竞赛方案解读:8组天池铝型材表面瑕疵总决赛方案,含数据集、模型改进、创新点等
共
6543字,需浏览
14分钟
·
2020-09-15 09:34
本文总结了天池铝型材表面瑕疵总决赛答辩的8组方案,分别介绍了它们的出发点、设计思路、模型改进、创新点、实用性分析等。
https://tianchi.aliyun.com/competition/entrance/231682/information在铝型材的实际生产过程中,由于各方面因素的影响,铝型材表面会产生裂纹、起皮、划伤等瑕疵,这些瑕疵会严重影响铝型材的质量。为保证产品质量,需要人工进行肉眼目测。然而,铝型材的表面自身会含有纹路,与瑕疵的区分度不高。传统人工肉眼检查十分费力,不能及时准确的判断出表面瑕疵,质检的效率难以把控。近年来,深度学习在图像识别等领域取得了突飞猛进的成果。铝型材制造商迫切希望采用最新的AI技术来革新现有质检流程,自动完成质检任务,减少漏检发生率,提高产品的质量,使铝型材产品的生产管理者彻底摆脱了无法全面掌握产品表面质量的状态。大赛数据集里有1万份来自实际生产中有瑕疵的铝型材监测影像数据,每个影像包含一个或多种瑕疵。供机器学习的样图会明确标识影像中所包含的瑕疵类型。
解决方案与答辩情况
这是在天池大数据平台上一个比赛的决赛答辩笔记。比赛的名字:广东工业制造大数据创新大赛,智能算法赛。比赛的初赛是分类,物体识别;复赛:目标检测。
视频地址:https://b23.tv/av66819151第一组 shuzhilian ai
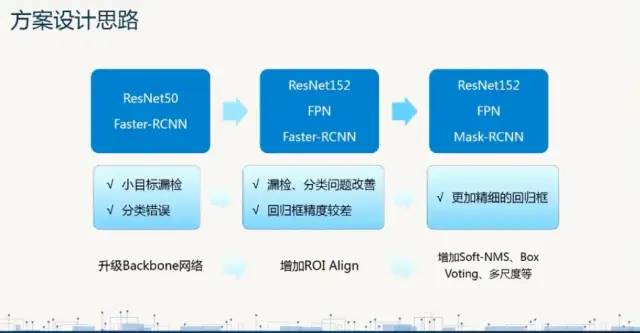
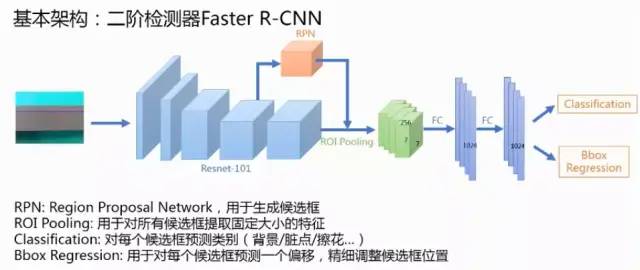
1 模型:faster rcnn + fpn + cascade basebone:resnet152
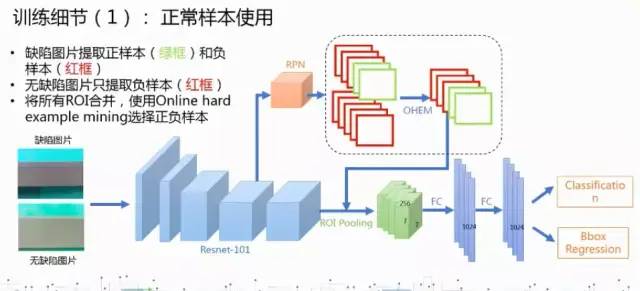
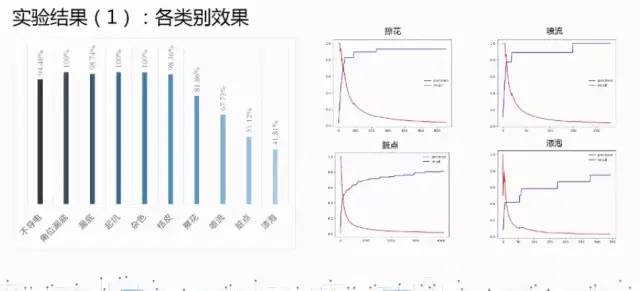
