
深度学习可解释性两万字综述
点击下面卡片关注,”AI算法与图像处理”
最新CV成果,火速送达
〇.前言
(为了减少小编的工作量,文中部分较为简单的公式使用上标下标的方式来呈现。如给读者阅读带来不便,作者非常抱歉。)
深度学习可解释性是目前深度学习的主流研究方向之一,更被广泛认为是下一代人工智能技术的关键一环。我们可以想象,可解释性问题一旦取得了突破,将立马对整个深度学习的科研及应用产生全局性的影响,大大促进AI在医疗、安全、国防、金融等重要领域的应用。因此,无论是做什么方面研究,方法学创新还是应用创新,对于人工智能研究者来说,关注并且了解AI可解释性方面的最新进展是十分必要的。本文以最新发表的可解释性综述(On Interpretability of Artificial Neural Networks: A Survey,https://ieeexplore.ieee.org/document/9380482)为基础,全面系统地介绍可解释性的最新进展,感兴趣的读者也可以直接访问我们的talk(https://www.youtube.com/watch?v=o6AvW0Eqc3g)。

一.介绍
1. 综述的评价和比较
毫无疑问,近几年来已经有若干篇深度学习可解释性综述出现。比如
Q. Zhang and S. C. Zhu [1] 的《Visual interpretability for deep learning: a survey》;
S. Chakraborty et al. [2]的《Interpretability of deep learning models: a survey of results》
M. Du et al. [3]的《Techniques for interpretable machine learning》;
L. H. Gilpin et al. [4]的“Explaining explanations: An overview of interpretability of machine learning》;R. Guidotti et al. [5]的《A survey of methods for explaining black box models》;
A. Adadi and M. Berrada [6]的《Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI) 》。
尽管这些综述做了很棒的工作,但是他们在全面性和细致性上仍然有相当的提升空间。Q. Zhang and S. C. Zhu的文章主要集中在视觉可解释性,比如特征可视化、热图等等。S. Chakraborty et al. 的文章全面性稍不足:作为综述,它只引用了四十几篇文章,无法反映出可解释性的全貌。L. H. Gilpin et al. 集中在事后可解释性上,即模型已经训练好了之后再去解释它,而忽略了从头打造可解释性这一重要方向。R. Guidotti et al. 和A. Adadi and M. Berrada的综述讲的是整个AI方法的可解释性,里面不止介绍神经网络,还有诸多AI模型。因此,这两个综述在神经网络上着墨相对有限,也因此遗漏了一些神经网络可解释性的重要方向,比如运用先进的数理方法来解释神经网络。相比之下,最新的这个综述《On Interpretability of Artificial Neural Networks: A Survey》同时兼顾了全面性和细致性。这篇综述总共引用了两百多篇文献,对各类方法有教学性质的介绍,同时也实现了若干代表性可解释性方法并公开了代码。
2. 可解释性的含义
尽管可解释性这个词经常用到,但是到底可解释性的含义是什么,大家的认知还是模糊的。Lipton[1]总结了可解释性的三层含义:
Simulatability: 指的是对整个模型的高层次的理解,比如一个线性分类器就是完全透明、可解释的。在九十年代的一篇Science论文[2]中,Poggio提出了径向基函数网络的解释:一个单隐含层的径向基函数网络可以是插值问题的一个解,径向基函数的形状是由一个正则项控制的。由此建立了对径向基网络的高层次理解。
Decomposability: 指的是通过了解一个网络每个组分的作用来达到理解一个模型的作用。这正是工程中常见的模块化思想。在机器学习里面,决策树的可解释性较强,从输入到输出,节点一路走下来,每一个节点和分支都有一个特定的功能,所以理解决策树就相对比较简单。
Algorithmic transparency: 指的是理解网络的训练和动态行为。
[1] Z. C. Lipton, “The mythos of model interpretability,” Queue, vol. 16, no. 3, pp. 31–57, 2018.
[2] T. Poggio and F. Girosi, “Regularization algorithms for learning that are equivalent to multilayer networks,” Science, vol. 247, no. 4945, pp. 978–982, 1990.
3. 可解释性的困难之处
(1)人类局限性(Human Limitation)。在许多情况下,人的专业知识是极度缺乏的。当我们自身都缺乏某一领域专业知识的时候,我们又该如何来理解神经网络在这一个领域的应用呢?举一个极端的例子,在Fan et al. [1]中,神经网络被用来预测伪随机事件。首先一串随机数被生成,作者将前100000位数字作为神经网络输入,100001位数字作为神经网络的输出。预测的准确度达到了3。据此作者猜想,神经网络可以用来验证上帝是否投掷色子这一物理学经典问题,因为神经网络的高度敏感性和学习能力可以来判定一串随机数是真随机还是伪随机。可以想象,对这样的网络进行可解释性的研究是非常困难的,因为随机数背后是不是隐含着物理规律(量子力学背后是否有更深刻的理论)现在世界上没有几个人搞的清楚。
(2)商业阻碍 (Commercial Barrier)[2]。首先,如果商业公司使用的是一个完全透明的神经网络模型来做应用,那么公司肯定就无法赚钱了。第二,模型的不可解释性在一定程度上可以保护公司的知识产权。如果一个模型可解释性很强,那么竞争者就有可能通过逆向工程把模型给做出来,就会损害公司的利益。第三,打造一个可解释性模型会造成额外的工作,有些工程师并不愿意这样做。
