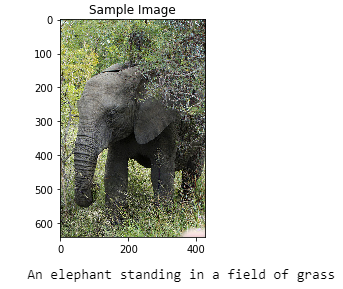
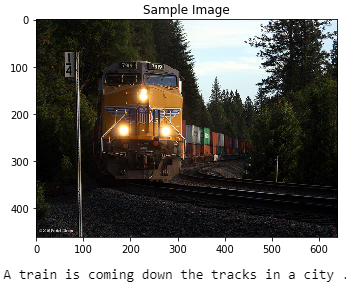
当模型表现不佳时,

显然,如你所见,如果图像上堆杂了更多物体,模型预测起来就会很困难。因此,该模型发现很难使用图像中的空间数据来生成彼此相关的长单词序列。但是,有了这些输出,我们可以判断出总有改进的余地,并且当前的模型可以升级为更好的模型。

好了,最后附上代码(见参考资料最底下),实际操练一番以加深理解。
参考资料
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention( https://arxiv.org/pdf/1502.03044.pdf) http://colah.github.io/posts/2015-08-Understanding-LSTMs/ http://blog.echen.me/2017/05/30/exploring-lstms/ http://karpathy.github.io/2015/05/21/rnn-effectiveness/ http://cs231n.stanford.edu/slides/2019/cs231n_2019_lecture10.pdf http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture11.pdf https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks https://github.com/Noob-can-Compile/Automatic-Image-Captioning/ 