2 数据:原始的数据分布不平衡,用了图像处理的方法将每一类做到了5000张。大体上分为两种数据集,有瑕疵的一类,无瑕疵的10类。各种类别之间的瑕疵规格相差很大,类别内的瑕疵大小规格相差也没有规律。
(1)多阶段的训练:先是用负样本来训练模型,然后用正样本验证学到的模型,最后将正样本中训练错误的和负样本一起来训练模型。
(2)Scale Normalization for training : 使用rpn 。理由:缺陷里面有很多正确的纹理,这些正确的纹理将会是判别缺陷的噪音。所以使用一个合适大小的框来减少这种噪音。
3 充分运用云(1流失处理,2灵活调度,3松耦合高内聚,4日志收集)1 改进三部分哪一个部分提升的效果最好?cascade 结构
2 cascade为什么会表现更好,它可能不会收敛? 因为在级联前它保存了传统的方法,只是在传统的结构上加了额外的级联结构,所以可以在调参后收敛。3 cascade结构中每一级都是哪些样本进入到了该级?按照阈值来决定那些样本来进入该级4 cascade结构是怎么样来划分每一级的正负样本的?端到端训练的。(答辩的人没有说出来,其实论文中讲到阈值其实也就决定了正负样本。和上一个问题基本上是一样的。)
5 负样本是怎么取的?负样本对于提升有多大?77.8%,加上以后就是80.3%。
6 图像增强的时候,数据量增加到多少能达到一个最终的结果,这时增加图片就没有提升效果了?这要看数据集的复杂度,平常做的上下翻转,高斯模糊等等不能够做的太多,如果做的太多实际上训练样本对于最终的真实样本分布已经不一致了。复杂度小,增强小,复杂度高,增强多。这次做了一些的尝试,最后定在了4000到5000张左右。第二组 风不动
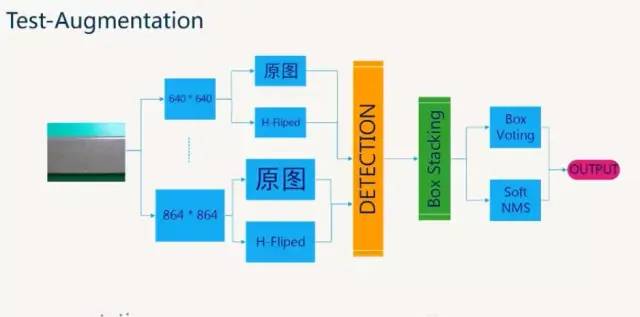
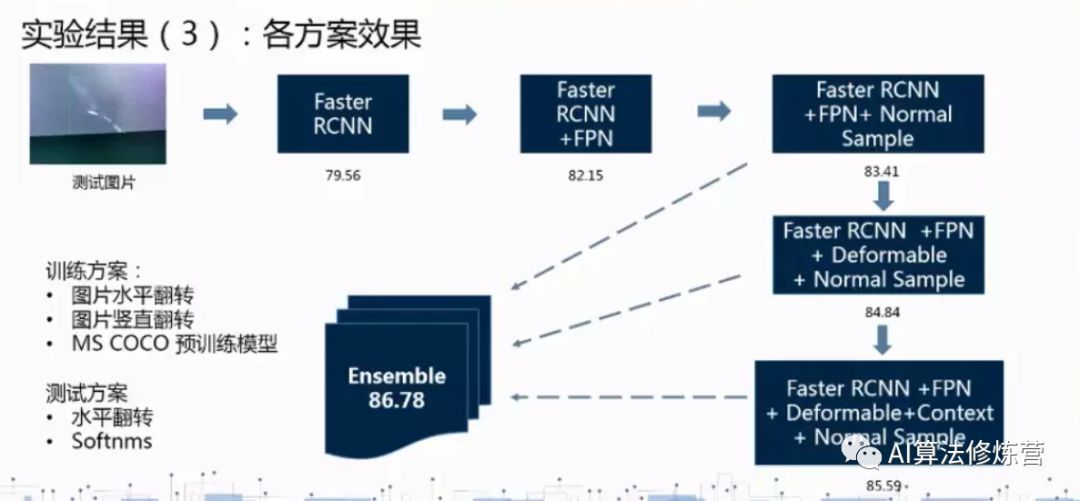
1 模型:backbone:resnet101(快速版本),两阶段模型Faster rcnn。模型版本:快速模型到最高精度模型的比较,基模型的数量从1达到了4;从单尺度测试改为6尺度测试;框的过滤阈值从0.05降低到0.01。
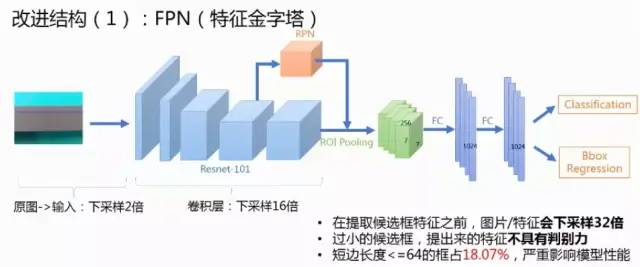
