
LeCun点赞华人女科学家——使用能量模型替代Softmax函数!

极市导读
本文证明了可以将任何预训练神经网络的softmax置信度替换为能量函数! >>明日直播!田值:实例分割创新式突破BoxInst,仅用Box标注,实现COCO 33.2AP!
Softmax置信度得分应该是大家再熟悉不过的加在神经网络最后面的一个操作。
1 论文一作

Sharon Yixuan Li,威斯康星大学麦迪逊分校计算机科学系助理教授,本科就读于上海交通大学,博士毕业于康奈尔大学,博士后一年在斯坦福大学计算机系度过,曾两次在Google AI实习,并在Facebook AI担任过研究科学家。
深度学习中的不确定性估计和分布外检测;
鲁棒数据不规则性和分布外泛化;
在医疗和计算机视觉中具有不确定性的深度学习。
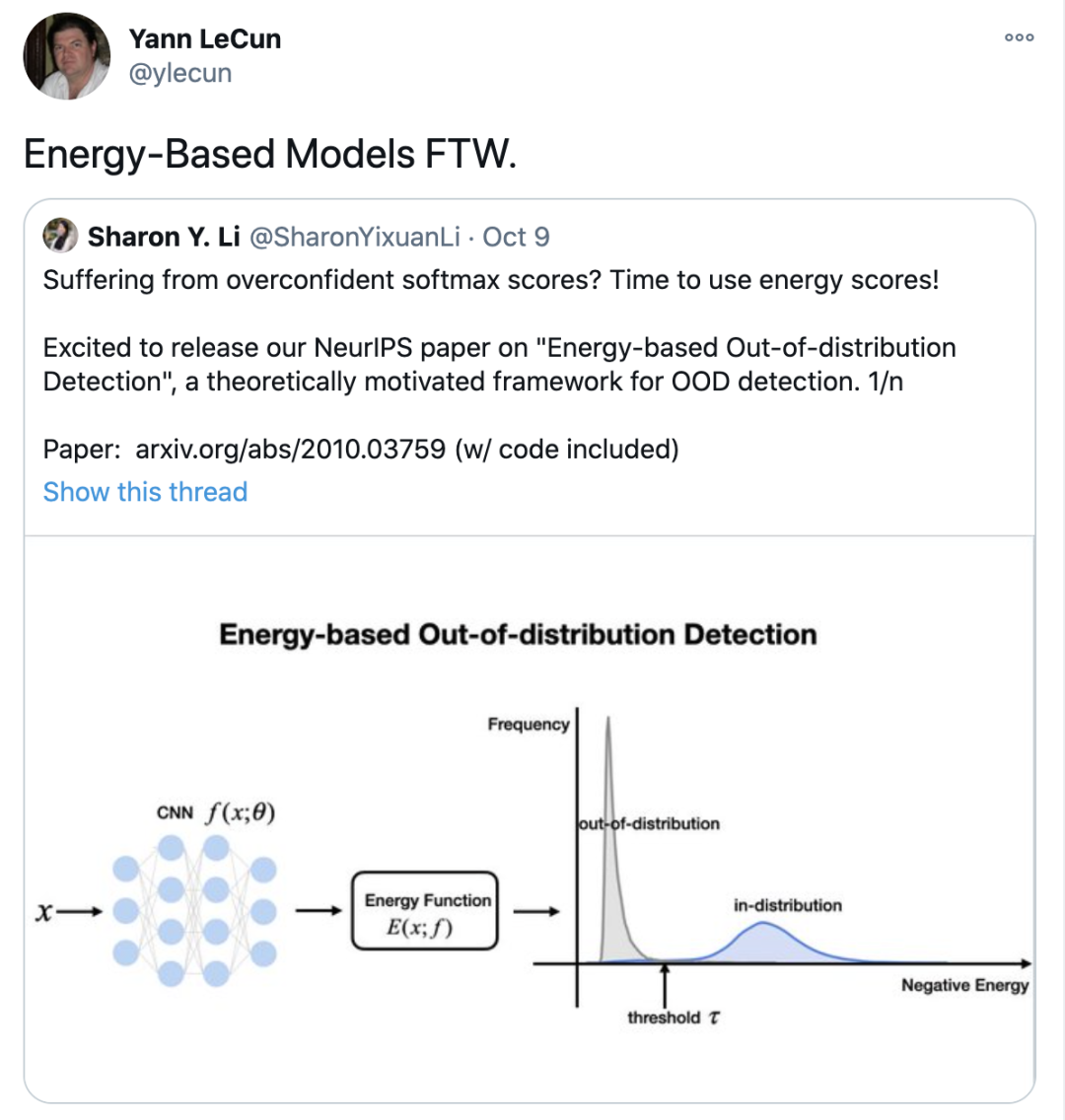
2 什么是能量模型(EBM)



