
复旦邱锡鹏教授:2020最新NLP预训练模型综述

新智元报道
新智元报道
编辑:SF
【新智元导读】本文该综述系统地介绍了nlp中的预训练模型,深入盘点了目前主流的预训练模型,提出了一种预训练模型的分类体系。
本篇文章主要介绍邱锡鹏老师在2020年发表的一篇预训练模型的综述:「Pre-trained Models for Natural Language Processing: A survey」。
该综述系统地介绍了nlp中的预训练模型。主要的贡献包括:
1、深入盘点了目前主流的预训练模型,如word2vec,ELMo,BERT等。
2、提出了一种预训练模型的分类体系,通过四种分类维度来划分目前已有的预训练模型。包括:
表征的类型,即:是否上下文感知
编码器结构,如:LSTM、CNN、Transformer
预训练任务类型,如:语言模型LM,带掩码的语言模型MLM,排列语言模型PLM,对比学习等
针对特定场景的拓展和延伸。如:知识增强预训练,多语言预训练,多模态预训练和模型压缩等
3、如何将PTMs学到的知识迁移到下游的任务中。
4、收集了目前关于PTMs的学习资料。
5、指明PTMs未来的研究方向,如:局限、挑战、建议。
由于篇幅原因,本文主要针对前面两点进行梳理,即「目前主流的预训练模型」和「预训练模型的分类体系」。

背景
「nlp、cv领域的传统方法极度依赖于手动特征工程」。例如nlp中的log-linear、CRF模型等,cv中各种抽取特征的模型,如sift特征等。深度学习中本质上是一种表示学习,能够一定程度上避免手动的特征工程。
究其原因,主要得益于深度学习中一系列很强大的特征提取器,如CNN、RNN、Transformer等,这些特征提取器能够有效地捕获原始输入数据中所蕴含的特点和规律。
nlp领域的发展比cv领域相对缓慢的原因是什么呢?
相比于cv领域,「nlp领域的劣势在于有监督数据集大小非常小」(除了机器翻译),导致深度学习模型容易过拟合,不能很好地泛化。