(3)数据异质化(Data Wildness)。一个真实的数据集可能包含着各种各样你想象不到的数据。比如一个医疗数据集可能包括以下数据:临床数据,分子数据,图像和生物测量信号,实验室化验结果,病患口述结果等等。此外,数据的维度也很高,一个很小的图片也能达到几百上万维。在高维空间发展可解释性比在低维空间要难的多。其实,我们对低维情形的网络运行机理已经有了相当的了解。
(4)算法复杂性(Algorithmic Complexity)。深度神经网络不仅使用各种各样的非线性组件,并且参数量还特别巨大,往往形成过参数化的情况。甚至意料之外的情况也会出现,比如,九十年代一篇论文的证明结果:RNN可能会产生混沌现象[3]。
4. 可解释性研究好坏的评价
接下来一个问题是,评估可解释性方法质量的标准是什么?由于现有的评估方法还不成熟,因此我们提出了五种通用且定义明确的经验法则:精准度,一致性,完整性,普遍性和实用性。
精准度:精准度是指解释方法的准确性。一个可解释性算法是否只限于定性描述还是存在定量分析?通常,定量解释方法比定性解释方法更为可取。
一致性:一致性表明解释中没有任何矛盾。对于多个相似的样本,好的解释应该产生一致的答案。此外,解释方法应符合真实模型的预测。例如,基于代理的方法是利用它们对原始模型的复制准确程度进行评估的。
完整性:从数学上讲,神经网络是要学习最适合数据的映射。一个好的解释方法应该显示出在最大数量的数据实例和数据类型方面的有效性,而不是只对某些数据有效。
通用性:随着深度学习的飞速发展,深度学习方法库已大大丰富。这种多样化的深度学习模型在各种任务中扮演着重要的角色。我们是否可以开发一种通用解释器,该解释器可以解释尽可能多的模型以节省人工和时间?但由于模型之间的高度可变性,通用解释器在技术上非常具有挑战性。
实用性:对神经网络的了解使我们获得了什么?除了获得从业者和用户的信任之外,可解释性的成果还可以是对网络设计,训练等的深刻见解。由于其黑盒性质,使用神经网络在很大程度上是一个反复试验的过程,有时会产生矛盾的直觉。可解释性的增强应当要帮助我们理清这些矛盾之处。
二.趋势和分类
1. 趋势
2020年9月22日,我们将搜索词“Deep Learning Interpretability”, “Neural Network Interpretability”, “Explainable Neural Network”和 “Explainable Deep Learning”输入到Web of Science中,时间范围为2000年至2019年。图1中绘制了相对于年份的文章数量的变化,该图清楚地显示了神经网络可解释性领域的指数增长趋势。
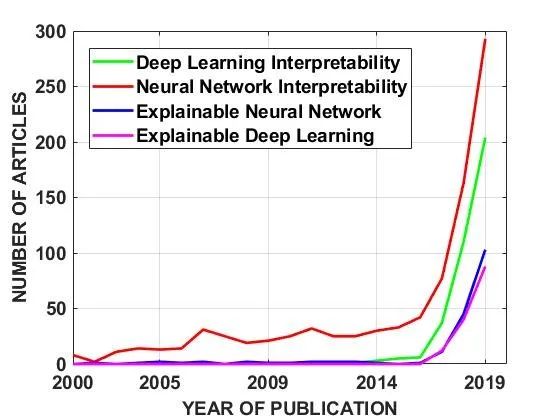
图1. 深度学习可解释性论文的指数增长趋势
2. 方法的分类
根据我们对论文的调查,我们将可解释性论文进行如下分类。
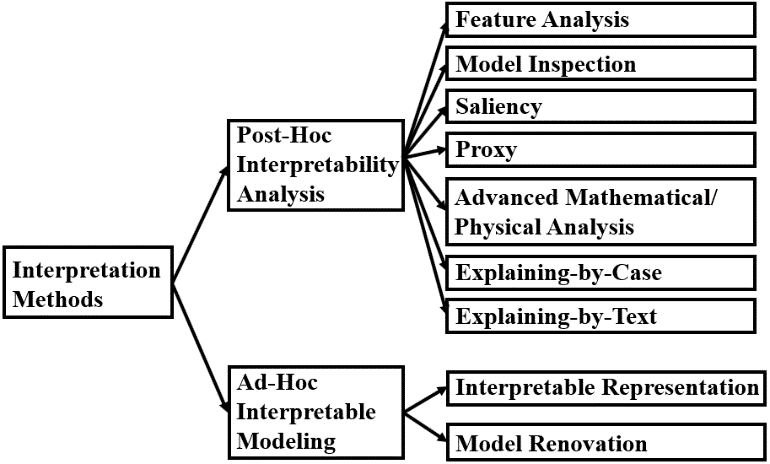
图2. 深度学习可解释性论文的分类法
具体来说:首先可以分成两大类:“事后可解释性分析”和“事前可解释性建模”。前者是模型已经训练好了,然后去解释,后者是从头设计可解释性的模型。进一步,“事后可解释性分析”可以分成七个子类:特征分析(Feature Analysis)、模型检查(Model Inspection)、显著表征(Saliency)、代理模型(Proxy)、先进数理(Advanced Math/Physics Method)、案例解释(Explaining-by-Case)、文本解释(Explaining-by-Text)。“事前可解释性建模”可以再分成可解释表示(Interpretable Representation)、模型修缮(Model Renovation)。下面我们逐个进行解释。
2.1 事后可解释性分析
事后可解释性是在充分学习模型之后进行的。事后方法的一个主要优点是,由于预测和解释是两个独立的过程而不会相互干扰,因此不需要为了追求预测性能来牺牲可解释性。但是,事后解释通常并不完全忠实于原始模型。因为如果解释与原始模型相比100%准确,那么它就跟原始模型一样了。因此,此类别中的任何解释方法或多或少都是不准确的。糟糕的是,我们常常不知道时哪里出现了细微差别,因此我们很难完全信任事后解释方法。
特征分析(Feature Analysis)技术的重点是比较、分析和可视化神经网络的神经元和层的特征。通过特征分析,可以识别敏感特征及其处理方式,从而可以在一定程度上解释模型的原理。特征分析技术可以应用于任何神经网络,并提供有关网络学习了哪些特征的定性见解。但是,这些技术缺乏深入,严格和统一的理解,因此很难用来反馈提高神经网络的可解释性。
模型检查(Model Inspection)方法使用外部算法,通过系统地提取神经网络内部工作机制的重要结构和参数信息,来深入研究神经网络。与定性分析相比,此类中的方法在技术上更具可靠性,比如统计分析工具介入到了对模型的分析。通过模型检查方法获得的信息更值得信赖和也更有用。在一个研究中[1],研究人员发现了重要的数据路由路径。使用这种数据路由路径,可以将模型准确地压缩为紧凑的模型。
显著表征(Saliency)方法确定输入数据的哪些属性与模型的预测或潜在表示最相关。在此类别中,需要进行人工检查来确定显著性图是否合理。在大多数情况下,显著性图很有用。例如,如果北极熊总是与雪或冰出现在同一张图片中,则该模型可能会选择用雪或冰的信息来检测北极熊,而不是使用了北极熊的真实特征。使用显著性图,我们就可以发现并避免此问题。显著性方法在可解释性研究中很流行,但是,大量随机测试显示,某些显著性方法可以独立于模型且不依赖于数据[2],即某些方法提供的显著性图与边缘检测器产生的结果高度相似。这是有问题的,因为这意味着那些显著性方法无法找到解释模型预测的输入的真实属性。在这种情况下,应开发与模型相关和与数据相关的显著性方法。
代理模型(Proxy)方法构造了一个更简单,更易解释的代理模型。理想情况下,它与经过训练的,大型,复杂和黑盒子的深度学习模型非常相似。代理方法可以是部分空间中的局部方法,也可以是整个空间中的全局方法。经常使用的代理模型包括决策树,规则系统等。代理方法的弱点是构建代理模型需要付出额外成本。
先进数理(Advanced Math/Physics Method)将神经网络置于数学/物理框架中,便可以使用高级的数学/物理工具来了解神经网络的机制。此类别涵盖了深度学习的理论进展,包括非凸优化,表示能力和泛化能力。本类别中的方法可能会出现一种情况:为了建立合理的解释,有时会做出不切实际的假设以促进理论分析。
