
面试难缠的深拷贝浅拷贝,这次终于通透了
哈喽,大家好,我是指北君。
本篇文章给大家介绍面试常问的深拷贝和浅拷贝,看完之后再也不担心面试官问你这道题而做不到了。
1、创建对象的5种方式
①、通过 new 关键字
这是最常用的一种方式,通过 new 关键字调用类的有参或无参构造方法来创建对象。比如 Object obj = new Object();
②、通过 Class 类的 newInstance() 方法
这种默认是调用类的无参构造方法创建对象。比如 Person p2 = (Person) Class.forName("com.ys.test.Person").newInstance();
③、通过 Constructor 类的 newInstance 方法
这和第二种方法类都是通过反射来实现。通过 java.lang.relect.Constructor 类的 newInstance() 方法指定某个构造器来创建对象。
Person p3 = (Person) Person.class.getConstructors()[0].newInstance();
实际上第二种方法利用 Class 的 newInstance() 方法创建对象,其内部调用还是 Constructor 的 newInstance() 方法。
④、利用 Clone 方法
Clone 是 Object 类中的一个方法,通过 对象A.clone() 方法会创建一个内容和对象 A 一模一样的对象 B,clone 克隆,顾名思义就是创建一个一模一样的对象出来。
Person p4 = (Person) p3.clone();
⑤、反序列化
序列化是把堆内存中的 Java 对象数据,通过某种方式把对象存储到磁盘文件中或者传递给其他网络节点(在网络上传输)。而反序列化则是把磁盘文件中的对象数据或者把网络节点上的对象数据,恢复成Java对象模型的过程。
2、Clone 方法
本篇博客我们讲解的是 Java 的深拷贝和浅拷贝,其实现方式正是通过调用 Object 类的 clone() 方法来完成。在 Object.class 类中,源码为:
protected native Object clone() throws CloneNotSupportedException;
这是一个用 native 关键字修饰的方法,关于native关键字有一篇博客专门有介绍,不理解也没关系,只需要知道用 native 修饰的方法就是告诉操作系统,这个方法我不实现了,让操作系统去实现。具体怎么实现我们不需要了解,只需要知道 clone方法的作用就是复制对象,产生一个新的对象。那么这个新的对象和原对象是什么关系呢?
3、基本类型和引用类型
这里再给大家普及一个概念,在 Java 中基本类型和引用类型的区别。
在 Java 中数据类型可以分为两大类:基本类型和引用类型。
基本类型也称为值类型,分别是字符类型 char,布尔类型 boolean以及数值类型 byte、short、int、long、float、double。
引用类型则包括类、接口、数组、枚举等。
Java 将内存空间分为堆和栈。基本类型直接在栈中存储数值,而引用类型是将引用放在栈中,实际存储的值是放在堆中,通过栈中的引用指向堆中存放的数据。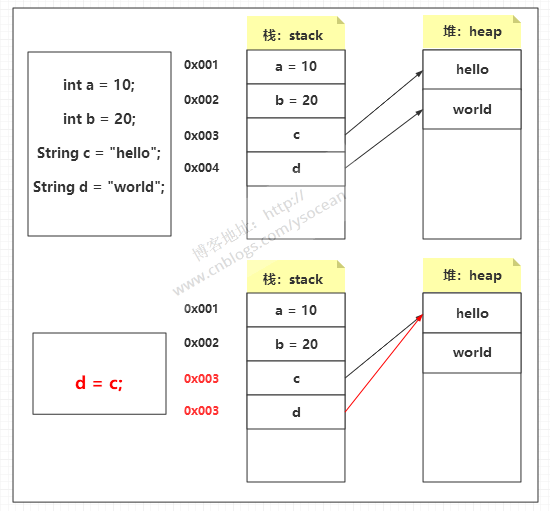 上图定义的 a 和 b 都是基本类型,其值是直接存放在栈中的;而 c 和 d 是 String 声明的,这是一个引用类型,引用地址是存放在 栈中,然后指向堆的内存空间。
上图定义的 a 和 b 都是基本类型,其值是直接存放在栈中的;而 c 和 d 是 String 声明的,这是一个引用类型,引用地址是存放在 栈中,然后指向堆的内存空间。
下面 d = c;这条语句表示将 c 的引用赋值给 d,那么 c 和 d 将指向同一块堆内存空间。
4、浅拷贝
我们看如下这段代码:
package com.ys.test;
public class Person implements Cloneable{
public String pname;
public int page;
public Address address;
public Person() {}
public Person(String pname,int page){
this.pname = pname;
this.page = page;
this.address = new Address();