2 数据分析:图片分辨率高,缺陷的尺寸差异大,瑕疵的形状不规则,标注不贴合 。(1)由于缺陷长款比例分布不均匀采用两阶段回归,适应更多长宽比。
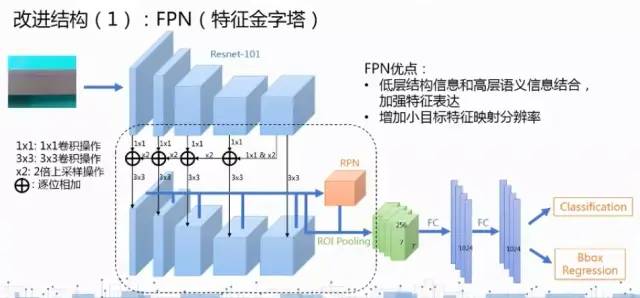
(2)由于缺陷尺度分布差异大,采用FPN结构适应更多的大小尺度。
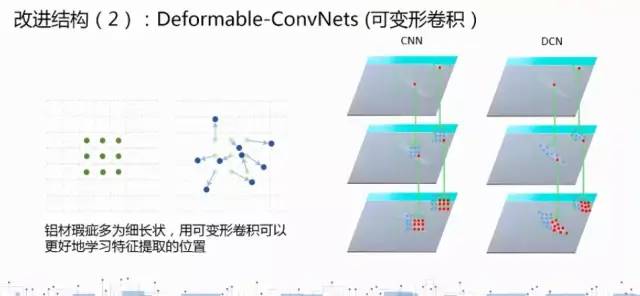
(3)缺陷往往是独立且以不规则的形状组合出现,利用可形变卷积有着更强的针对性。
(4)在训练中利用可形变卷积(DCN)能够学习到瑕疵更多形态。不规则卷积对应不规则形状有更好的针对性。( ps:通过对卷积核学习一个位置偏移权重,使得卷积核不再是标准的3*3卷积核,而是通过位置偏移实现出不规则形状的卷积核。)
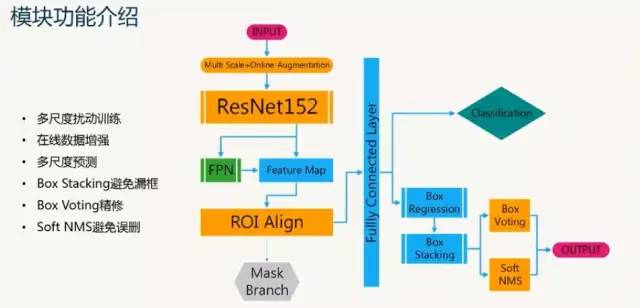
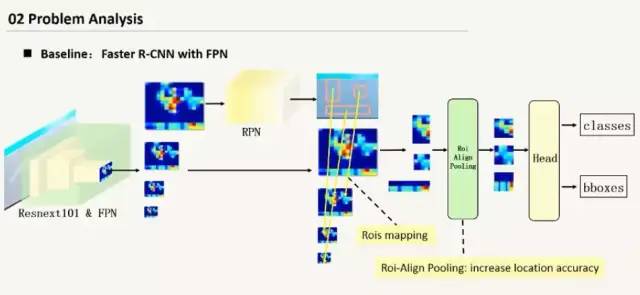
(5)由于小瑕疵的缺陷定位不准确,导致被判为误检;不完全的ROIPooling可能会未学到瑕疵的特征。 解决方案:利用ROIAlign 使得特征与空间有着更准确的对应关系;通过线性插值获得对应位置的特征值。
由于瑕疵中有非常细长的box,所以在anchor中预设一个细长的框子,他的长宽比是5:1。
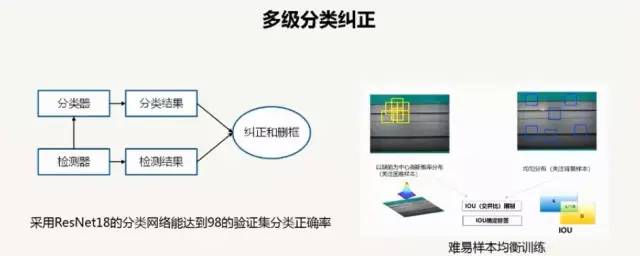
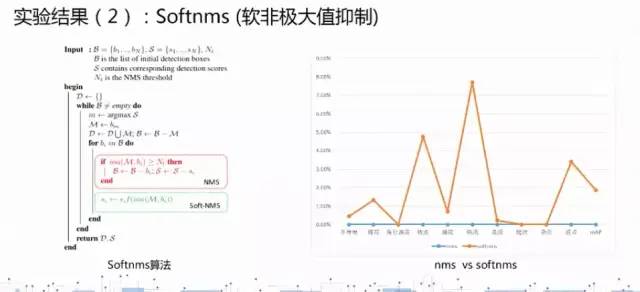
困难样本学习:(1)无困难样本增强(2)困难样本增强(3)Batch级别的困难样本增强,这个提升最强最后的框体预测:Soft-NMS,NMS,投票平均三种方法的比较经验:阈值的设置影响了召回率,但是在精度上面的提升非常有限。怎样更快?更小的基网路(resnet50,VGG);更小的输入尺度(640*480);更少的候选框(1000到50)实际场景中应用:可以采用多级分类纠正,在保证相同的MAP的情况下,删除三分之二的冗余框,大大减少对正常类的误报。