但是相反,nlp领域的优势在于,存在大量的无监督数据集,如果能够充分利用这类数据进行训练,那么势必能够提升模型的能力以及在下游任务中的表现。
nlp中的预训练模型就是这样一类能够在大规模语料上进行无监督训练,学习得到通用的语言表征,有助于解决下游任务的nlp模型。
那么什么是好的语言表征呢?
作者引用了Bengio的话,「好的表征能够表达非特定任务的通用先验知识,能够有助于学习器来解决AI任务」
"a good representation should express general-purpose priors that are not task-specific but would be likely to be useful for a learning machine to solve AI-tasks."
「nlp领域好的文本表征则意味着能够捕捉蕴含在文本中的隐性的语言学规则和常识性知识」
"capture the implicit linguistic rules and common sense knowledge hiding in text data, such as lexical meanings, syntactic structures, semantic roles, and even pragmatics."
目前主流的语言表征方式采用的是「分布式表征」(distributed representation),即低维实值稠密向量,每个维度没有特定的含义,但是「整个向量表达了一种具体的概念」。预训练模型是学习分布式表征的重要途径之一,它的好处主要包括:
在大规模语料上进行预训练能够学习到「通用的语言表示」,并有助于下游任务。
提供好的模型「参数初始化」,提高泛化性和收敛速度。
在「小数据集」上可以看作是一种「正则化」,防止过拟合。
预训练分类体系
下面将围绕四种分类方式来介绍目前主流的预训练模型,这些分类方式包括:
「表征的类型」,即:学习到的表征是否是上下文感知的;
「编码器结构」,如:LSTM、Transformer;
「预训练任务类型」,如LM,MLM,PLM;
「针对特定场景的拓展」,如跨语言预训练,知识增强,多模态预训练,模型压缩等。
这些分类方式是交叉的,也就是说同一个模型可以划分到多个分类体系下。
先一睹为快,这幅图是该综述的精华之一。下面将围绕上述4种分类体系来介绍预训练任务的工作。
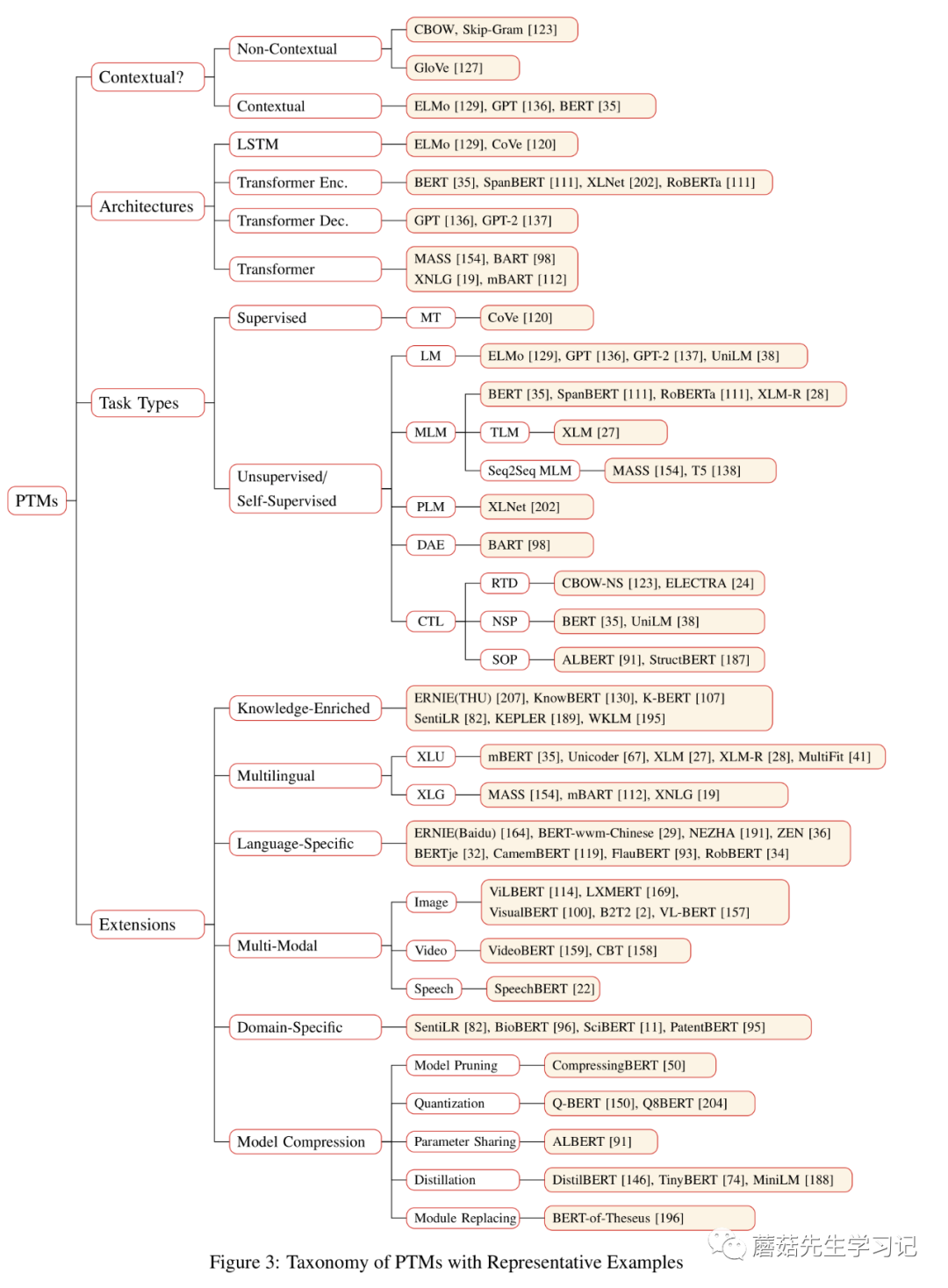
PTMs分类体系
2.1 表征类型
根据表征类型的不同可以分为:「非上下文感知的表征」 (Non-Contextual Representation)和「上下文感知的表征」(Contextual Representation)。上下文可以从字面上来理解,即:这个词所在的上下文,如句子,段落等。
「非上下文感知的词嵌入」。缺点是:「静态的」,不随上下文变化而变化,不管这个词位于哪个句子中,词的表示都是唯一的,无法解决一词多义问题。也无法解决「out-of-vocabulary」问题,这种情况下,一般只能通过character-level或者sub-word embedding来解决,即通过拆解词粒度为字符粒度来解决泛化性问题。