案例解释(Explaining-by-Case)方法与基于案例的推理相似[3]。人们喜欢例子。一个人可能不会沉迷于产品的统计数字,但会喜欢看其他用户使用该产品的经验。基于案例的深度学习解释也是这样的想法。个案解释方法提供了具有代表性的示例,这些示例捕获了模型的特质。此类中的方法有趣且启发人心。但是,这种做法更像是一种健全性检查,而不是一般性的解释,因为从选定的查询案例中了解的关于神经网络内部工作的信息不多。
文本解释(Explaining-by-Text)方法在图像语言联合任务中生成文本描述,这非常有助于理解模型的行为。此类也可以包括生成用于解释的符号的方法。此类中的方法在图像语言联合任务(例如从X射线射线照片生成诊断报告)中特别有用。但是,文本解释不是通用的技术,因为它只有在模型中存在语言模块时才能起作用。
2.2 事前可解释的建模
事前可解释模型可以避免事后可解释性分析中的偏见。尽管通常认为在可解释性和模型可表达性之间存在权衡,但仍然有可能找到功能强大且可解释的模型。一个例子是在[4]中报道的工作,其中可解释的两层加性风险模型在FICO识别竞赛中获得了第一名。最近,伯克利马毅老师基于数据压缩和预测的思想自动构建出一个网络,是这类方法的一个标志性工作。
可解释表示(Interpretable Representation)方法采用正则化技术将神经网络的训练引向更具解释性的表示。诸如可分解性,稀疏性和单调性之类的属性可以增强可解释性。但是,为了可解释性,损失函数必须包含正则项,这可能限制了原始模型执行其完整的学习任务。
模型修缮(Model Renovation)方法通过将更多可解释的组件设计和部署来寻求可解释性。这些组件包括具有专门设计的激活功能的神经元,具有特殊功能的插入层,模块化体系结构等。未来的方向是使用越来越多的可解释组件,这些组件可以同时为各种任务提供类似的先进性能。
三.事后可解释性分析
1. 特征分析
基于invert的方法[1-4]通过将特征图invert为一个合成的图像来破解神经网络。例如,A.Mahendran和A. Vedaldi [2] 假设输入图像为x_0,对应的神经网络Ω_0的表示为Ω_0=Ω(x_0),其中Ω是神经网络映射,通常不可逆。然后,invert问题被建模成一个优化问题:
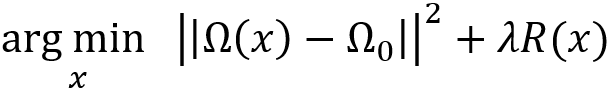
即寻找一个图像,该图像的神经网络表示与x_0的神经网络表示最匹配。R(x)是表示有关输入图像的先验知识的正则化项。invert出来图像之后,我们可以通过比较得到的图像和原始图像之间的差异来揭示神经网络丢失的信息。Dosovitskiy [1]直接训练了一个新网络,将感兴趣模型生成的中间层特征作为输入,将图像作为标签。这样学到的网络可以将中间层的特征转化为图像。他们发现即使从很深的层产生的特征中,轮廓和颜色等信息仍然可以重构出来。M.D.Zeiler [4]设计了一个由反卷积+反池化+ReLU操作组成的反向网络,与原始卷积网络配对,从而无需训练就可以直接反转出特征。在反卷积网络中,通过标记最大值的位置来实现反池化,反卷积层使用转置卷积。
激活最大化方法[5-8]致力于合成使神经网络整体或者对某个感兴趣的神经元的输出响应最大化的图像。生成的图像称为“deep dream”,因为这些图像往往比较抽象,具有梦境般的视觉效果。
在[9],[10],[11],[12],[13]中指出,可以从每个神经元中提取有关深度模型的信息。J.Yosinski等[12]直接检查了不同图像或视频的每一层神经元的激活值。他们发现,针对不同输入而变化的实时神经元激活值有助于理解模型的工作方式。Y. Li 等[11]比较了不同初始化生成的特征,以研究神经网络在随机初始化时是否学习了相似的表示。感受野(Receptive Field, RF)是神经元与输入[14]连接的空间范围。为了研究神经元给定输入的RF的大小和形状,B. Zhou等 [13]提出了一种网络解剖方法,该方法首先为感兴趣的神经元选择具有高激活值的K个图像,然后通过遮挡图像的局部为每个图像构建5,000个遮挡图像,然后将它们输入到神经网络中,以观察针对一个神经元的激活值的变化。产生较大的差异代表被遮挡的块儿是重要的。最后,将具有较大差异的遮挡图像集中并进行平均以生成RF。此外,D. Bau等人 [15]将给定层的低分辨率激活图放大到与输入相同的大小,将该图阈值截断为二进制激活图,然后计算二进制激活图和ground truth二进制分割之间的重叠区域,作为可解释性度量。A. Karpathy等 [10]将LSTM 中的门定义为左饱和或右饱和,具体取决于其激活值是小于0.1还是大于0.9。在这方面,经常右饱和的神经元意味着这些神经元可以长时间记住其值。Q.Zhang等 [16]假定较底层中的部件图案可以来激活下一层中的卷积核。他们逐层挖掘零件图案,从每一层的特征图中发现前一层的部件图案的激活峰,并构造了一个解释性的graph来描述层与层特征的关系,其中每个节点代表一个部件图案,相邻层之间的边代表一个激活关系。
2. 模型检查
P. W. Koh和P. Liang [1]应用影响函数的概念来解决以下问题:给定一个样本的预测,数据集中的其他样本对该预测有正面影响还是负面影响?该分析还可以帮助识别数据中存在错误注释的标签和异常值。如图3所示,给定类似LeNet-5的网络,通过影响函数可以识别给定图像的两个有害图像。

图 3. 根据影响函数,两个对测试图像有害的样本在数据集中被找到
[2] [3]和 [4]致力于神经网络中故障或偏差的检测。例如,A.Bansal等人 [2]开发了一种通用算法,以识别那些神经网络可能无法为其提供任何预测的实例。在这种情况下,该模型将发出“不要信任我的预测”之类的警告而不是给予一个预测。具体来说,他们使用一系列属性特征来注释所有失败的图像,并将这些图像聚类。结果,每个类指示一种故障模式。为了有效地识别那些在数据集中具有较高预测分数的标签错误的实例,H. Lakkaraju等 [3]引入了两个基本的推测:第一个推测是高可信度地错误标记实例是由于系统的偏见而不是随机扰动,第二个推测则是每个失败的实例都具有代表性和信息量。然后,他们将图像分为几组,并设计搜索策略来搜索失败实例。为了发现偏见,Q. Zhang等[4]根据人类的常识(火对应热与冰对应冷)利用属性之间的真实关系来检查神经网络所挖掘出的属性关系是否完全符合真实。
Y. Wang等 [5]通过识别关键数据链路理解网络。具体而言,将门控制二进制矢量λ_k∈{0,1} ^(n_k)与第k层的输出相乘,其中n_k是第k层中神经元的数量。控制门的开闭则可识别关键链路,数学化为搜索λ_1,…,λ_K:
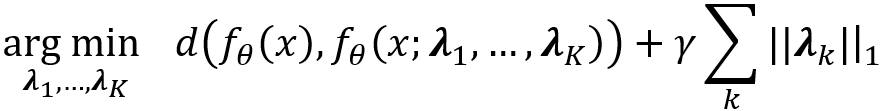
其中f_θ是由用θ参数化的神经网络表示的映射,f_θ(x; λ_1,...,λ_K)是强制执行控制门λ_1,...,λ_K时的映射,d(⋅,⋅)是距离度量,γ是一个常数,控制损失和正则化之间的折衷,||⋅|| _1是l_1范数,使得λ_k稀疏。学习的控制门将会暴露模型的重要数据处理路径。B.Kim等 [6]提出了概念激活向量(CAV),它可以定量地测量概念C对网络任何层的敏感性。首先,训练二元线性分类器h来区分两组样本刺激的层激活:{f_l(x):x∈P_C}和{f_l(x):x∉P_C},其中f_l(x)是在第l层激活层,P_C表示包含概念C的数据。然后,将CAV定义为线性分类器超平面的法向单位矢量v_C ^ l,该分类器分类具有和不具有定义概念的样本。最后,使用v_C ^ l来计算第l层中作为方向导数的概念C的敏感度:
其中h_(l,k)表示针对输出类别k的训练后的二分类线性分类器的输出。J.You等[7]将神经网络映射成关系图,然后通过大量实验研究神经网络的图结构与其预测性能之间的关系(将图转录成网络并在数据集上实现该网络)。他们发现网络的预测性能与两个图形度量相关:聚类系数和平均路径长度。这项研究的潜力在于,以后进行网络设计时就无需每种网络都要跑一次,大大节省时间,不过这个论文也有缺点,就是他们找到的度量不是单调的,这样会给使用带来麻烦。
3. 显著表征
有很多方法可以获取显著性图。部分依赖图(Partial Dependence Plot, PDP)和个体条件期望(Individual Conditional Expectation, ICE)[1],[2],[3]是使用比较广泛的统计工具,用于可视化负责任变量和预测变量之间的依赖关系。为了计算PDP,假设有p个输入维,并且S,C⊆{1,2,.. p}是两个互补集,其中S是将要固定的集合,而C是将要改变的集合。然后,通过f_S =∫f(x_S,x_C)dx_C定义x_S的PDP,其中f是模型。与PDP相比,ICE的定义很简单。通过固定x_C并更改x_S可获得x_S处的ICE曲线。图4是一个简单的示例,分别说明如何计算PDP和ICE。
还有一种简单的方法也就是各种学科都会用到的控制变量法。即删除一个特征看模型的变化[4-8]。这个变化是删除变量产生的,那么自然可以反应这个变量的作用。P.Adler[4]提出应考虑输入的间接影响。例如,在房屋贷款决策系统中,种族不应成为决策的因素。但是,仅消除种族因素不足以排除种族的影响,因为一些剩余的因素例如“邮政编码”与种族高度相关(邮编对应居住区域,黑人区,白人区泾渭分明)。
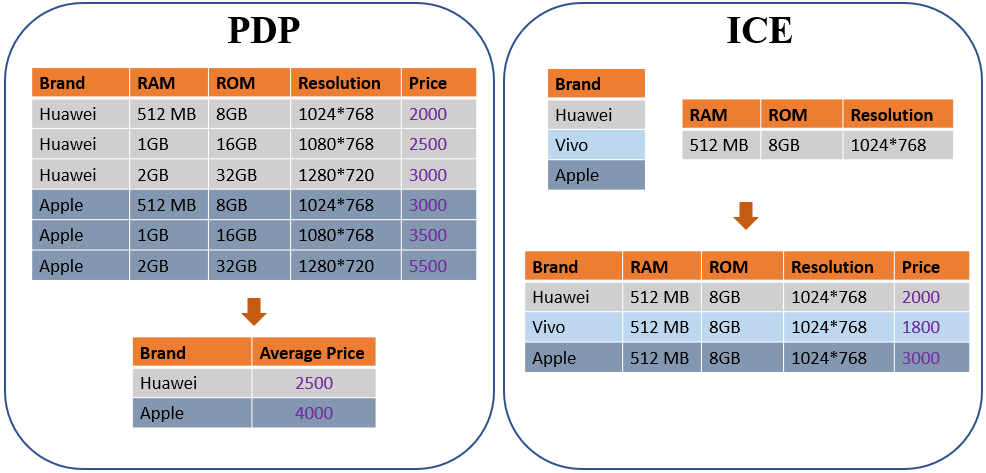
图 4. 一个简单的例子解释PDP 和 ICE. 左边:为了计算PDP,固定感兴趣的变量,让剩余的变量变化然后求平均。右边为了计算ICE,让感兴趣的变量直接动
此外,[9-13]中使用了合作博弈的Shapley值。在数学上,相对于特征i的设定函数f ̂的Shapley值定义为:
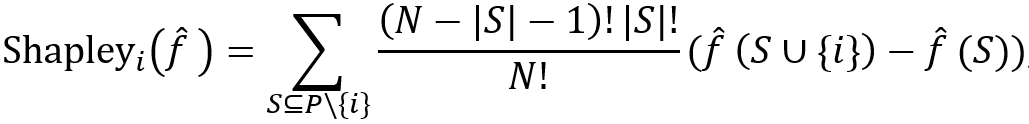
其中|⋅|是集合的大小,P是N个玩家的总玩家集合,并且集合函数f ̂ 将每个子集S⊆P映射为实数。可以看出shapley value不止局限于去除一个变量,它运用了其它变量之间的联合,因此计算出的变量i的重要性更全面。此外,可以通过用零值替换输入中不在S中的特征,将Shapley值的定义从一个集合函数拓展到神经网络函数f。M. Ancona等人 [6] 为了减少组合爆炸引起的过高的计算成本提出了一种新颖的Shapley值的多项式时间逼近方法,该方法基本上计算了一个随机联合的期望值,而不是枚举每个联合,这样就降低了shapley value计算的复杂性。图5显示了一个简单示例,说明如何为在一个住房数据集上训练的全连接层网络计算Shapley值,该网络包括八个属性,例如房屋年龄和房间号作为输入,房屋价格作为标签。
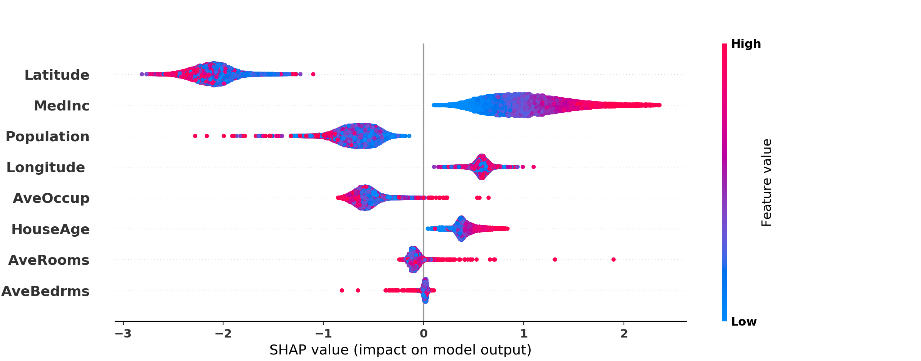
图5. 正的shapley value值代表正面影响,这里shapley value告诉我们模型可能有异常,因为房屋越老,价格越高,这违反常识
除了直接去除一个或多个特征,借助于梯度也是一个好办法。K.Simonyan等[14],D.Smilkov等 [15],M. Sundararajan等[16]和S. Singla等 [17]利用梯度的思想来探究输入的显著性。K.Simonyan等[14]直接计算了类别得分相对于图像像素的梯度,由此产生了一个类别的显著性图。D.Smilkov等 [15]发现梯度作为显著度图噪声很大。为了消除噪声,他们提出了“ SmoothGrad”,模型将噪声多次添加到输入图像中,并对得到的梯度图进行平均:
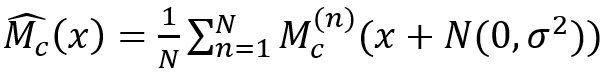
其中M_c^((n))是类别c的梯度图,N(0,σ^ 2)是具有σ的高斯噪声作为标准方差。基本上(M_c ) ̂(x)是显著度图的平滑版本。M. Sundararajan等[16]为显著性方法设定了两个基本要求:(敏感度)如果输入和baseline之间只有一个特征不同,并且输入和baseline的输出不同,则该特征应被归功于显著性;(实现不变性)在两个功能上等效的网络中,同一功能的属性应相同。M. Sundararajan等注意到较早的基于梯度的显著性方法未能满足上述两个要求,他们提出了积分梯度符合上面两个条件,公式为:
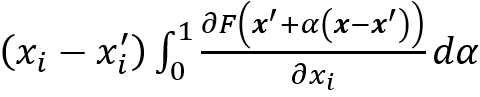
其中F(⋅)是神经网络映射,x =(x_1,x_2,…,x_N)是输入,x^'=(x_1^',x_2^',…,x_N^') 是满足:
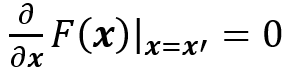
的baseline。实际中,他们将积分转换为离散求和其中M是逼近积分的步数。S.Singla等 [17]提出使用泰勒展开式的二阶近似来产生显著性图。G.Montavon等[20]使用泰勒分解的整个一阶项来产生显著性图,而不仅仅是梯度。假设 x ̂ 是模型函数f(x)事先选好的根f(x ̂ )=0,因为f(x)可以分解为:
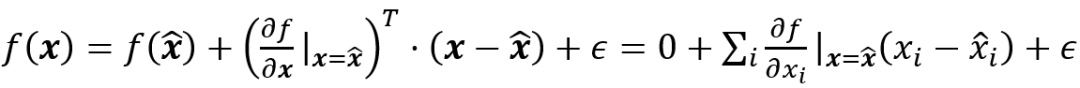
中ϵ为高阶项,与像素i相关的像素相关性表示为:
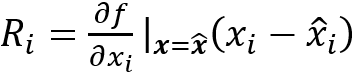
