
复旦大学邱锡鹏组最新综述:A Survey of Transformers!
作者 | Tnil@知乎
编辑 | NewBeeNLP
转眼Transformer模型被提出了4年了。依靠弱归纳偏置、易于并行的结构,Transformer已经成为了NLP领域的宠儿,并且最近在CV等领域的潜能也在逐渐被挖掘。尽管Transformer已经被证明有很好的通用性,但它也存在一些明显的问题,例如:
核心模块自注意力对输入序列长度有平方级别的复杂度,这使得Transformer对长序列应用不友好。例如一个简单的32x32图像展开就会包括1024个输入元素,一个长文档文本序列可能有成千上万个字,因此有大量现有工作提出了轻量化的注意力变体(例如稀疏注意力),或者采用『分而治之』的思路(例如引入recurrence);
与卷积网络和循环网络不同,Transformer结构几乎没有什么归纳偏置。这个性质虽然带来很强的通用性,但在小数据上却有更高的过拟合风险,因此可能需要引入结构先验、正则化,或者使用无监督预训练。
近几年涌现了很多Transformer的变体,各自从不同的角度来改良Transformer,使其在计算上或者资源需求上更友好,或者修改Transformer的部分模块机制增大模型容量等等。
但是,很多刚接触Transformer的研究人员很难直观地了解现有的Transformer变体,例如前阵子有读者私信我问Transformer相关的问题,聊了一会儿才发现他不知道Transformer中的layer norm也有pre-LN和post-LN两种变体。因此,我们认为很有必要对现有的各种Transformer变体做一次整理,于是产生了一篇survey ,现在挂在了arxiv上:
A Survey of Transformers[1] http://arxiv.org/abs/2106.04554

在这篇文章之前,已经有一些很好的对PTM和Transformer应用的综述(例如Pre-trained Models for Natural Language Processing: A Survey』[2]和 『A Survey on Visual Transformer』[3])。在这篇文章中,我们把重心放在对Transformer结构(模块级别和架构级别)的改良上,包括对Attention模块的诸多改良、各种位置表示方法等。