「上下文感知的词嵌入」:词嵌入会随着词所在的「上下文」不同而动态变化,能够解决一词多义问题。形式化的,给定文本
,每个token
是个词或子词,为了形成上下文感知的嵌入,
的表示需要「依赖于整个文本。」 即:
称为token
的上下文感知的词嵌入或动态词嵌入,因为其融入了整个文本中的「上下文信息」。
可以称之为「上下文感知的Encoder」。
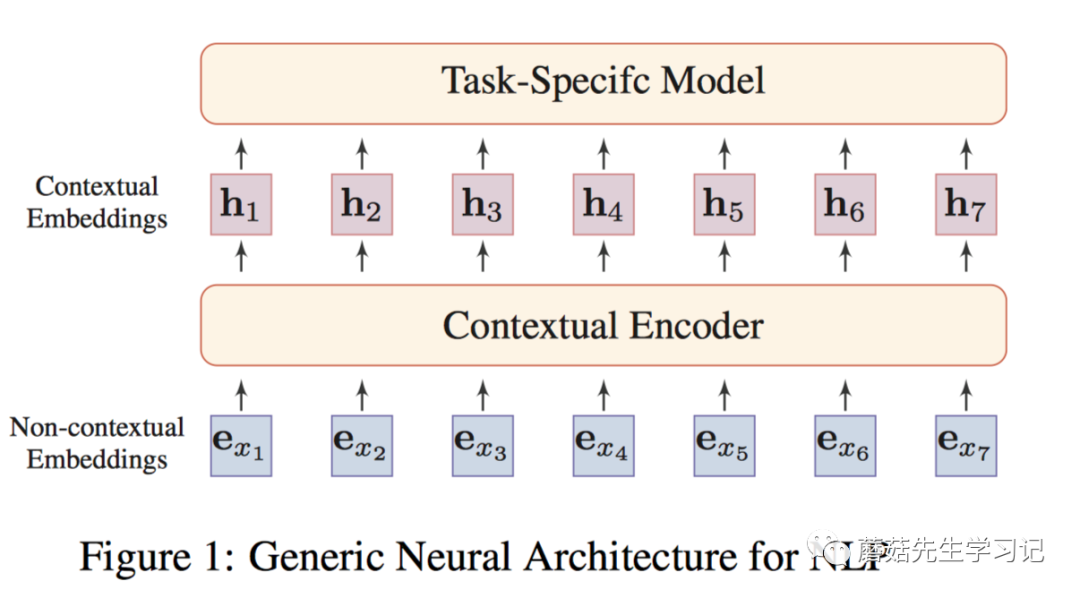
NLP通用Encoder架构
如上图,将非上下文和上下文结合在一起。形成通用的NLP任务的架构。
即:「非上下文感知的词嵌入」(如word2vec训练的embeddings),「输入到上下文感知的Encoder」(例如:Transformer,能够捕获句子中词之间的依赖关系),每个词的表示都会融入句子中其它上下文词的信息,得到「上下文感知的词嵌入」。同一个词在不同的语句中会得到不同的表示。
根据「表征类型的不同」,作者将预训练模型的发展「主要划分为了两代」:
第一代预训练模型由于「不是致力于解决下游任务」,主要致力于「学习好word embeddings本身,即不考虑上下文信息(context-free),只关注词本身的语义(semantic meanings),」,同时为了计算的考虑,这些模型通常非常浅。如「Skip-Gram, GloVe」等。由于是上下文无关的,这些方法通常无法捕获高阶的概念(high-level concepts),如一词多义,句法结构,语义角色,指代消解。代表性工作包括:「NNLM」,「word2vec」,「GloVe」。
第二代预训练模型致力于学习「contextual」 word embeddings。第一代预训练模型主要是word-level的。很自然的想法是将预训练模型拓展到「sentence-level」或者更高层次,这种方式输出的向量称为contextual word embeddings,即:依赖于上下文来表示词。此时,预训练好的「Encoder」需要在下游任务「特定的上下文中」提取词的表征向量。代表性工作包括两方面,
1、仅作为特征提取器(feature extractor)
特征提取器产生的上下文词嵌入表示,在下游任务训练过程中是「固定不变」的。相当于只是把得到的上下文词嵌入表示喂给下游任务的模型,作为「补充的特征」,只学习下游任务特定的模型参数。
代表性工作包括:
「CoVe」 用带注意力机制的「seq2seq」从「机器翻译任务」中预训练一个LSTM encoder。输出的上下文向量(CoVe)有助于提升一系列NLP下游任务的性能。
「ELMo」用「两层的Bi-LSTM」从「双向语言模型任务BiLM」(包括1个前向的语言模型以及1个后向的语言模型)中预训练一个「Bi-LSTM Encoder」,能够显著提升一系列NLP下游任务的性能。
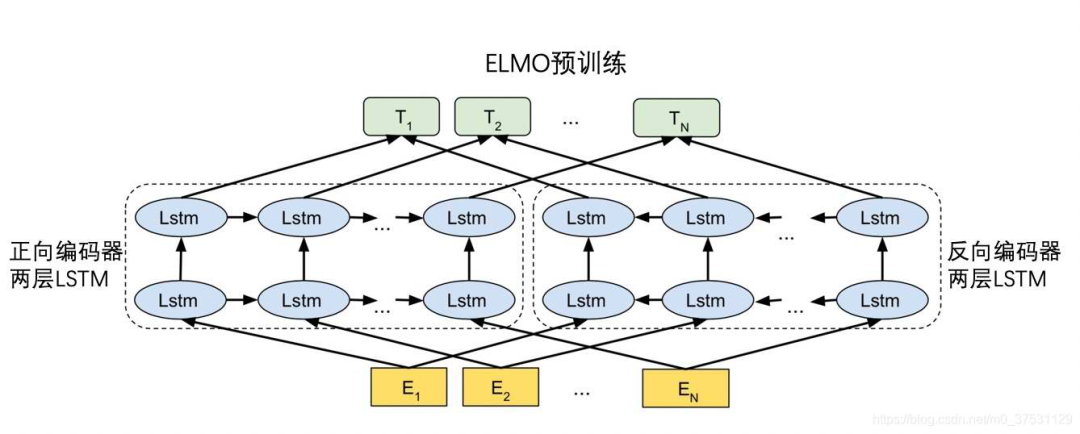
(此图仅为示例)
2、微调(fine-tuning)
在下游任务中,「上下文编码器」的参数也会进行微调,即:把预训练模型中的「encoder」模型结构都提供给下游任务,这样下游任务可以对「Encoder」的参数进行fine-tune。
代表性工作有:
「ULMFiT」(Universal Language Model Fine-tuning):通过在文本分类任务上微调预训练好的语言模型达到了state-of-the-art结果。这篇也被认为是「预训练模型微调」模式的开创性工作。
提出了3个阶段的微调:在通用数据上进行语言模型的预训练来学习「通用语言特征」;在目标任务所处的领域特定的数据上进行语言模型的微调来学习「领域特征」;在目标任务上进行微调。文中还介绍了一些微调的技巧,如区分性学习率、斜三角学习率、逐步unfreezing等。