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
public void setAddress(String provices,String city ){
address.setAddress(provices, city);
}
public void display(String name){
System.out.println(name+":"+"pname=" + pname + ", page=" + page +","+ address);
}
public String getPname() {
return pname;
}
public void setPname(String pname) {
this.pname = pname;
}
public int getPage() {
return page;
}
public void setPage(int page) {
this.page = page;
}
}
这是一个我们要进行赋值的原始类 Person。下面我们产生一个 Person 对象,并调用其 clone 方法复制一个新的对象。
注意:调用对象的 clone 方法,必须要让类实现 Cloneable 接口,并且覆写 clone 方法。
测试:
@Test
public void testShallowClone() throws Exception{
Person p1 = new Person("zhangsan",21);
p1.setAddress("湖北省", "武汉市");
Person p2 = (Person) p1.clone();
System.out.println("p1:"+p1);
System.out.println("p1.getPname:"+p1.getPname().hashCode());
System.out.println("p2:"+p2);
System.out.println("p2.getPname:"+p2.getPname().hashCode());
p1.display("p1");
p2.display("p2");
p2.setAddress("湖北省", "荆州市");
System.out.println("将复制之后的对象地址修改:");
p1.display("p1");
p2.display("p2");
}
打印结果为: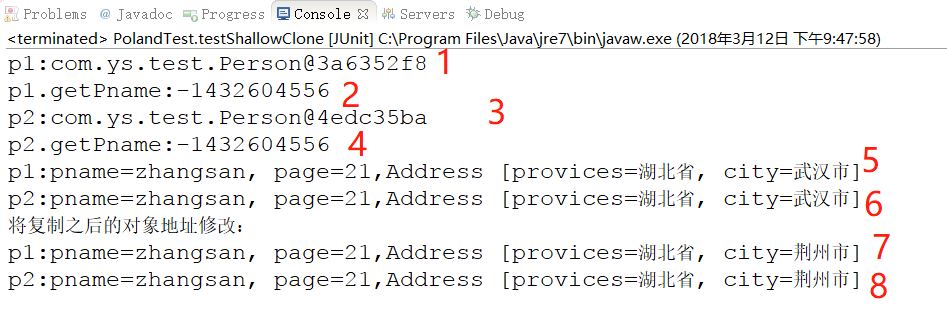 首先看原始类 Person 实现 Cloneable 接口,并且覆写 clone 方法,它还有三个属性,一个引用类型 String定义的 pname,一个基本类型 int定义的 page,还有一个引用类型 Address ,这是一个自定义类,这个类也包含两个属性 pprovices 和 city 。
首先看原始类 Person 实现 Cloneable 接口,并且覆写 clone 方法,它还有三个属性,一个引用类型 String定义的 pname,一个基本类型 int定义的 page,还有一个引用类型 Address ,这是一个自定义类,这个类也包含两个属性 pprovices 和 city 。
接着看测试内容,首先我们创建一个Person 类的对象 p1,其pname 为zhangsan,page为21,地址类 Address 两个属性为 湖北省和武汉市。接着我们调用 clone() 方法复制另一个对象 p2,接着打印这两个对象的内容。
从第 1 行和第 3 行打印结果:
p1:com.ys.test.Person@349319f9
p2:com.ys.test.Person@258e4566
可以看出这是两个不同的对象。
从第 5 行和第 6 行打印的对象内容看,原对象 p1 和克隆出来的对象 p2 内容完全相同。
代码中我们只是更改了克隆对象 p2 的属性 Address 为湖北省荆州市(原对象 p1 是湖北省武汉市) ,但是从第 7 行和第 8 行打印结果来看,原对象 p1 和克隆对象 p2 的 Address 属性都被修改了。
也就是说对象 Person 的属性 Address,经过 clone 之后,其实只是复制了其引用,他们指向的还是同一块堆内存空间,当修改其中一个对象的属性 Address,另一个也会跟着变化。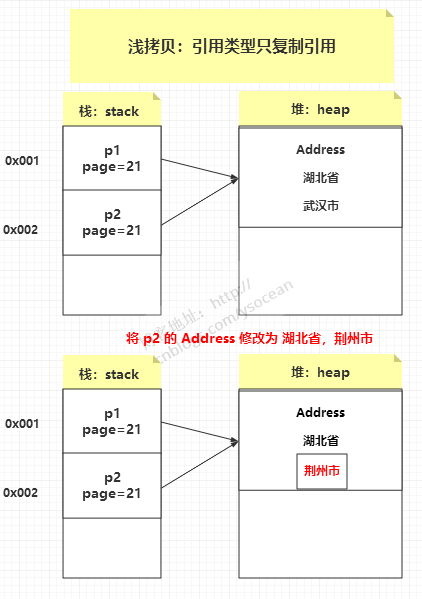
