
深度解读Python深拷贝与浅拷贝问题

在平时工作中,经常涉及到数据的传递,在数据传递使用过程中,可能会发生数据被修改的问题。为了防止数据被修改,就需要在传递一个副本,即使副本被修改,也不会影响原数据的使用。为了生成这个副本,就产生了拷贝。今天就说一下Python中的深拷贝与浅拷贝的问题。
概念普及:对象、可变类型、引用
数据拷贝会涉及到Python中对象、可变类型、引用这3个概念,先来看看这几个概念,只有明白了他们才能更好的理解深拷贝与浅拷贝到底是怎么一回事。
在Python中,对对象有一种很通俗的说法,万物皆对象。说的就是构造的任何数据类型都是一个对象,无论是数字,字符串,还是函数,甚至是模块,Python都对当做对象处理。
所有Python对象都拥有三个属性:身份、类型、值。
看一个简单的例子:
In [1]: name = "laowang" # name对象
In [2]: id(name) # id:身份的唯一标识
Out[2]: 1698668550104
In [3]: type(name) # type:对象的类型,决定了该对象可以保存什么类型的值
Out[3]: str
In [4]: name # 对象的值,表示的数据
Out[4]: 'laowang'
在Python中,按更新对象的方式,可以将对象分为2大类:可变对象与不可变对象。
可变对象: 列表、字典、集合
所谓可变是指可变对象的值可变,身份是不变的。
不可变对象:数字、字符串、元组
不可变对象就是对象的身份和值都不可变。新创建的对象被关联到原来的变量名,旧对象被丢弃,垃圾回收器会在适当的时机回收这些对象。
In [7]: var1 = "python"
In [8]: id(var1)
Out[8]: 1700782038408
#由于var1是不可变的,重新创建了java对象,随之id改变,旧对象python会在某个时刻被回收
In [9]: var1 = "java"
In [10]: id(var1)
Out[10]: 1700767578296
在 Python 程序中,每个对象都会在内存中申请开辟一块空间来保存该对象,该对象在内存中所在位置的地址被称为引用。在开发程序时,所定义的变量名实际就对象的地址引用。
引用实际就是内存中的一个数字地址编号,在使用对象时,只要知道这个对象的地址,就可以操作这个对象,但是因为这个数字地址不方便在开发时使用和记忆,所以使用变量名的形式来代替对象的数字地址。在 Python 中,变量就是地址的一种表示形式,并不开辟开辟存储空间。
就像 IP 地址,在访问网站时,实际都是通过 IP 地址来确定主机,而 IP 地址不方便记忆,所以使用域名来代替 IP 地址,在使用域名访问网站时,域名被解析成 IP 地址来使用。
通过一个例子来说明变量和变量指向的引用就是一个东西
In [11]: age = 18
In [12]: id(age)
Out[12]: 1730306752
In [13]: id(18)
Out[13]: 1730306752
逐步深入:引用赋值
上边已经明白,引用就是对象在内存中的数字地址编号,变量就是方便对引用的表示而出现的,变量指向的就是此引用。赋值的本质就是让多个变量同时引用同一个对象的地址。 那么在对数据修改时会发生什么问题呢?