「GPT」(Generative Pre-training) :使用「单向的Transformer」预训练「单向语言模型」。单向的Transformer里头用到了masked self-attention的技巧(相当于是Transformer原始论文里头的Decoder结构),即当前词只能attend到前面出现的词上面。之所以只能用单向transformer,主要受制于单向的预训练语言模型任务,否则会造成信息leak。

「BERT」(Bidirectional Encoder Representation from Transformer):使用双向Transformer作为Encoder(即Transformer中的Encoder结构),引入了新的预训练任务,带mask的语言模型任务MLM和下一个句子预测任务NSP。由于MLM预训练任务的存在,使得Transformer能够进行「双向」self-attention。
除此之外,还有些挺有意思的工作研究「上下文嵌入」中「所融入的知识」,如语言知识、世界知识等。
2.2 上下文编码器架构
对于上下文感知的Encoder,根据「架构」的不同,可以进一步分为「3种」,
「卷积模型」 (convolutional models):通过卷积操作来汇聚目标词的「邻居的局部信息」,从而捕获目标词的语义。优点在于容易训练,且能够很捕获「局部上下文信息」。典型工作是EMNLP 2014的文章TextCNN[13],卷积网络应用于nlp中特征提取的开创性工作。还比如Facebook在ICML2017的工作。
「序列模型」 (Sequential models):以序列的方式来捕获词的上下文信息。如LSTMs、GRUs。实践中,通常采取bi-directional LSTMs或bi-directional GRUs来同时捕获「目标词双向的信息」。
优点在于能够捕获「整个语句序列」上的依赖关系,缺点是捕获的「长距离依赖较弱」。典型工作是NAACL 2018的文章:「ELMo」。
「图模型」 (Graph-based models):将词作为图中的结点,通过预定义的词语之间的语言学结构(e.g., 句法结构、语义关系等)来学习词语的「上下文表示」。缺点是,构造好的图结构很困难,且非常依赖于专家知识或外部的nlp工具,如依存关系分析工具。典型的工作如:NAACL 2018上的工作。
作者还提到,「Transformer实际上是图模型的一种特例」。这个观点「醍醐灌顶」,也解释了Transformer应用于图神经网络中的可行性。