1 目的?验证算法;奖金比较吸引人的;数据不容易;2 如果提升的话,只做一个你会选择哪个方面提升? 选择使用ResNet50;其次就是更少的候选框。3 anchor虽然使用了一些狭长框体,但是这并不能够全部的包含所有的情况?本来就是一个大体上的框体。已经能够近似包含所有的情况。4 多级分类纠正在时间统计上是怎么考虑的?提交的模型不包含该模块,只是在部署的时候可以使用该部署方式。该方法对精度的提升不明显。
第三组 树根互联AILab
1 模型:backbone:resnet101(快速版本),两阶段模型Faster rcnn+FPN。
(2)用RoI Align替换掉ROIPooling;
2 数据分析:数据分布不平衡,瑕疵面积占比小,瑕疵的尺度分布变化大 。工作:数据增强采用了左右翻转,随机剪裁,中心剪裁。
(1)kmeans聚类算法分析训练集中真实框的分布;(2)ROI Align 替换掉ROI Pooling,作用:消除ROIPooling过程中的量化,获取更精准的候选框的特征,从而提高检测性能。(3)softNMS替换掉NMS,作用:针对脏点等容易大数量集中在某个区域的小瑕疵进行更好的检测。
(2)流水线吞吐量?使用一个更加轻量化的模型;MobileNet、shuffleNet、模型剪枝&压缩
(4)硬件成本太高?更实时:Nvidia jetson tx2 4000元、Pynq z2 1800元、更经济:多Zigbee网关+中央gpu服务器
(5)云计算?流水线拍摄图片,zigbee网关传输,中央GPU检测图片,流水线分拣。有点性价比高,可迁移性强,批量检测速度快,容易维护。1 图像上尺寸的分布怎么会有代表性?其中一种主要分布在左下角,一部分集中在右部一条线;
2 当分辨率降低以后,如何在数据增强中体现出应对的策略? 亮度变化,测试集中没有加入亮度差异变化,所以效果不明显,后期加入。
3 聚类的anchor和原来的anchor之间的差别有多大?提升了大概1个百分点,尺寸大小变化了,比例不变。
第四组 GDUT-WWW
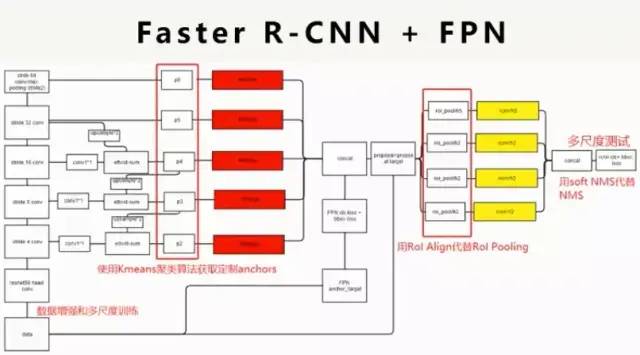
平台Detectron;框架Faster RCNN+FPN;Backbone:resnet50