不可变对象的引用赋值
对不可变对象赋值,实际就是在内存中开辟一片空间指向新的对象,原不可变对象不会被修改。
原理图如下:
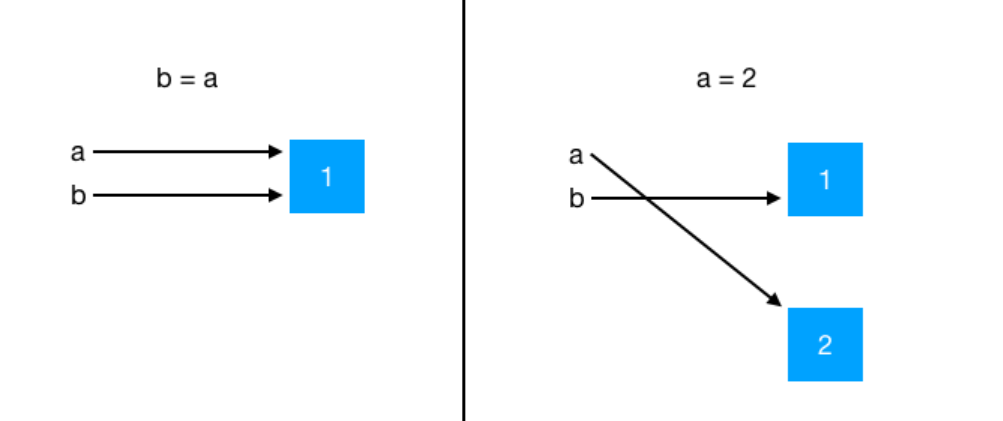
下面通过案例来理解一下:
a与b在内存中都是指向1的引用,所以a、b的引用是相同的
In [1]: a = 1
In [2]: b = a
In [3]: id(a)
Out[3]: 1730306496
In [4]: id(b)
Out[4]: 1730306496
现在再给a重新赋值,看看会发生什么变化?
从下面不难看出:当给a 赋新的对象时,将指向现在的引用,不在指向旧的对象引用。
In [1]: a = 1
In [2]: b = a
In [5]: a = 2
In [6]: id(a)
Out[6]: 1730306816
In [7]: id(b)
Out[7]: 1730306496
可变对象的引用赋值
可变对象保存的并不是真正的对象数据,而是对象的引用。当对可变对象进行赋值时,只是将可变对象中保存的引用指向了新的对象。
原理图如下:
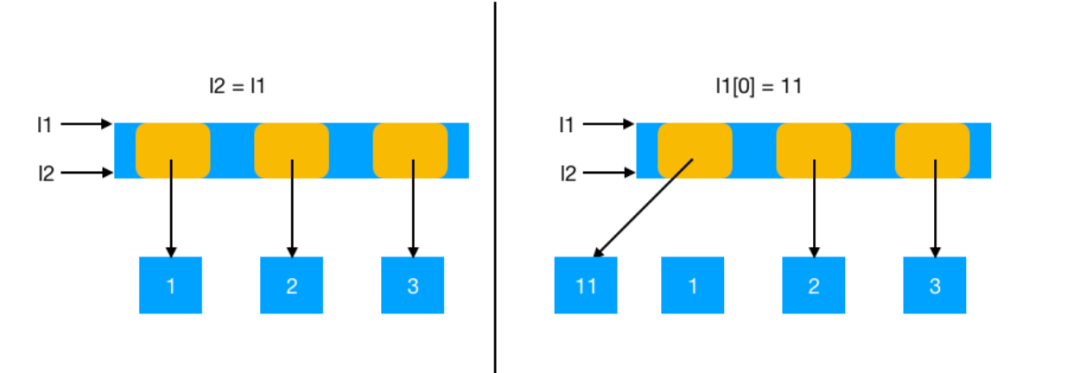
仍然通过一个实例来体会一下,可变对象引用赋值的过程。
当改变l1时,整个列表的引用会指新的对象,但是l1与l2都是指向保存的同一个列表的引用,所以引用地址不会变。
In [3]: l1 = [1, 2, 3]
In [4]: l2 = l1
In [5]: id(l1)
Out[5]: 1916633584008
In [6]: id(l2)
Out[6]: 1916633584008
In [7]: l1[0] = 11
In [8]: id(l1)
Out[8]: 1916633584008
In [9]: id(l2)
Out[9]: 1916633584008
浅拷贝就是创建一个具有相同类型,相同值但不同id的新对象。浅拷贝仅仅对对象自身创建了一份拷贝,而没有在进一步处理对象中包含的子对象值(比如列表,字典等子对象。也就是说浅拷贝对子对象不起作用,其中一个变量的子对象值被修改了,另外一个也跟着被修改。因此使用浅拷贝的典型使用场景是:对象自身发生改变的同时需要保持对象中的值完全相同,比如 list 排序。
深拷贝不仅仅拷贝了原始对象自身,也对其包含的值进行拷贝,它会递归的查找对象中包含的其他对象的引用,来完成更深层次拷贝。拷贝完成以后,两个变量为完全独立的对象,互不影响。因此,深拷贝产生的副本可以随意修改而不需要担心会引起原始值的改变。
例子# 浅拷贝方法是copy.copy()import copya = [7, 5, 6, ['m', 'o', 'p']]b = copy.copy(a)print(id(a), id(b))print(a is b)print(F'a,{a}与b,{b}有一样的值\n')a.append(10)print("浅COPY是值互不影响\n")print(id(a), id(b))print('a被修改为:',a)print('b没有被修改',b)a[3].append('new')print("浅COPY不能COPY子对象的值,a的子对象修改了,b也跟着修改\n")print(id(a), id(b))print('a的值也被修改为:',a)print('b的值也被修改为:',b)print(a is b)print(a[3] is b[3])4528962568 