S.Bach等 [18]提出了层级相关性传播(LRP)。假设模型输出f(x)在每一层都可以表示为相关性之和。对于输入层来说,就是输入图像的像素级相关性。在最后一层:
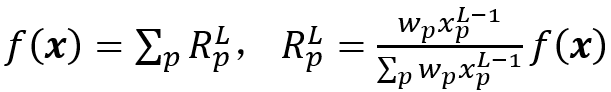
其中L是最后一层,w_p是第(L-1)层的像素p与最终层之间的权重。然后需要定义相关性的传播关系,给定前馈神经网络,我们定义:
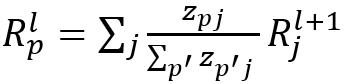
其中
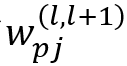
是第l层像素p之间的权重(l + 1)^层的像素j。此外,L. Arras等 [19]将LRP扩展到递归神经网络(RNN)以进行情感分析。A. Shrikumar等[21]发现,即使神经元没有被激活,它仍然有可能揭示有用的信息。因此他们提出了DeepLIFT来计算每个神经元的激活与其参考值之间的差异,其中参考值是当网络被提供参考输入时该神经元的激活,然后将该差异逐层反向传播到图像空间。C. Singh等 [22]引入了上下文分解,其层传播公式为
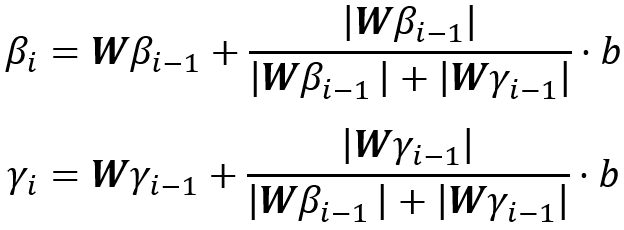
其中W是第i个之间的权重矩阵第i和i-1层,b是偏差向量。β_i(x)被视为输入的上下文贡献,而γ_i(x)表示非上下文输入对g_i(x)的贡献。仅仅凭借上面两个公式是没法解的,还需有限制条件。限制条件是g_i(x)=β_i(x)+γ_i(x),即β_i(x)和γ_i(x)加在一起等于网络的层的输出。

图6.展示了使用类似LeNet-5的网络对原始梯度,SmoothGrad,IntegratedGrad和Deep Taylor方法的评估。其中,IntegratedGrad和Deep Taylor方法在5位数字上表现出色
一些其它的方式也可以来得到显著度图。比如使用模型的输入和输出之间的关联的互信息度 [23-25]。此外,T. Lei等 [28]利用生成器来产生能代表原始文本的重要片段,这些片段满足两个条件:1)片段应足以替代原始文本;2)片段应简短而连贯。类似的,求解片段实际上等效于求解一个mask,可以将mask视为显著性图。基于以上两个约束,掩码的惩罚项可表示为:
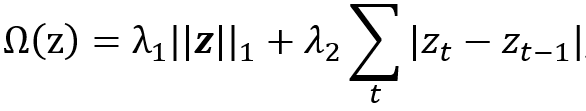
其中z=[z_1,z_2,…]是一个掩码,第一项控制片段的数量,第二项控制片段的平滑。
类激活图(CAM)方法及其变体 [30-31]在全连接层之前使用全局平均池来导出判别区域。具体来说, 假设 f_k (x,y) 表示第k个特征图, 给定类别c,那么softmax层的输入是:
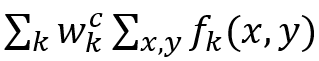
其中 w_k^c 是连接第 k^th 特征图和类别 c的权重向量。区分区域为:
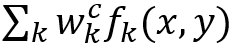
这直接暗示了(x,y)处的像素对于类别c的重要性。此外,还有一些弱监督学习方法,例如M. Oquab等[32]也可以得到判别区域。具体来说,他们只用对象标签训练网络,但是,当他们重新缩放最大池化层生成的特征图时,令人惊讶地发现这些特征图与输入中对象的位置一致。
4. 代理模型
代理方法可以分成三类。第一类是直接提取。直接提取的思想是直接从训练后的模型中构建新的可解释模型,例如决策树[1-2]或基于规则的系统。就提取规则而言,可以使用decompositional方法[3]和pedagogical方法[4-5]。pedagogical方法提取与神经网络具有相似输入输出关系的规则体系。这些规则与网络的权重和结构并不直接对应。例如,有效性间隔分析(VIA)[6]提取以下形式的规则:
IF(输入∈某个范围),THEN输入属于某个类。
R. Setiono和H. Liu [3]基于激活值的接近度,对隐藏的单元激活值进行了聚类。然后,每个聚类簇的激活值由它们的平均激活值代替,在此过程中,应选择合适的聚类类别数目来尽可能保持神经网络的准确性。接下来,将具有相同平均隐藏单元激活值的输入数据联合考虑,这些数据的边界可以帮助我们建立规则集。在图7中,我们说明了在Iris数据集上使用R. Setiono和H. Liu的方法从一个隐藏层网络中获得的规则。
在用于二分类问题的神经网络中,决策边界将输入空间分为两部分,分别对应于两个类别。E.W. Saad等人提出HYPINV方法[7]先用片段连续的决策边界来计算决策曲线,然后为每个决策边界超平面片段计算一个切向量。输入实例与切向量之间的内积符号将暗示输入实例位于边界的哪一册。基于这些内积,我们可以建立一套规则系统。
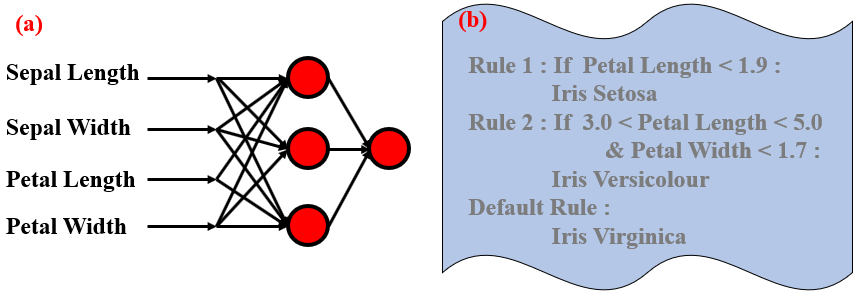
图 7. 从网络中提取规则
最后,一些专门的网络,例如ANFIS [8]和RBF网络[9],直接对应于模糊规则系统。例如,RBF网络等效于Takagi-Sugeno规则系统[10]。论文[11]中将网络中的每个神经元视为一个广义模糊逻辑门。在这种观点下,神经网络不过是一个深层的模糊逻辑系统。具体来说,他们分析了一种称为二次网络的新型神经网络,其中所有神经元都是用二次运算代替内积的二次神经元[12]。他们用广义化的模糊逻辑来解释二次神经元。
第二类方法称为知识蒸馏[13],如图8所示。尽管知识蒸馏技术主要用于模型压缩,但其原理也可以用于可解释性。知识蒸馏的核心思想是,复杂的模型可以生成相对准确的预测,将概率分配给所有可能的类别(称为软标签),这些类别可以比one-hot标签提供更多信息。例如,一匹马更有可能被归类为狗而不是山。但是,使用one-hot标签,狗类和山类的概率都为零。[13]表明原始大模型的泛化能力可以转移到一个更简单的模型中。沿着这个方向,我们可以用知识蒸馏的方法开发可解释的代理模型,例如决策树[14-15],决策集[16],全局加性模型[17]和更简单的网络[18]。例如,S.Tan等[17]使用软标签训练形式为:
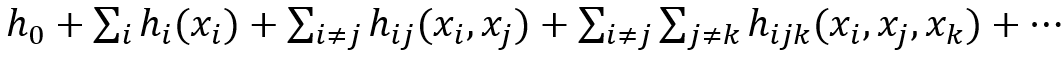
的全局加性模型,其中{h_i }_(i≥1)可直接用作特征显著性。
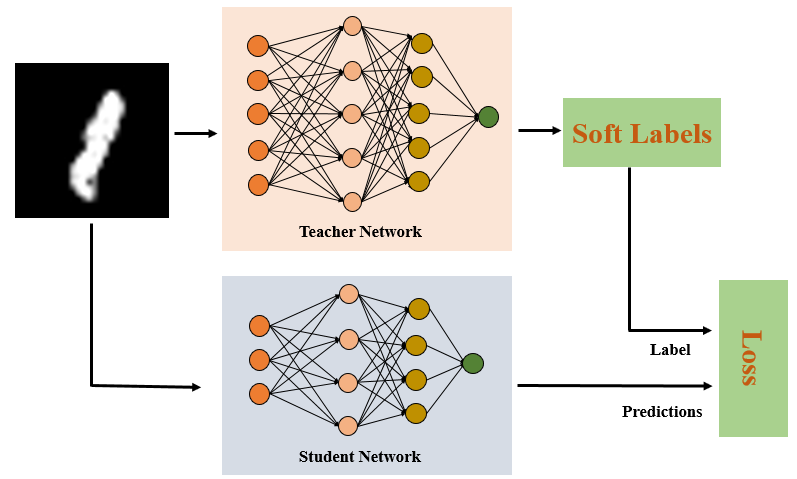
图 8. 由原始模型产生软标签,软标签比one-hot标签更有信息量