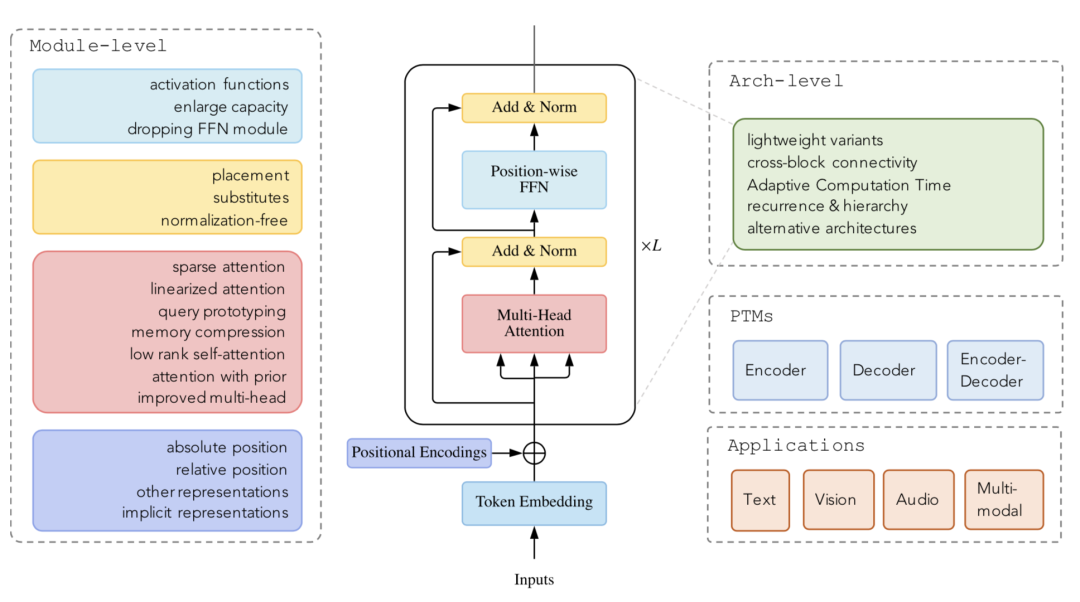
Transformer变体分类
值得一提的是,Google去年放出过一篇关于Transformer的综述(『Efficient Transformers: A Survey』[4]),主要关注了Attention模块的效率问题(这在我们的综述中也覆盖了)。虽然是一篇很好的review,但是笔者认为它对于Attention变体的分类有一些模糊,例如作者将Compressive Transformer、ETC和Longformer这一类工作、以及Memory Compressed Attention都归类为一种基于Memory的改进,笔者认为memory在这几种方法中各自有不同的含义,使用Memory来概括很难捕捉到方法的本质。我们的文章对这几个方法有不同的分类:
Compressive Transformer是一种『分而治之』的架构级别的改进,相当于在Transformer基础上添加了一个wrapper来增大有效上下文的长度;
ETC和Longformer一类方法是一种稀疏注意力的改进,主要思路是对标准注意力代表的全链接二分图的连接作稀疏化的处理;
Set Transformer、Memory Compressed Attention、Linformer对应一种对KV memory压缩的方法,思路是缩短注意力矩阵的宽。
论文中完整的对Transformer变体分类体系概览如下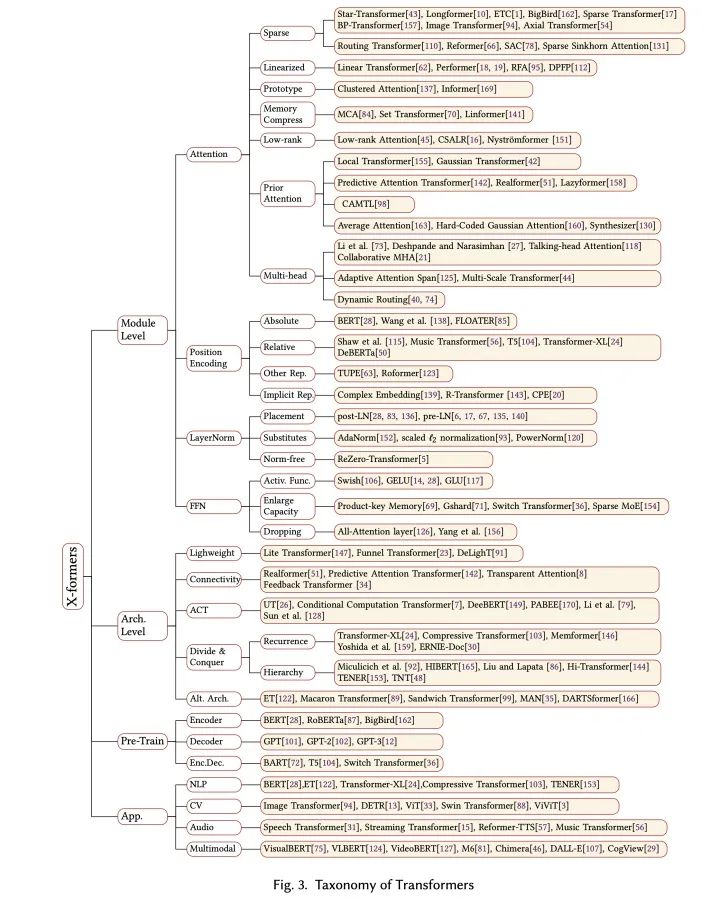
本文参考资料
A Survey of Transformers: http://arxiv.org/abs/2106.04554
[2]Pre-trained Models for Natural Language Processing: A Survey: https://arxiv.org/abs/2003.08271
[3]A Survey on Visual Transformer: https://arxiv.org/abs/2012.12556
[4]Efficient Transformers: A Survey: https://arxiv.org/abs/2009.06732
[5]A Survey of Transformers: https://arxiv.org/abs/2106.04554
- END -