Faster R-CNN默认的RPN_ASPECT_RATIONS为[1,0.5,2]手动改宽高比是[0.125,0.25,0.5,1,2,4,8];
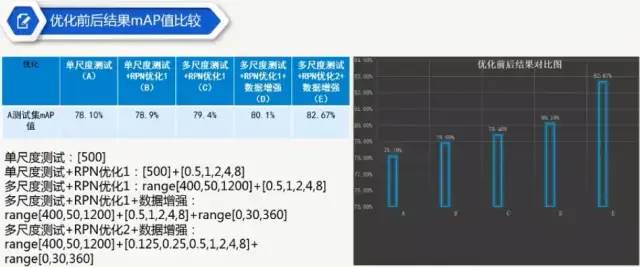
2 数据处理:制作成coco格式的数据集,数据增强(水平翻转,旋转[range(0,30,360)]),多尺度训练
(2)训练的时候讲train.scales参数优化为:[500,550,600,650,700,750,800,850,900,950,1000]实现多尺度训练(3)在预测的时候讲test.scales的参数优化为:[400,450,500,550,600,650,700,750,800,850,900,950,1000,1050,1100,1150,1200];水平翻转;NMS
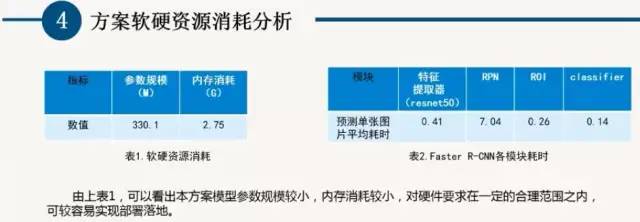
6 落地实例:酷睿I7处理器cpu的使用情况是25%;8个Movidius Myriad X VPU加速器 占用了7%。(2)在平台搭建上,采用“1+1+n”的模式,从底层开始,一个合作伙伴用一套共 性技术,服务于N个垂直行业。(3)底层的共性技术是开发平台、数据平台,资源管理平台,中间是与客户共建的SaaS级产品。(4)SaaS级产品包括与用户共建的能效云,与客户共建的工业大脑。(5)在平台上,做一个垂直的应用服务,服务于广大中小企业。(6)最后打造工业云平台的生态,构建国家级工业物联网平台。
1 为什么50层的网络要比更深层次的好?单块的1080Ti不够;2 数据增强方面只是简单的旋转吗? 只是简单的旋转,另外标注啊框也跟着旋转。
3 你说可以做迁移学习到其他任务,怎么做?提升了大概1个百分点,尺寸大小变化了,比例不变。第五组 打怪升级
Mask-rcnn ,Caffe2,Caffe2go(可以部署在一个手机上,4G到6G内存)
尺寸差异大,数据不平衡,形状不规则,人工标注则不统一。ps:标框的规则就是没有规则,按心情标。
(1)由于考虑到害怕把小的瑕疵切掉,所以没有使用切片。