最后一类是构造一个local的模型作为代理。local解释器方法局部地模拟神经网络的预测行为。基本原理是,当从全局来看一个神经网络时,它看起来很复杂。但是如果局部的看一个神经网络的话就会简单。Local解释器的代表性方法是LIME[19],它通过将某些样本元素随机设置为零来合成许多邻居然后计算这些邻居相应的输出。最后,使用线性回归器来拟合这些实例的输入输出关系。这个线性回归器可以在局部模仿神经网络。线性模型的系数表示特征的贡献。如图9所示,LIME方法应用于乳腺癌分类模型,以识别哪些属性对模型的良性或恶性预测有贡献。

图9. 使用LIME来解释一个乳腺癌分类模型
后续有方法来改进LIME。Y.Zhang等 [20]指出了LIME解释中缺乏鲁棒性的原因,这源于采样方差,对参数选择的敏感性以及不同数据点之间的变化。Anchor[21]是LIME的改进扩展,它可以找到输入中最重要的部分,那么其余部分的变化就无关紧要,然后就可以只根据重要部分来生成邻居。数学上,Anchor搜索一个集合:A = {z | f(z)= f(x),z∈x},其中f(⋅)是模型,x是输入,z是x的子集。另一项建议是基于[22]的基于局部规则的解释(LORE)。LORE利用遗传算法来平衡的生成邻居而不是随机的生成邻居,从而产生减轻LIME的采样方差。
5. 先进数理
Y. Lu等[1]表明,许多残差网络可以解释为常微分方程的离散数值解,即ResNet [2]中残差块的内部工作可以建模为u_(n+1)=u_n+f(u_n ), 其中u_n是第n个块的输出,而f(u_n)是对于u_n的操作。注意,u_(n+1)=u_n+f(u_n )是常微分方程du/dt=f(u)的单步有限差分近似。[1]这个想法启发了ODE-Net [3]的发明。如图10所示,通过ODE-Net调整起点和动力学以拟合螺旋。
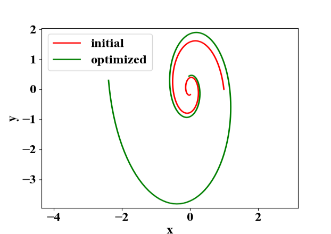
图 10. ODE-Net 优化起点和微分方程去拟合螺旋曲线
N. Lei等[4]在Wasserstein生成对抗网络(WGAN [5])和最佳运输理论之间建立了一种漂亮的联系。他们得出结论,在低维假设和特殊设计的距离函数的情况下,生成器和鉴别器可以精确地用闭式解彼此表示。因此,在WGAN中进行鉴别器和生成器之间的竞争不是必要的。
[6]刻画了神经网络中间层和网络输出之间互信息的大小关系。越深的层与输出之间互信息越少:
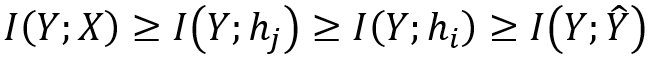
其中I(⋅;⋅)表示互信息,h_i,h_j是隐藏层的输出(i> j表示第i层更深),而Y ̂是最终预测。此外,S. Yu和J. C. Principe [7]使用信息瓶颈理论来衡量自编码器中对称层的互信息大小关系,如图11所示。
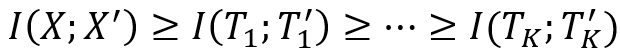
然而,估计互信息比较困难,因为我们通常不知道数据的先验概率分布。
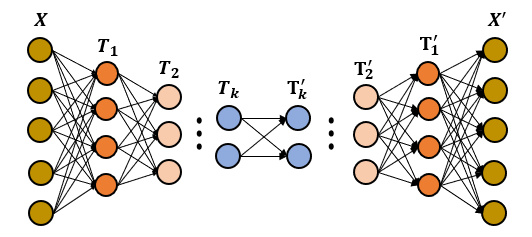
图 11: 自编码器对称层的互信息
S.Kolouri等[8]使用广义Radon变换建立了神经网络的整体几何解释。令X为输入的随机变量,其符合分布p_X,则我们可以得出参数为θ的神经网络f_θ (X)的输出的概率分布函数:
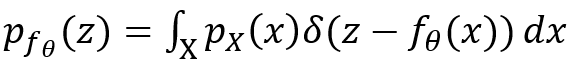
是广义Radon变换,超曲面为:
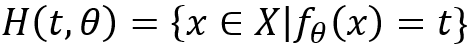
在这个框架下,神经网络的变换的特征在于扭曲超表面重新塑造输出的概率分布。H. Huang [9]使用平均场理论来描述深度网络的降维机制,该网络假定每一层的权重和数据服从高斯分布。在他的研究中,将第l层输出的自协方差矩阵计算为C^l,然后将固有维数定义为:
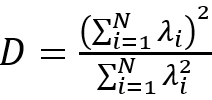
其中λ_i是C^l的特征值,N是特征值的数目。这样,我们可以用D / N来分析神经网络中每一层学到的表示是否紧凑。J.C. Ye等 [10]利用低秩Hankel矩阵解释卷积自编码器中卷积和广义池化操作。但是,在他们的研究中,他们简化了网络结构,将两个ReLU单元串联为一个线性单元,从而避免ReLU单元的非线性。
理论神经网络研究对于可解释性也是必不可少的。当前,深度学习的理论基础主要来自三个方面:表达能力,优化和泛化。
表达能力:让我们在这里举两个例子。第一个例子是解释为什么深层网络优于浅层网络。受到深层网络成功的启发,L.Szymanski和B. McCane [11],D.Rolnick和M. Tegmark [12],N.Cohen等。[13],H.N. Mhaskar和T. Poggio [14],R。Eldan和O. Shamir [15],以及S. Liang和R. Srikant [16]证明深层网络比浅层网络更具表现力。基本思想是构造一类特殊的函数,这些函数可以有效地由深层网络来表示,而很难由浅层网络来近似。第二个示例是了解深度网络的shortcut连接为什么可以表现好。A. Veit等[17]表明,ResNet的shortcut连接可以使ResNet表现出类似于集成学习的行为。沿着这个方向,[18]证明,有了shortcut连接,窄的神经网络就可以进行通用逼近。
优化:深度网络的优化是非凸优化问题。我们特别感兴趣的是为什么过度参数化的网络仍然可以很好地进行优化,因为深度网络是一种过度参数化的网络。过度参数化网络指的是网络中的参数数量超过了数据的数量。M.Soltanolkotabi等 [21]表明,当数据是高斯分布并且神经元的激活函数是二次函数时,超参数化的单层网络允许有效地搜索全局最优值。Q. Nguyen和M. Hein [22]证明,对于线性可分离数据,在前馈神经网络权重矩阵rank的限制下,损失函数的每个导数为零的点都是全局最小值。此外,A.Jacot等人[23]表明,当神经网络的每一层中的神经元数量变得无限大时,训练只会使网络函数发生很小的变化。结果,网络的训练变成了kernel ridge regression。
泛化:传统的泛化理论无法解释为何深度网络有如此多的参数,仍然可以很好地泛化。最近提出的依赖于权重矩阵范数的泛化界[24]部分解决了这个问题,即泛化界不是依赖于网络的参数个数而是每一层矩阵的矩阵范数大小。但是,目前导出的泛化界也有很大问题:比如数据越多泛化界越大,这显然与常识相矛盾。NeurIPS2019年新风向奖也给予了这方面的研究。显然,我们需要更多的努力才能理解神经网络的泛化难题[25],[26]。
6. 案例解释