4528970824Falsea,[7, 5, 6, ['m', 'o', 'p']]与b,[7, 5, 6, ['m', 'o', 'p']]有一样的值浅COPY是值互不影响4528962568 4528970824a被修改为: [7, 5, 6, ['m', 'o','p'], 10]b没有被修改 [7, 5, 6, ['m', 'o','p']]浅COPY不能COPY自对象的值,a的子对象修改了, b也跟着修改4528962568 4528970824a的值也被修改为: [7, 5, 6, ['m', 'o','p', 'new'], 10]b的值也被修改为: [7, 5, 6, ['m', 'o','p', 'new']]FalseTrue# 深拷贝方法是copy.deepcopy()print('深拷贝的例子\n')a = [7, 5, 6, ['m', 'o', 'p']]b = copy.deepcopy(a)print(id(a), id(b))print(a is b)print(F'a,{a}与b,{b}有一样的值\n')a.append(10)print("深COPY是值互不影响\n")print(id(a), id(b))print('a被修改为:',a)print('b没有被修改',b)a[3].append('new')print("深拷贝的子对象不会被拷贝\n")print(id(a), id(b))print('a的值也被修改为:',a)print('b的值没有被修改:',b)print(a is b)print(a[3] is b[3])深拷贝的例子4526931464 4526922760Falsea,[7, 5, 6, ['m', 'o', 'p']]与b,[7, 5, 6, ['m', 'o', 'p']]有一样的值深COPY是值互不影响4526931464 4526922760a被修改为: [7, 5, 6, ['m', 'o','p'], 10]b没有被修改 [7, 5, 6, ['m', 'o','p']]深拷贝的子对象不会被拷贝4526931464 4526922760a的值也被修改为: [7, 5, 6, ['m', 'o','p', 'new'], 10]b的值没有被修改: [7, 5, 6, ['m', 'o','p']]FalseFalse综上所述,关于赋值以及深浅拷贝的区别如下:如果我们把这三个事情当作夫妻关系,赋值就是模范夫妻,要变一起变、浅copy是快要离婚的夫妻,只有孩子出事才一起商量,这个孩子就是子对象,包括字典,列表等、而深copy就是孩子大了就马上离婚了的夫妻,各自happy,互不影响。
查漏补缺
为什么Python默认的拷贝方式是浅拷贝?
时间角度:浅拷贝花费时间更少
空间角度:浅拷贝花费内存更少
效率角度:浅拷贝只拷贝顶层数据,一般情况下比深拷贝效率高。
以上文章整理自网络,如果有侵权,请后台联系删除
【提高】40多个项目实战,老手可以从真实场景中学习python;
【直播】不定期直播项目案例讲解,手把手教你如何分析项目;
【分享】优质python学习资料分享,让你在最短时间获得有价值的学习资源;圈友优质资料或学习分享,会不时给予赞赏支持,希望每个优质圈友既能赚回加入费用,也能快速成长,并享受分享与帮助他人的乐趣。
【人脉】收获一群志同道合的朋友,并且都是python从业者
【价格】本着布道思想,只需 69元 加入一个能保证学习效果的良心圈子。