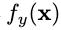 对应于第y类标签的logit值,联立上式,可以将输入
对应于第y类标签的logit值,联立上式,可以将输入 的能量值表示为负的,这样就在原始神经网络分类器和能量模型之间建立起了联系,我们可以用softmax函数的分母来表示当前输入样本的能量,并且进行后续的异常检测操作。
的能量值表示为负的,这样就在原始神经网络分类器和能量模型之间建立起了联系,我们可以用softmax函数的分母来表示当前输入样本的能量,并且进行后续的异常检测操作。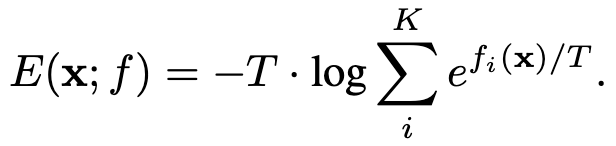
3 能量模型指导下的OOD
能量异常分数
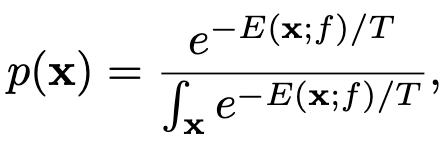
 分母)在输入空间很难可靠的估计,但是其不会对输入数据产生影响,所以可以直接对上式左右取对数:
分母)在输入空间很难可靠的估计,但是其不会对输入数据产生影响,所以可以直接对上式左右取对数: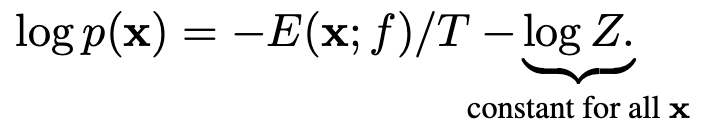
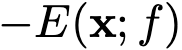 实际上与对数似然函数线性对齐,这有助于提高异常检测的性能,具有较高能量(似然函数值较小)的数据会被判别为异常样本。 构成异常检测器
实际上与对数似然函数线性对齐,这有助于提高异常检测的性能,具有较高能量(似然函数值较小)的数据会被判别为异常样本。 构成异常检测器 :
:
 为能量阈值,从正常样本数据分布统计得到。
为能量阈值,从正常样本数据分布统计得到。能量分数 VS Softmax分数