案例解释是提供一个案例,该案例被神经网络认为与需要解释的例子最相似。找到一个相似的案例进行解释和从数据中选择一个具有代表性的案例作为原型[1]基本上是同一件事,只是使用不同的度量来度量相似性。原型选择是寻找可以代表整个数据集的最小实例子集,案例解释基于神经网络表示的接近性作为相似性度量,从而可能暴露出神经网络的隐藏表示信息。因此,案例解释也与深度度量学习有关[2]。
如图12所示,E.Wallace等[3]采用k近邻算法来获取特征空间中查询案例的最相似案例,然后计算属于预期类别的最近邻居的百分比作为可解释性的度量,表明预测量有多少数据支持。C.Chen等[4]构建了一个可以通过发现原型的一部分来解剖图像的模型。具体来说,模型的pipeline在卷积层之后分为多个通道,其中每个通道的功能都可以学习输入的原型部分,例如鸟类的头部或身体。基于通道所表示的原型部分特征的相似性来确定相似实例。
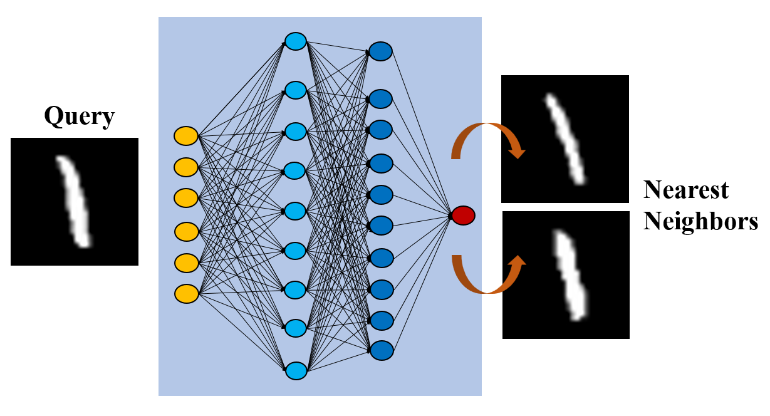
图 12. 案例解释提供在神经网络看来与输入案例最近的邻居来暴露神经网络的信息
S.Wachter等[5]提供一个反事实案例,这是一种新颖的基于案例的解释方法。反事实案例是一种假想的案例,它在神经网络的表示中接近查询案例,但与查询案例的输出略有不同。反事实案例解释提供了所谓的“最可能的另一种情况”或最小的变化以产生不同的结果。例如,反事实的解释可能会产生以下说法:“如果您有出色的前锋,您的球队将赢得这场足球比赛。”巧合的是,产生反事实解释的技术本质上就是产生“对抗性扰动”[6]。本质上,找到与输入x最接近的可能情况x'等效于找到对x的最小扰动,从而使分类结果发生变化。例如,可以构建以下优化:
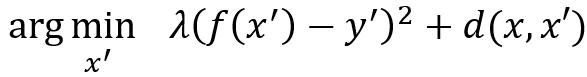
其中λ是一个常数,y^'是一个不同的标号,并且选择d(⋅,⋅)作为曼哈顿距离,以希望输入受到的干扰最小。Y. Goyal等 [7]探索了一种替代方法来导出反事实案例。给定带有标签c的图像I,由于反事实的视觉解释代表输入的变化,可以迫使模型产生不同的预测类别c',因此他们选择了带有标签c'的图像I',并设法识别出I和I'中的空间区域,当互换识别区域时会将模型预测从c更改为c'。
7. 文本解释
神经图像字幕使用神经网络为图像生成自然语言描述。尽管神经图像字幕最初并不是为了网络的可解释性,但是有关图像的描述性语言可以告诉我们神经网络是如何分析图像的。代表性的方法来自[1]该方法结合了卷积神经网络和双向递归神经网络以获得双模态嵌入。[1]的方法基于这样的假设:在两个模态中表示相似语义的两个嵌入应该共享两个空间的附近位置,因此将目标函数定义为:
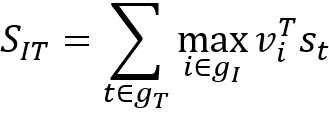
其中v_i是图像集合g_I中的第i ^个图像片段,而s_t是句子g_T中的第t个单词。这样的模型可以告诉我们网络的特征对应于什么样的文本。另一个有代表性的方法是注意力机制[2-5]。文本和注意力图中的对应词提供了对深层特征的解释,反映了图像的哪些部分吸引了神经网络的注意力。但是S.Jain和BC Wallace [6]认为注意力图不适合作为解释,因为他们观察到注意力图与基于梯度的热图不相关。
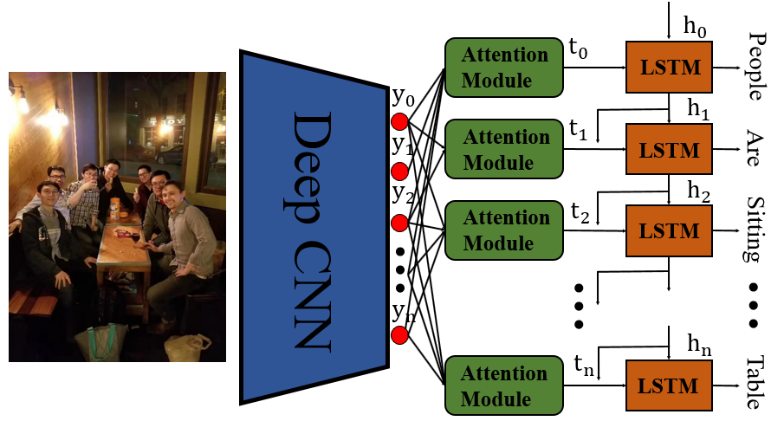
图 13. 含有注意力机制的图像标注模块借助文本提供了网络的一个解释
三.事前可解释性建模
1. 可解释表示
传统上,深度学习的正则化技术主要是为了避免过度拟合而设计的。然而,从分解性[1],[2], [3],单调性[4],非负性[5],稀疏性[6], 包括human-in-the-loop的先验[7] 方面设计正则化技术来增强可解释的表示也是可行的。
例如,X. Chen等[1]发明了InfoGAN,它可以促使GAN产生可解释性的表示。传统上,生成对抗网络(GAN)对发生器如何利用噪声没有施加任何限制。而InfoGAN最大化了潜在代码和观测值之间的相互信息,从而迫使噪声的每个维度对语义概念进行编码,这样我们就知道每个噪声维度所代表的意义。特别地,噪声由离散的分类代码和连续的样式代码组成。如图14所示,两个样式代码分别控制数字的局部部分和数字旋转。

图 14. 在 InfoGAN中,噪声编码数字的局部部分和旋转部分
纳入单调性约束[4]对于增强可解释性也是有用的。单调关系意味着当指定属性的值增加时,模型的预测值将单调增加或减少,这种简单的关系促进了可解释性。J. Chorowski和J. M. Zurada [5]对神经网络的权重施加非负性,并认为它可以改善可解释性,因为它消除了神经元之间的抵消和混叠效应。A. Subramanian等[6]采用k稀疏自动编码器进行词嵌入,以提高嵌入的稀疏性,并也声称这样可以增强可解释性是因为稀疏嵌入减少了词之间的重叠。Lage等 [7]提出了一种新颖的human-in-the-loop的正则化。具体来说,他们训练了多种模型并将其发送给用户进行评估。要求用户预测某个模型将为数据点分配什么标签。响应时间越短,表示用户对模型的理解就越好。然后,选择响应时间最短的模型。
2. 模型修缮
L.Chu等 [1]提出使用分段线性函数作为神经网络(PLNN)的激活函数(也包括ReLU),PLNN有十分明确的决策边界,并且我们可以导出封闭形式的解来求解网络的决策边界。如图15所示,F.Fan等[2] 提出了软自动编码器(Soft-AE),软自编码器在编码层中使用自适应的软阈值单元和在解码层中使用线性单元。因此,软自编码器可以解释为一个可学习的级联小波自适应系统。
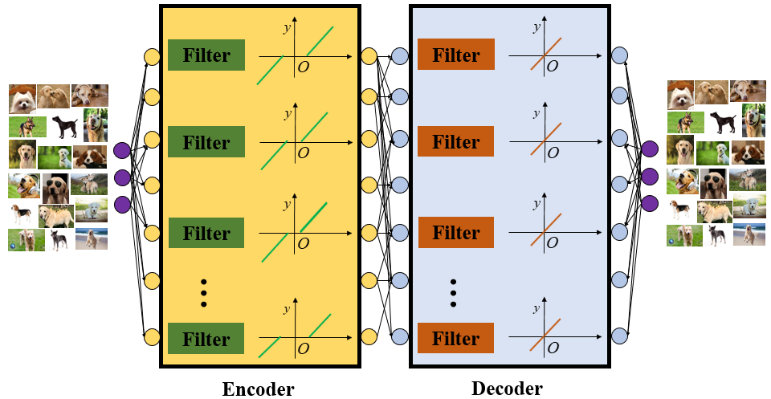
图 15.软自编码器在编码层中使用自适应的软阈值单元和在解码层中使用线性单元。因此,软自编码器可以解释为一个可学习的级联小波自适应系统
L. Fan [3]通过修改偏差项将神经网络解释为广义汉明(Hamming)网络,其神经元计算广义汉明距离:
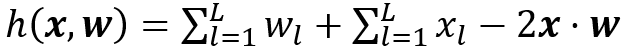
这里输入是x=(x_1,…,x_L)和权重向量w=(w_1,…,w_L). 如果我们将每个神经元中的偏差项指定为 :
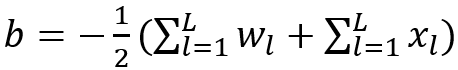
每个神经元是广义汉明神经元。在这种观点下,batch-normalization的功能就可以解释了:batch-normalization就是为了让偏差来配凑出广义汉明距离。C.C.J.Kuo等人[4]提出了一种透明的设计,用于构造前馈卷积网络,而无需反向传播。具体来说,通过为早期池化层的输出选择PCA的主成分来构建卷积层中的滤波器。然后用线性平方回归器来构建全连接层。
