
复旦邱锡鹏组最新综述:A Survey of Transformers!

极市导读
本文将重心放在对Transformer结构(模块级别和架构级别)的改良上,包括对Attention模块的诸多改良、各种位置表示方法等。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
转眼Transformer模型被提出了4年了。依靠弱归纳偏置、易于并行的结构,Transformer已经成为了NLP领域的宠儿,并且最近在CV等领域的潜能也在逐渐被挖掘。尽管Transformer已经被证明有很好的通用性,但它也存在一些明显的问题,例如:
1、核心模块自注意力对输入序列长度有平方级别的复杂度,这使得Transformer对长序列应用不友好。例如一个简单的32x32图像展开就会包括1024个输入元素,一个长文档文本序列可能有成千上万个字,因此有大量现有工作提出了轻量化的注意力变体(例如稀疏注意力),或者采用“分而治之”的思路(例如引入recurrence);
2、与卷积网络和循环网络不同,Transformer结构几乎没有什么归纳偏置。这个性质虽然带来很强的通用性,但在小数据上却有更高的过拟合风险,因此可能需要引入结构先验、正则化,或者使用无监督预训练。
近几年涌现了很多Transformer的变体,各自从不同的角度来改良Transformer,使其在计算上或者资源需求上更友好,或者修改Transformer的部分模块机制增大模型容量等等。但是,很多刚接触Transformer的研究人员很难直观地了解现有的Transformer变体,例如前阵子有读者私信我问Transformer相关的问题,聊了一会儿才发现他不知道Transformer中的layer norm也有pre-LN和post-LN两种变体。因此,我们认为很有必要对现有的各种Transformer变体做一次整理,于是产生了一篇survey ,现在挂在了arxiv上:http://arxiv.org/abs/2106.04554。
在这篇文章之前,已经有一些很好的对PTM和Transformer应用的综述(例如https//arxiv.org/abs/2003.082711和https://arxiv.org/abs/2012.12556),在这篇文章中,我们把重心放在对Transformer结构(模块级别和架构级别)的改良上,包括对Attention模块的诸多改良、各种位置表示方法等。
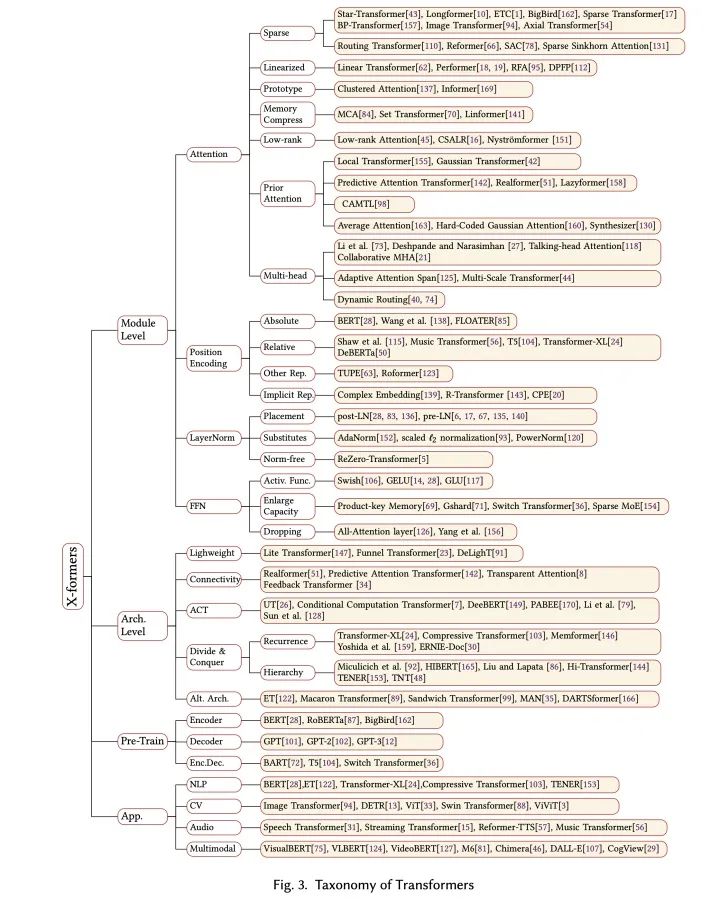
值得一提的是,Google去年放出过一篇关于Transformer的综述(Efficient Transformers: A Survey,https://arxiv.org/abs/2009.06732),主要关注了Attention模块的效率问题(这在我们的综述中也覆盖了)。虽然是一篇很好的review,但是笔者认为它对于Attention变体的分类有一些模糊,例如作者将Compressive Transformer、ETC和Longformer这一类工作、以及Memory Compressed Attention都归类为一种基于Memory的改进,笔者认为memory在这几种方法中各自有不同的含义,使用Memory来概括很难捕捉到方法的本质。我们的文章对这几个方法有不同的分类:
1、Compressive Transformer是一种“分而治之”的架构级别的改进,相当于在Transformer基础上添加了一个wrapper来增大有效上下文的长度;
2、ETC和Longformer一类方法是一种稀疏注意力的改进,主要思路是对标准注意力代表的全链接二分图的连接作稀疏化的处理;
3、Set Transformer、Memory Compressed Attention、Linformer对应一种对KV memory压缩的方法,思路是缩短注意力矩阵的宽。
我们希望这篇文章可以给关注Transformer的同行、朋友们提供一个参考,欢迎大家阅读:
http://arxiv.org/abs/2106.04554
如果有任何疑问或宝贵建议,欢迎通过评论、邮件或私信反馈给我们。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~

# CV技术社群邀请函 #
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
