
深拷贝 浅拷贝
(给前端大学加星标,提升前端技能.)
转自:掘金 - 尤雨溪的大迷弟
回顾一下老知识,记个笔记~
首先说下堆栈,基本数据类型与引用数据类型,深拷贝与浅拷贝与此相关。
一、基本数据类型 和 引用数据类型
1.变量类型分为两类:
基本数据类型:number,string,boolean,null,undefined,symbol
引用数据类型:统称为Object类型,细分的话,有:Object,Array,Date,Function等。
2.存储方式:
a.基本数据类型保存在栈内存,形式如下:栈内存中分别存储着变量的标识符以及变量的值。
例:
let a = 'A';

b.引用数据类型保存在栈内存,形式如下:名存在栈内存中,值存在于堆内存中,但是栈内存会提供一个引用的地址指向堆内存中的值。
例:
let a = {name:“A”};

3.不同类型的复制方式:
a.基本数据类型:
let a = 1;当你let b = a 时,栈内存会新开辟一个内存,例如这样:

此时改变 a 变量的值,并不会影响 b 的值。
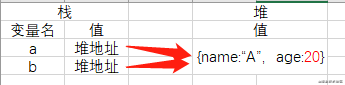
b.引用数据类型:
let a = {name: 'A',age: 10};
let b = a;
a.age = 20;
// 此时改变a的值,会改变b的值,此时内存中是这样的:
二、浅拷贝 和 深拷贝
浅拷贝:创建一个新的数据,这个数据有着原始数据属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址,所以如果其中一个数据改变了这个地址,就会影响到另一个数据。
可以说
浅拷贝只解决了数据第一层的问题,拷贝第一层的基本类型值,以及第一层的引用类型地址
深拷贝:深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。在堆中重新分配内存,拥有不同的地址,且值是一样的,复制后的对象与原来的对象是完全隔离,互不影响。
三、实现深拷贝
1.数据只有一层的时候:Object.assign()方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。但是 Object.assign() 进行的是浅拷贝,拷贝的是对象的属性的引用,而不是对象本身。当数据只有一层的时候,是深拷贝。
相同的还有数组方法
slice、concat,他们都为浅拷贝,当数据只有一层的时候,可实现深拷贝的效果
例:
let a=[1,2,3,4,{age: 1}];
let b=Object.assign([],a);
a[0]=2;
a[4].age=2;
console.log(a,b);
// (5) [2, 2, 3, 4, {…}]
// 0: 2
// 1: 2
// 2: 3
// 3: 4
// 4: {age: 2}
// length: 5
// __proto__: Array(0)
// (5) [1, 2, 3, 4, {…}]
// 0: 1
// 1: 2
// 2: 3
// 3: 4
// 4: {age: 2}
// length: 5
// __proto__: Array(0)
2.简单的递归函数:
function deepClone(obj){
let objClone = Array.isArray(obj)?[]:{};
if(obj && typeof obj==="object"){
for(key in obj){
if(obj.hasOwnProperty(key)){
//判断obj子元素是否为对象,如果是,递归复制
if(obj[key]&&typeof obj[key] ==="object"){
objClone[key] = deepClone(obj[key]);
}else{
//如果不是,简单复制
objClone[key] = obj[key];
}
}
}
}
return objClone;
}
3.JSON.parse(JSON.stringify())用JSON.stringify将对象转成JSON字符串,再用JSON.parse()把字符串解析成对象,一去一来,新的对象产生了,而且对象会开辟新的栈,实现深拷贝。
let a=[1,2,3,4,{age: 1}];
let b=JSON.parse(JSON.stringify(a));
a[0]=2;
a[4].age=2;
console.log(a,b);
// (5) [2, 2, 3, 4, {…}]
// 0: 2
// 1: 2
// 2: 3
// 3: 4
// 4: {age: 2}
// length: 5
// __proto__: Array(0)
// (5) [1, 2, 3, 4, {…}]
// 0: 1
// 1: 2
// 2: 3
// 3: 4
// 4: {age: 1}
// length: 5
// __proto__: Array(0)
该方法有几个缺陷:
1、会忽略undefined、symbol和函数,例:
let obj = {
name: 'A',
name1: undefined,
name3: function() {},
name4: Symbol('A')
}
let obj2 = JSON.parse(JSON.stringify(obj));
console.log(obj2); // {name: "A"}
2、对象循环引用时,会报错。例:
let obj = {
name1: 'A',
name2: {
name3: 'B'
},
}
obj.name1 = obj.name2;
obj.name2.name3 = obj.name1;
let obj2 = JSON.parse(JSON.stringify(obj));
console.log(obj2); // Converting circular structure to JSON
3、new Date,转换结果不正确
4、正则会被忽略
MDN的解释,JSON.stringify() 将值转换为相应的JSON格式:
转换值如果有 toJSON() 方法,该方法定义什么值将被序列化。 非数组对象的属性不能保证以特定的顺序出现在序列化后的字符串中。 布尔值、数字、字符串的包装对象在序列化过程中会自动转换成对应的原始值。 undefined、任意的函数以及 symbol 值,在序列化过程中会被忽略(出现在非数组对象的属性值中时)或者被转换成 null(出现在数组中时)。函数、undefined 被单独转换时,会返回 undefined,如JSON.stringify(function(){}) or JSON.stringify(undefined). 对包含循环引用的对象(对象之间相互引用,形成无限循环)执行此方法,会抛出错误。 所有以 symbol 为属性键的属性都会被完全忽略掉,即便 replacer 参数中强制指定包含了它们。 Date 日期调用了 toJSON() 将其转换为了 string 字符串(同Date.toISOString()),因此会被当做字符串处理。 NaN 和 Infinity 格式的数值及 null 都会被当做 null。 其他类型的对象,包括 Map/Set/WeakMap/WeakSet,仅会序列化可枚举的属性。
MDN地址:developer.mozilla.org/zh-CN/docs/…
网上看到的一个小题目:
var a = {n: 1};
var b = a;
a.x = a = {n: 2};
console.log(a); // {n: 2}
console.log(b); // {n:1, x: {n: 2}}
个人理解:
var a = {n: 1}栈中给a开辟了一个引用地址,指向堆中的对象{n: 1}var b = a栈中给b开辟了一个引用地址,指向堆中的对象{n: 1}.的优先级高于=,所以先执行a.x,堆内存中的{n: 1}就会变成{n: 1, x: undefined},改变之后相应的b.x也变化了,因为指向的是同一个对象。
赋值操作是从右到左,所以先执行a = {n: 2},a的引用就被改变了,然后这个返回值又赋值给了a.x,需要注意的是这时候a.x是第一步中的{n: 1, x: undefined}那个对象,其实就是b.x,相当于b.x = {n: 2}