DA Melis和T. Jaakkola [5]认为,如果神经网络模型f具有以下形式,则它是可解释的:
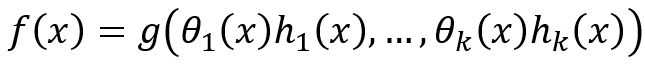
其中h_i(x)是输入x的原型特征,而θ_i(x)是与该概念相关的重要性,g是单调的并且完全可加分离。这样的模型可以学习可解释的基础概念并且方便进行显著性分析。类似地,J.Vaughan等[6]设计了一种网络结构,这种结构对应的输出函数是:
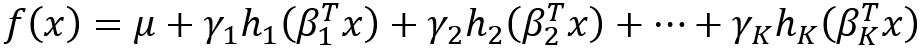
的函数,其中β_k是投影,h_k(⋅)表示非线性变换,μ是偏差,而γ_k是加权因子。这样的模型比一般的网络更具解释性,因为该模型的功能具有更简单的偏导数,可以简化显著性分析,统计分析等。
C. Li等[7]提出了通过在中间层的特征上使用层级标签,比如“人→中国人→安徽人”来进行深度监督。具体来说,我们有一个数据集{(x,y_1,…,y_m)},其中标签y_1,…,y_m是分层的。我们使用分层标签去监督深度网络的层,然后网络里的层就会依次学到对应的标签的特征。然后我们可以从top-level上感知到层的功能。这种方案引入了模块化的思想,从而获得可解释性。
T. Wang [8]建议对那些只要简单模型就可以分类的数据使用可解释和可插入的替代模型。在他们的工作中,将规则集构建为可解释的模型,以便首先对输入数据进行分类。那些规则集难以分类的输入将传递到黑盒模型中进行决策。这种混合预测系统的逻辑是,在不影响准确性的情况下,可以为常规案件提供可解释的模型,为复杂案件提供复杂的黑匣子模型。
C. Jiang等[9]提出了有限自动机递归神经网络(FA-RNN),可以将其FA-RNN直接转换为正则表达式,从而获得解释力。具体来说,可以将构造的FA-RNN近似为有限自动机,然后将其转换为正则表达式,因为有限自动机和正则表达式可以相互转换。以此类推,正则表达式也可以解码为FA-RNN作为初始化。FA-RNN是体现规则系统和神经网络之间协同作用的一个很好的例子。
四.深入讨论
1. 深度学习与规则系统
模糊逻辑[1]在上个世纪九十年代中非常火。它将布尔逻辑从0-1判断扩展到可以取[0,1]中的任何值的推断。模糊理论可以分为两个分支:模糊集理论和模糊逻辑理论。后者以“ IF-THEN”规则为重点,并以IF-THEN规则的形式表示一个系统,在处理大量复杂的系统建模和控制问题方面显示出了有效性。然而,基于模糊规则的系统也受到很大限制,构建模糊规则的过程繁琐且计算量大。神经网络是一种数据驱动的方法,它通过训练从数据中提取知识,但是神经网络所表示的知识是分布在每个神经元中的。在数据量较小的情况下,神经网络无法提供令人满意的结果,并且缺乏可解释性。神经网络和模糊逻辑系统是互补的。因此,将两个世界的优点结合起来对于增强可解释性有帮助。实际上,这个路线图并不是全新的。沿着这个方向有几种可能的模型:ANFIS模型[2],通用模糊感知器[3],RBF网络[4]等。
我们可以建立一个深层的RBF网络。给定输入向量x = [x_1,x_2,…,x_n],RBF网络表示为:
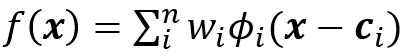
其中ϕ_i(x-c_i)为通常选择为:
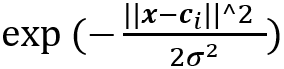
其中c_i是第i个神经元的簇中心。[4]证明了在温和条件下RBF网络与模糊推理系统之间的功能等效性。同样,RBF网络可以作为通用逼近器[5]。因此,RBF网络是一种潜在的可靠的载体,自带规则而不会损失准确性。而且与多层感知器相比,自适应RBF网络中的规则生成和模糊规则表示更为简单。尽管当前的RBF网络只是具有一层隐藏的结构,但开发深层的RBF网络是可行的,可以将深层RBF视为深层的模糊规则系统。贪婪训练算法[6]成功地解决了深度网络的训练问题。可以将这种成功应用在深度RBF网络的训练。然后,使用深度RBF网络与深度模糊逻辑系统之间的对应关系来获得深度模糊规则系统。
2. 深度学习与脑科学
迄今为止,真正的复杂智能系统仍然只有人类大脑。早期形式的人工神经网络显然受到了生物神经网络的启发[1]。然而,神经网络的后续发展却基本不是由神经科学的观点来推动的。就可解释性而言,由于生物和人工神经网络之间有着深厚的联系,神经科学的进步与深度学习技术的发展和解释有密切的关系。我们认为,神经科学在以下几个方面将为深度学习解释性带来广阔的前景。
损失函数:有效的损失函数是过去几年中深度网络发展的重要动力;例如,GAN中使用的对抗性损失[2]。在之前的技术部分中,我们重点介绍了一些损失函数的案例,这些案例表明适当的损失函数将使模型能够学习可解释的表示形式,例如增强特征可分离性。我们的大脑是一个最好的优化机器[3],该机器具有强大而准去的权重分配机制。通过研究大脑,可以帮助我们建立生物学上合理的损失函数。
优化算法:尽管反向传播取得了巨大的成功,但从神经科学的角度来看,它远非理想。实际上,从许多方面讲,反向传播都无法表现出人类神经系统调节神经元突触的真实方式。例如,在生物神经系统中,突触以局部方式更新[4],并且仅取决于突触前和突触后神经元的活动。但是,深度网络中的连接是通过非本地反向传播进行调整的。另外,与人脑的内部工作相比,深度网络中缺少类似神经调节剂的机制:其中一个神经元的状态可以表现出受全局神经调节剂(如多巴胺,5-羟色胺等)控制的不同输入输出模式[5] 。人们认为神经调节剂至关重要,因为它们能够选择性地控制一种神经元的开和关状态,从而等效地对神经元实现了模块化的控制 [6]。考虑到现在很少有研究讨论训练算法的可解释性,因此我们非常需要功能强大且可解释的训练算法。
生物合理的结构设计:在过去的几十年中,神经网络架构发展从简单的前馈网络到深度卷积网络以及其他高度复杂的网络。我们知道结构确定功能,即,特定的网络体系结构调节具有不同特征的信息流。当前,深度学习和生物大脑系统之间的结构差异非常明显。神经网络基于大数据来完成大多数任务,而生物大脑系统可以从少量数据中学习并得到很好的概括。我们需要借鉴生物神经网络,以便可以设计出更理想,更可解释的神经网络结构。相关的研究已经出现,比如MIT的研究者使用线虫的神经系统(仅有几十个神经元)构建了一个小型自动驾驶控制器 [7]。

个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文 点亮
,告诉大家你也在看