即:句子中的词构成一张全连接图,图中任意两个词之间都有连边,连边的权重衡量了词之间的关联,通过「self-attention来动态计算」,目标是让模型自动学习到图的结构(实际上,图上的结点还带了词本身的属性信息,如位置信息等)。
值得注意的是,Transformer在预训练中的应用一般会拆解为3种方式,「单向的」 (即:Transformer Decoder,使用了masked self-attention防止attend到future信息),如GPT, GPT-2;「双向的」 (即:Transformer Encoder,两侧都能attend),如Bert,XLBert等;或者「单双向都使用」(即:Transformer)。这些编码器的示意图如下:
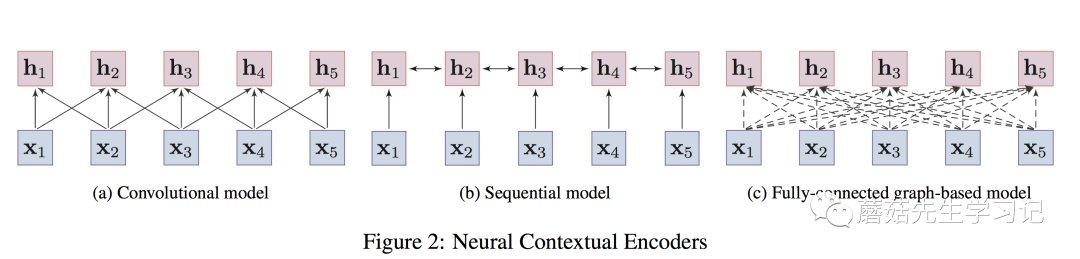
3种编码器结构
卷积编码器只能编码「局部的信息」到目标词上;
序列模型能够捕获整个语句上的依赖关系,但「长距离依赖」较弱;
图编码器任意两个词都有连接,能够捕获「任意词之间的依赖关系」,「不受距离影响。」
2.3 预训练任务
预训练任务对于学习通用的表征非常重要。甚至可以说是「最重要的一环」,引导着表征学习的整个过程。作者将预训练任务分为了3种,
「监督学习」 (supervised learning):从"输入-输出pair"监督数据中,学习输入到输出的映射函数。
「无监督学习」 (unsupervised learning):从无标签数据中学习内在的知识,如聚类、隐表征等。
「自监督学习」 (self-supervised learning):监督学习和无监督学习的折中。训练方式是监督学习的方式,但是输入数据的「标签是模型自己产生的」。
核心思想是,用输入数据的一部分信息以某种形式去预测其另一部分信息(predict any part of the input from other parts in some form)。例如BERT中使用的MLM就是属于这种,输入数据是句子,通过句子中其它部分的单词信息来预测一部分masked的单词信息。
在nlp领域,除了机器翻译存在大量的监督数据,能够采用监督学习的方式进行预训练以外(例如CoVe利用机器翻译预训练Encoder,并应用于下游任务),大部分预训练任务都是使用「自监督学习」的方式。下面围绕自监督学习,来介绍主流的预训练任务。
2.3.1 语言模型 (LM)
最著名的预训练任务是语言模型 (Language Modeling),语言模型是指一类能够求解句子概率的概率模型,通常通过概率论中的链式法则来表示整个句子各个单词间的联合概率。
形式化的,给定文本序列,
,其联合概率
可以被分解为:
其中,
是特殊的token,用于标识句子的开头 (此处应该也要有个标识句子结尾的特殊token)。
是词典。
上述式子是典型的概率论中的链式法则。链式法则中的每个部分
是给定上下文
条件下,当前要预测的词
在整个词典上的条件概率分布。这意味着「当前的单词只依赖于前面的单词,即单向的或者自回归的,这是LM的关键原理」,也是这种预训练任务的特点。因此,LM也称为auto-regressive LM or unidirectional LM。

对于上下文
,可以采用神经编码器
来进行编码,然后通过一个预测层来预测单词
的条件概率分布,形式化的:

其中,
是预测层 (比如softmax全连接层),用于输出当前单词
在整个词典上的条件概率分布。目标损失函数为:

LM的「缺点」在于,除了本身的信息之外,每个单词的编码「只融入了其所在句子左侧的上下文单词的信息」。而实际上,每个单词左右两侧上下文信息都是非常重要的。
为什么不能同时融入左右两侧的单词信息呢?
主要是因为我们的学习目标是预测下一个词
,如果让当前词同时融入两侧的信息,会造成」label的leak问题。
解决这个问题的方法是采用bidirectional LM (Bi-LM)即:
分别考虑从左到右的LM和从右到左的LM,这两个方向的LM是分开建模的
。
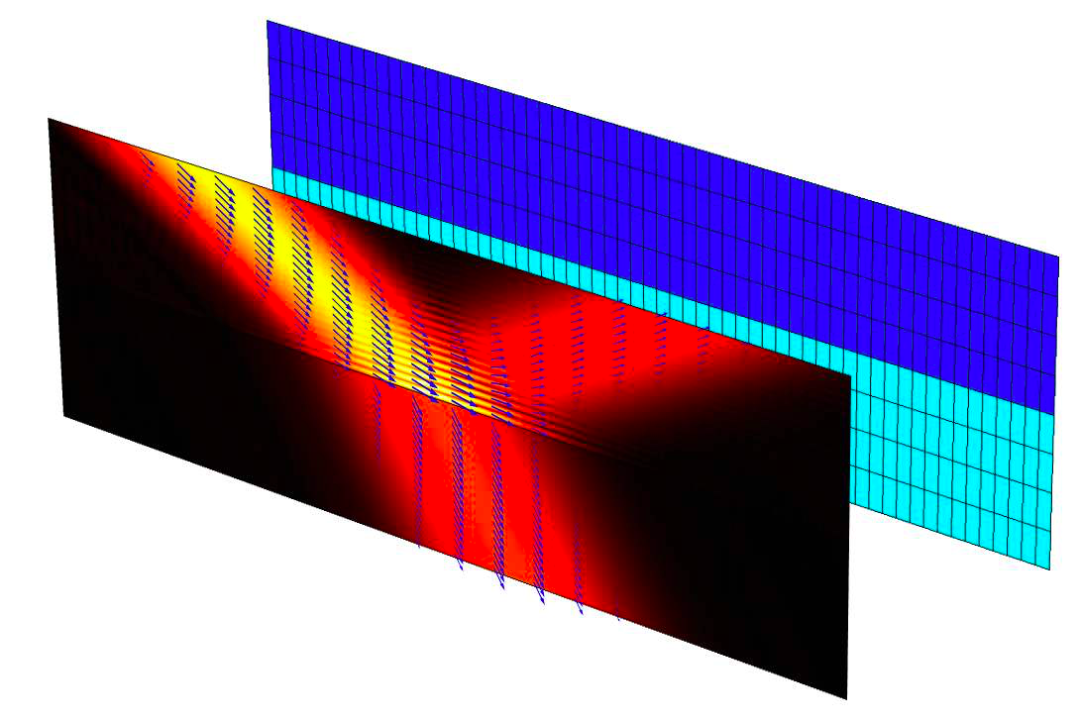
也就是说,训练过程中,「不会在一个LM预测下一个词的时候,用到另一个LM的encode的信息」。最后训练完成后,每个单词可以把两个
和
的「输出拼接」在一起来形成最终的表征。
2.3.2 带掩码的语言模型(MLM)
MLM主要是从BERT开始流行起来的,能够解决单向的LM的问题,进行双向的信息编码。MLM就好比英文中的完形填空问题,需要借助语句/语篇所有的上下文信息才能预测目标单词。

具体的做法就是随机mask掉一些token,使用特殊符号[MASK]来替换真实的token,这个操作相当于告知模型哪个位置被mask了,然后训练模型通过其它没有被mask的上下文单词的信息来预测这些mask掉的真实token。
具体实现时,实际上是个多分类问题,将masked的句子送入上下文编码器Transformer中进行编码,「[MASK]特殊token位置对应的最终隐向量」输入到softmax分类器进行真实的masked token的预测。损失函数为:

其中,
表示句子
中被mask掉的单词集合;
是除了masked单词之外的其它单词。
MLM的缺点有几大点:
会造成pre-training和fine-tuning之间的「gap」。在fine-tuning时是不会出现pre-training时的特殊字符[MASK]。为了解决这个问题,作者对mask过程做了调整,即:在随机挑选到的15%要mask掉的token里头做了进一步处理。
其中,80%使用[MASK] token替换目标单词;10%使用随机的词替换目标单词;10%保持目标单词不变。除了解决gap之外,还有1个好处,即:「预测一个词汇时」,模型并不知道输入对应位置的词汇是否为正确的词 (10%概率)。
这就迫使「模型更多地依赖于上下文信息去预测目标词」,并且赋予了模型一定的「纠错」能力。
MLM「收敛的速度比较慢」,因为训练过程中,一个句子只有15%的masked单词进行预测。
MLM不是标准的语言模型,其有着自己的「独立性假设」,即假设mask词之间是相互独立的。
自回归LM模型能够通过联合概率的链式法则来计算句子的联合概率,而MLM只能进行「联合概率的有偏估计」(mask之间没有相互独立)。
MLM的变体有很多种。
2.4 预训练的延伸方向
预训练模型延伸出了很多新的研究方向。包括了:
基于「知识增强」的预训练模型,Knowledge-enriched PTMs
「跨语言或语言特定的」预训练模型,multilingual or language-specific PTMs
「多模态」预训练模型,multi-modal PTMs
「领域特定」的预训练模型,domain-specific PTMs
「压缩」预训练模型,compressed PTMs
2.4.1 基于知识增强的预训练模型
PTMs主要学习通用语言表征,但是缺乏领域特定的知识。因此可以考虑把外部的知识融入到预训练过程中,让模型同时捕获「上下文信息」和「外部的知识」。
早期的工作主要是将知识图谱嵌入和词嵌入一起训练。从BERT开始,涌现了一些融入外部知识的预训练任务。代表性工作如:
「SentiLR」: 引入word-level的语言学知识,包括word的词性标签(part-of-speech tag),以及借助于SentiWordNet获取到的word的情感极性(sentiment polarity),然后将MLM拓展为label-aware MLM进行预训练。
包括:给定sentence-level的label,进行word-level的知识的预测 (包括词性和情
感极性); 基于语言学增强的上下文进行sentence-level的情感倾向预测。
作者的做法挺简单的,就是把sentence-level label或word-level label进行embed
ding然后加到token embedding/position embedding上,类似BERT的做法。然
后,实验表明该方法在下游的情感分析任务中能够达到state-of-the-art水平。
「ERNIE (THU)」: 将知识图谱上预训练得到的entity embedding融入到文本中相对应的entity mention上来提升文本的表达能力。
具体而言,先利用TransE在KG上训练学习实体的嵌入,作为外部的知识。然后用
Transformer在文本上提取文本的嵌入,将文本的嵌入以及文本上的实体对应的KG
实体嵌入进行异构信息的融合。学习的目标包括MLM中mask掉的token的预测;
以及mask文本中的实体,并预测KG上与之对齐的实体。
类似的工作还包括KnowBERT, KEPLER等,都是通过实体嵌入的方式将知识图谱上的结构化信息引入到预训练的过程中。

「K-BERT」 : 将知识图谱中与句子中的实体相关的三元组信息作为领域知识注入到句子中,形成树形拓展形式的句子。然后可以加载BERT的预训练参数,不需要重新进行预训练。
也就是说,作者关注的不是预训练,而是直接将外部的知识图谱信息融入到句子
中,并借助BERT已经预训练好的参数,进行下游任务的fine-tune。这里难点在
于,异构信息的融合和知识的噪音处理,需要设计合适的网络结构融合不同向量空
间下的embedding;以及充分利用融入的三元组信息(如作者提到的soft position
和visible matrix)。
2.4.2 跨语言或语言特定的预训练模型
这个方向主要包括了跨语言理解和跨语言生成这两个方向。
对于「跨语言理解」,传统的方法主要是学习到多种语言通用的表征,使得同一个表征能够融入多种语言的相同语义,但是通常需要对齐的弱监督信息。但是目前很多跨语言的工作不需要对齐的监督信息,所有语言的语料可以一起训练,每条样本只对应一种语言。代表性工作包括:
「mBERT」:在104种维基百科语料上使用MLM预训练,即使没有对齐最终表现也非常不错,没有用对齐的监督信息。
「XLM」:在mBERT基础上引入了一个翻译任务,即:目标语言和翻译语言构成的双语言样本对输入到翻译任务中进行对齐目标训练。这个模型中用了对齐的监督信息。
「XLM-RoBERTa」:和mBERT比较像,没有用对齐的监督信息。用了更大规模的数据,且只使用MLM预训练任务,在XNLI, MLQA, and NER.等多种跨语言benchmark中取得了SOA效果。

对于「跨语言生成」,一种语言形式的句子做输入,输出另一种语言形式的句子。比如做机器翻译或者跨语言摘要。和PTM不太一样的是,PTM只需要关注encoder,最后也只需要拿encoder在下游任务中fine-tune,在跨语言生成中,encoder和decoder都需要关注,二者通常联合训练。代表性的工作包括:
「MASS」:微软的工作,多种语言语料,每条训练样本只对应一种语言。在这些样本上使用Seq2seq MLM做预训练。在无监督方式的机器翻译上,效果不错。
「XNLG」:使用了两阶段的预训练。第一个阶段预训练encoder,同时使用单语言MLM和跨语言MLM预训练任务。第二个阶段,固定encoder参数,预训练decoder,使用单语言DAE和跨语言的DAE预训练任务。这个方法在跨语言问题生成和摘要抽取上表现很好。