(2)网络的输入尺度不同,对结果的影响是很大的。随机尺度输入相当于做了增强,而且也加快了速度,适合比赛用。1 box voting提升怎么样,会造成误检提升吗?map提高0.8个百分点,弊大于益;2 你认为什么是创新?box stacking,多尺度预测。
3 detection中常用随机扰动?是的,从原始的精调到了600。
4 传统方法和deeplearnning比较?传统方法部署没有更多的灵活性,精度上也没有deeplearnning高。第六组(第一) Are you OK?
2 数据分析:尺寸差异大,形状不规则,背景和瑕疵差异小。
1 deformable convolution?每个点都有一个偏移量,这样更好的拟合瑕疵的形状,计算量会有差别;
2 图片处理的部分,是两张图片做一个融合来进入模型的吗? 两张图片是两路输入,瑕疵候选框只能通过瑕疵照片,无瑕疵照片只能够生成背景类,这样能够让RPN能够更好的学习瑕疵和背景的区别。
第七组 都都都都都都
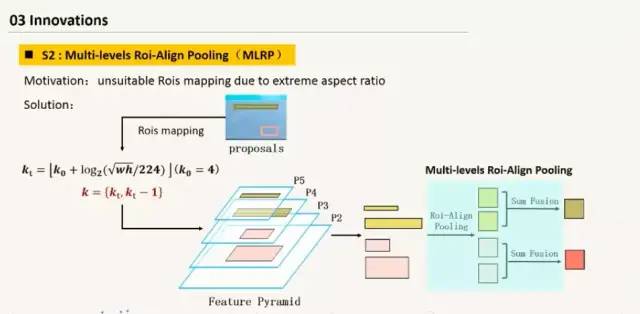
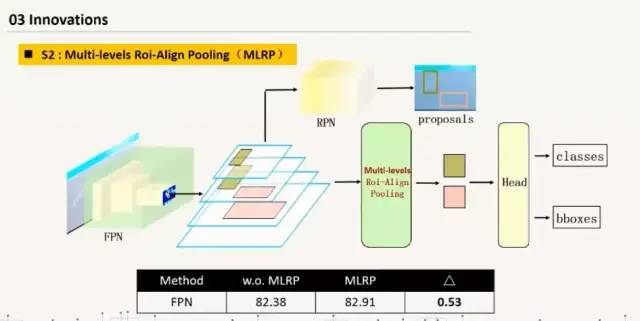
模型变化:将maskrcnn中的Align Pooling加入到该模型中;加入空洞卷积;
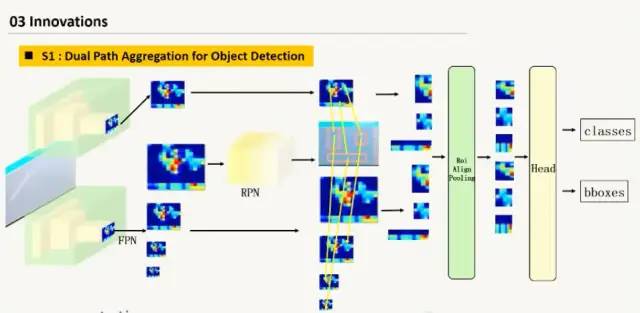
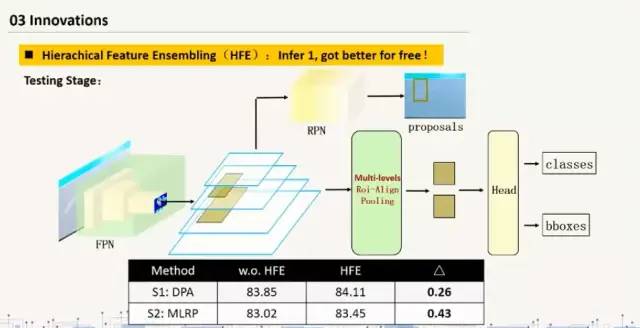
(1)双路集成的目标检测特征提取:从两路上进行特征提取。1.2fps水平或者竖直翻转;color jitter;Multi-scales Training:scaling invariance;Transfer Learning:Pretrained on Coco dataset(1)加入stochastic weight averaging这个和SGD比较有更好的准确度和更快的收敛速度。(2)Hierachical Feature Ensembling
1 第二个阶段在经过RoiAlignPooling的时候极限长宽比的?每个点都有一个偏移量,这样更好的拟合瑕疵的形状,计算量会有差别;2 去背景是比赛前做的还是比赛后做的?是在比赛后做的,减少的输入面积,map上有一点波动,但是速度提升了,map实际上是降低了。