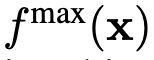 倾向于得到一个较高的置信分数,这种倾向将导致评分函数不再与概率密度
倾向于得到一个较高的置信分数,这种倾向将导致评分函数不再与概率密度 成正比。
成正比。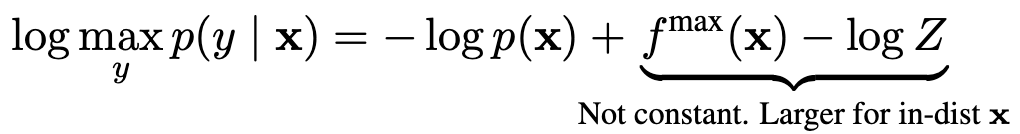
 不受这类偏移影响,将始终与概率密度对齐,进而提高了模型对异常样本的检测能力。
不受这类偏移影响,将始终与概率密度对齐,进而提高了模型对异常样本的检测能力。能量边界学习
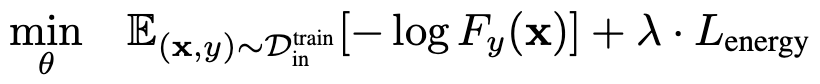
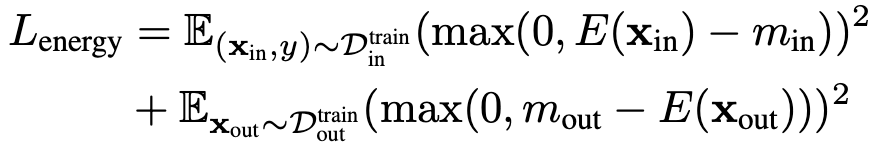
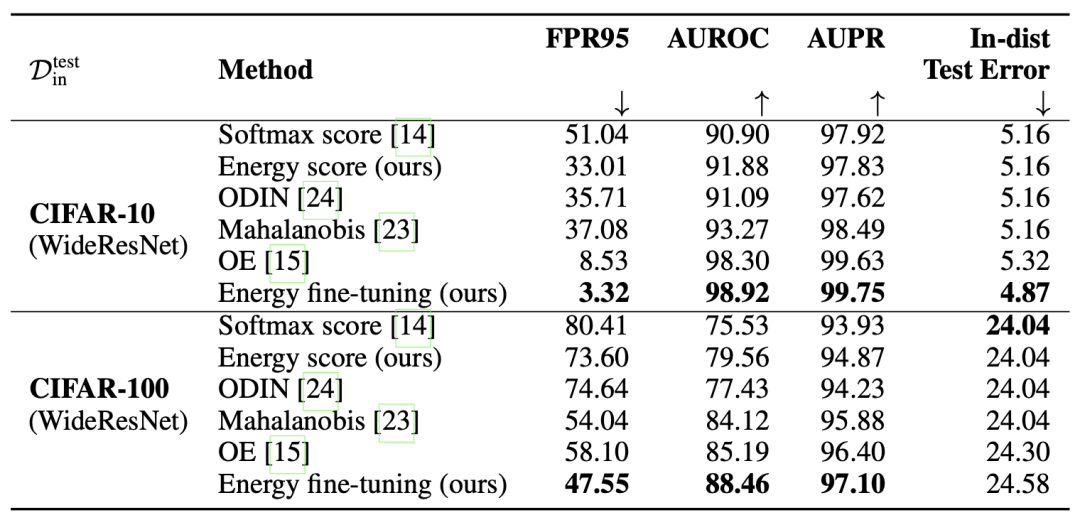
4 实验结果
Softmax对比实验

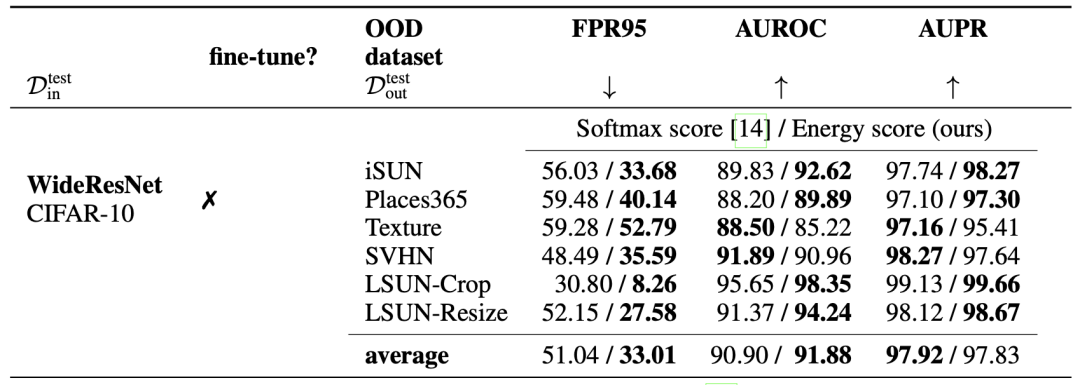
模型微调实验
5 总结
参考
推荐阅读

评论