浅拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该新对象,如果字段是值类型的,那么对该字段执行复制;如果该字段是引用类型的话,则复制引用但不复制引用的对象。因此,原始对象及其副本引用同一个对象。
5、深拷贝
弄清楚了浅拷贝,那么深拷贝就很容易理解了。
深拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该新对象,无论该字段是值类型的还是引用类型,都复制独立的一份。当你修改其中一个对象的任何内容时,都不会影响另一个对象的内容。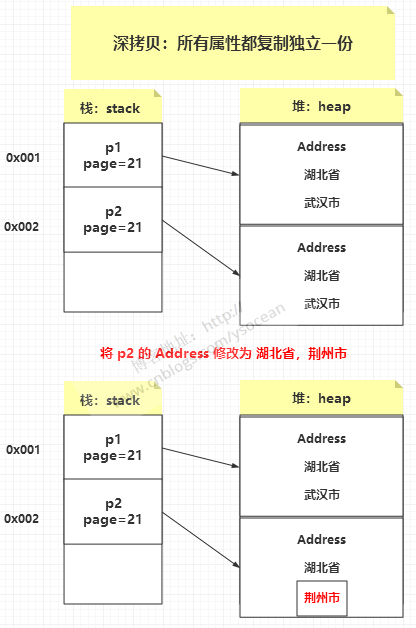 那么该如何实现深拷贝呢?Object 类提供的 clone 是只能实现 浅拷贝的。
那么该如何实现深拷贝呢?Object 类提供的 clone 是只能实现 浅拷贝的。
6、如何实现深拷贝?
深拷贝的原理我们知道了,就是要让原始对象和克隆之后的对象所具有的引用类型属性不是指向同一块堆内存,这里有两种实现思路。
①、让每个引用类型属性内部都重写clone() 方法
既然引用类型不能实现深拷贝,那么我们将每个引用类型都拆分为基本类型,分别进行浅拷贝。比如上面的例子,Person 类有一个引用类型 Address(其实String 也是引用类型,但是String类型有点特殊,后面会详细讲解),我们在 Address 类内部也重写 clone 方法。如下:
Address.class:
package com.ys.test;
public class Address implements Cloneable{
private String provices;
private String city;
public void setAddress(String provices,String city){
this.provices = provices;
this.city = city;
}
@Override
public String toString() {
return "Address [provices=" + provices + ", city=" + city + "]";
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
Person.class 的 clone() 方法:
@Override
protected Object clone() throws CloneNotSupportedException {
Person p = (Person) super.clone();
p.address = (Address) address.clone();
return p;
}
测试还是和上面一样,我们会发现更改了p2对象的Address属性,p1 对象的 Address 属性并没有变化。
但是这种做法有个弊端,这里我们Person 类只有一个 Address 引用类型,而 Address 类没有,所以我们只用重写 Address 类的clone 方法,但是如果 Address 类也存在一个引用类型,那么我们也要重写其clone 方法,这样下去,有多少个引用类型,我们就要重写多少次,如果存在很多引用类型,那么代码量显然会很大,所以这种方法不太合适。
②、利用序列化
序列化是将对象写到流中便于传输,而反序列化则是把对象从流中读取出来。这里写到流中的对象则是原始对象的一个拷贝,因为原始对象还存在 JVM 中,所以我们可以利用对象的序列化产生克隆对象,然后通过反序列化获取这个对象。
注意每个需要序列化的类都要实现 Serializable 接口,如果有某个属性不需要序列化,可以将其声明为 transient,即将其排除在克隆属性之外。
//深度拷贝
public Object deepClone() throws Exception{
// 序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(this);
// 反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
return ois.readObject();
}
因为序列化产生的是两个完全独立的对象,所有无论嵌套多少个引用类型,序列化都是能实现深拷贝的。
7、小结
至此,什么是深拷贝,什么是浅拷贝,相信你一定明白了。
我是指北君,操千曲而后晓声,观千剑而后识器。感谢各位人才的:点赞、收藏和评论,我们下期更精彩!