3 模型将有些脏点是定位到了背景上了,分数应该是上升啊?去掉一个背景padding以后就会影响原来的铝材图片。可以考虑将背景的颜色去掉,换成一个新的数据集。
4 最后做的落地这个图片转换后方向是固定的切割的,但是如果改变了方向呢?假设在流水线上这种情况是可控的。
5 用数字图像处理过后将对光照等等有一个很好的鲁棒性。场景中的全部背景基本上都是蓝色背景。第八组 BOOMBOOM
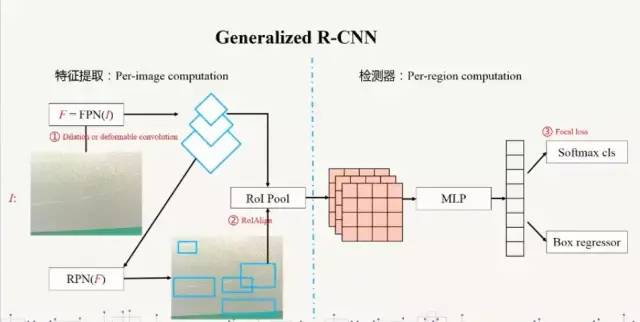
(2)为什么要用Deep Learning?弱语义信息不代表没有语义信息;规则无穷尽,不能遍举 (3)最大的困难是什么?数据,数据,数据。其次困难是什么?进场困难,缺陷样本少,标记困难。 (4)为什么coco预训练模型比imagenet预训练模型好(大家基本上都是用fpn加上coco预训练模型)? (5)FPN为什么是杀手级的结构?除了加上多尺度,其实还是增强了较底层的纹理。和深度学习中语义不断深化相比这里更像是一个浅层网络级联起来的一个网络。低层次的特征在这次更加接近输出结果。 (7)同类型的模型融合SWA;不同类模型之间的融合:DCN+G-R-CNN
1 这个框合适吗?做缺陷或者瑕疵来说,什么框最好,最好的是Segment其实是最好的方式,但是选择框其实是一种无奈的选择;2 对于划痕来说这东西很难学到的,你觉得这种东西该怎么标框呢?可以在外标一个框,然后在内用一个弱监督的方式来聚焦这些瑕疵。
推荐阅读
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-工业检测-城市(如:小极-北大-工业检测-深圳),即可申请加入极市工业检测等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~ 
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报






 下载APP
下载APP