2.4.3 多模态预训练模型
多模态预训练模型,即:不仅仅使用文本模态,还可以使用视觉模态等一起预训练。目前主流的多模态预训练模型基本是都是文本+视觉模态,采用的预训练任务是visual-based MLM,包括masked visual-feature modeling and visual-linguistic matching两种方式,即视觉特征掩码和视觉-语言语义对齐和匹配。这里头关注几个关于image-text的多模态预训练模型。
这类预训练模型主要用于下游视觉问答VQA和视觉常识推理VCR等。
「双流模型」:在双流模型中文本信息和视觉信息一开始先经过两个独立的Encoder(Transformer)模块,然后再通过跨encoder来实现不同模态信息的融合,代表性工作如:NIPS 2019, 「ViLBERT」和EMNLP 2019, 「LXMERT」。
「单流模型」:在单流模型中,文本信息和视觉信息一开始便进行了融合,直接一起输入到Encoder(Transformer)中,代表性工作如:「VisualBERT」,「ImageBERT」和「VL-BERT」。
2.4.4 模型压缩方法
预训练模型的参数量过大,模型难以部署到线上服务。而模型压缩能够显著减少模型的参数量并提高计算效率。压缩的方法包括:
「剪枝」(pruning):去除不那么重要的参数(e.g. 权重、层数、通道数、attention heads)
「量化」(weight quantization):使用占位更少(低精度)的参数
「参数共享」(parameter sharing):相似模型单元间共享参数
「知识蒸馏」(knowledge diistillation):用一些优化目标从原始的大型teacher模型中蒸馏出一个小的student模型。通常,teacher模型的输出概率称为soft label,大部分蒸馏模型让student去拟合teacher的soft label来达到蒸馏的目的。
蒸馏之所以work,核心思想是因为「好模型的目标不是拟合训练数据,而是学习
如何泛化到新的数据」。所以蒸馏的目标是让学生模型学习到教师模型的泛化能
力,理论上得到的结果会比单纯拟合训练数据的学生模型要好。
当然,模型压缩通常还会结合上述多种方法,比如剪枝+蒸馏的融合方法。常见的知识蒸馏的 PTMs如下表所示。
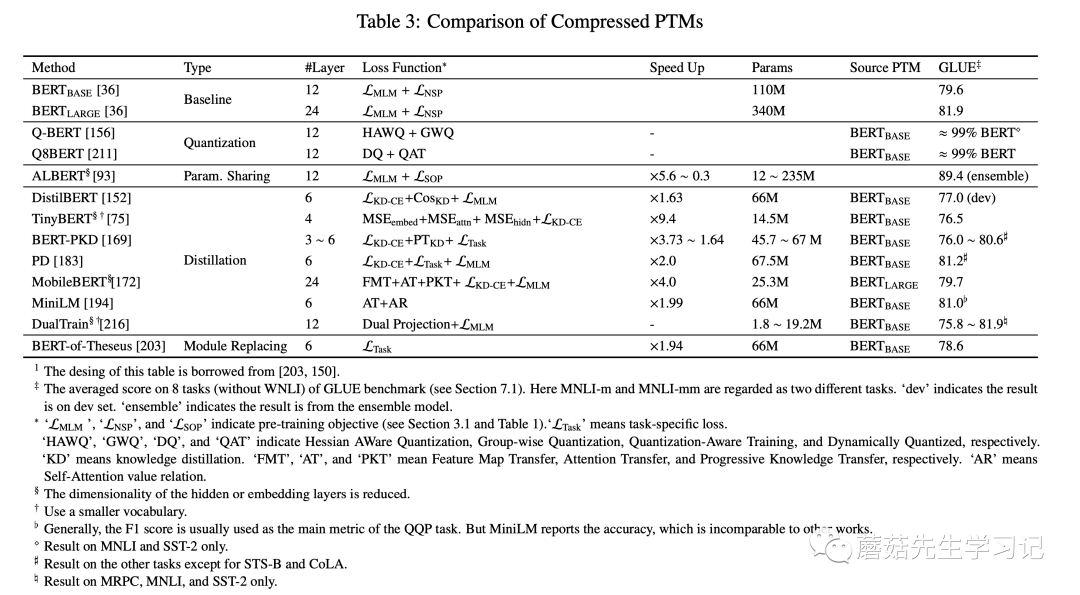
模型压缩方法
总结
本文是对邱锡鹏老师2020年的一篇预训练模型survey的简单梳理。主要针对survey中提到的四大类预训练模型的分类体系做了梳洗,「这四大类预训练模型分类体系为:」
表征的类型,即:是否上下文感知;
编码器结构,如:LSTM、CNN、Transformer;
预训练任务类型,如:语言模型LM,带掩码的语言模型MLM,排列语言模型PLM,对比学习等。
针对特定场景的拓展和延伸。如:知识增强预训练,多语言预训练,多模态预训练和模型压缩等。
编者注:本文有大量的参考链接,如需参考请点击阅读原文,谢谢!

