
(十八)基于RASA开始中文机器人实现机制
作者简介
作者:孟繁中
原文:https://zhuanlan.zhihu.com/p/339722352
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study

前文介绍了基于RASA的总体架构,本文着重介绍一下实现细节。
机器人管理概述
框架是多租户SAAS系统,每个用户可以创建多个机器人,每个机器人关联独立的语料库,机器人能力,话术流程,在RASA中对应一个RASA运行实例。机器人管理应用系统需要给用户提供最精简的配置UI,且可以完成Rasa需要的相关配置。然后将这些数据转成Rasa可以识别的yaml格式,保存在HDFS中。RASA到HDFS中获取配置数据,进行训练,测试。测试通过后将模型保存在HDFS中,部署上线时候,在启动一个容器,加载HDFS中的模型,并启动RASA服务。对话管理应用系统接收用户消息,调用RASA endpoint完成响应消息预测。
机器人创建
应用系统中创建唯一标识
调用rasa init接口,在rasa中初始化机器人
在git中创建版本库
在hdfs分配存储路径和空间
在train server上启动docker
机器人话术设计
RASA本身支持是多轮对话,需要做一个可视化流程图,然后转成Rasa的story和rule的配置。检索型机器人,少量Faq可以直接使用rasa的response selector完成。但是海量知识库的检索,需要单独系统,这个后续在机器人扩展能力里面再阐述。
因为机器人创建的时候,已经分配了训练数据的存储路径,话术设计的内容可以直接生成配置文件放在训练数据的路径里面。
机器人训练
训练数据生成以后,用户可以启动训练。每次数据训练,会自动在git中生成一个版本节点。训练是一个异步任务,放入对话管理平台调度服务统一调度。训练完成后,可以直接启动测试。这时候rasa的服务是在训练服务器启动。当训练新数据的时候,必须停止当前的测试任务。
机器人上线
测试通过后,启动上线。如果是第一次上线,需要在生产环境创建容器,然后使用新训练的模型,启动生产环境对应的docker。如果是升级更新,只是使用新模型重启docker。
机器人能力扩展
假如,我们已经有了KBQA的服务,那么用户要开通这个服务,那只需要点击开通,然后用户需要选择哪类问题由KBQA回答,那么对话管理服务,要做的事情,根据用户提供的问题分类训练一个意图,然后配置规则将这个意图关联到KBQA Action上。能力扩充就完成了。用户关闭KBQA,在配置文件中删除这个意图就可以了。
关于如何创建KBQA服务,如何使用用户数据Fine turn模型等,后续会按不同的能力单独讨论。
机器人领域动态扩充
前面我们讲的训练数据,都基于一个前提,那就是字典或者说语言模型是固定的。我们在此基础上扩展训练数据。
当我们使用一个新的领域的时候,会有很多字库中不存在的词,这个时候需要Fine turn语言模型和字库。比如我们使用的分词是语言模型分词,用的BERT作为基础Featurizer,因此,机器人领域扩充是Fineturn BERT模型。我们在训练服务器上单独启动BERT服务,由用户传入训练数据,然后加入训练调度队列,成功后生成模型文件,供RASA启动的时候引用。
在线学习
在线学习,训练数据和上线的流程前面已经有了,这里关键是错误回答的标注问题。如何根据用户的标注,重新更新训练数据。
业务能力集成
业务模块提供接口,rasa action server调用自定义action去调用业务模块的接口,完成业务能力集成。
算法层架构图
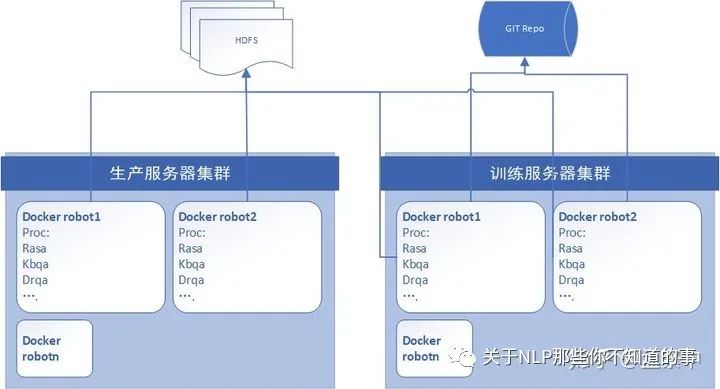
1、生产服务器和训练服务器通过HDFS做文件共享,训练服务器从HDFS取训练数据进行训练,生成模型,模型文件依旧保存于HDFS,而生产服务器从HDFS取训练好的模型应用于推理。
2、每个robot使用的模型都可能不同,因此使用容器隔离,每个机器人启动一个容器,容器内运行自己的rasa及各个能力组件。
3、语言模型也在各自的容器内训练,启动的时候使用各自的语言模型。
RASA相关配置
nlu和dm的配置
nlu和dm的配置都在config.yml里面,语言模型采用BERT,主要分了器使用DIET。
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: zh
pipeline:
- name: LanguageModelTokenizer #需要改代码,去掉不支持中文的限制
- name: RegexFeaturizer
- name: LexicalSyntacticFeaturizer
- name: LanguageModelFeaturizer
model_name: bert
model_weights: bert-base-chinese
- name: DIETClassifier
epochs: 100
- name: EntitySynonymMapper
- name: ResponseSelector
epochs: 100
- name: FallbackClassifier
threshold: 0.3
ambiguity_threshold: 0.1
policies:
- name: MemoizationPolicy
- name: TEDPolicy
max_history: 5
epochs: 100
- name: RulePolicyTracker Store配置
Tracker Store主要功能是存储用户对话,我们使用PostgreSQL存储。Rasa默认就支持。PostgreSQL的参数在endpoints.yml中配置。
endpoints.yml
tracker_store:
type: SQL
dialect: "postgresql" # the dialect used to interact with the db
url: "postgres"
db: "rasa" # path to your db
username: # username used for authentication
password: # password used for authentication
query: # optional dictionary to be added as a query string to the connection URL
driver: my-driverEvent Broker
事件代理主要作用是讲机器人的对话异步传给其他服务,比如将机器人的消息转发给ES等。Event Broker支持kafka,数据库方式等,我们采用kafka。配置也在endpoints.yml中配置。
endpoints.yml
event_broker:
type: kafka
security_protocol: SASL_PLAINTEXT
topic: topic
url: localhost
sasl_username: username
sasl_password: passwordLock Store配置
Rasa使用token锁定机制来确保以正确的顺序处理给定会话ID的传入消息,并在消息处于活动状态时锁定会话。这意味着多个Rasa服务器可以作为复制服务并行运行,并且客户端在发送给定会话ID的消息时不一定需要寻址同一节点。我们采用Redis作为Lock存储。redis参数的配置,也是在endpoints.yml中。
lock_store:
type: "redis"
url: <url of the redis instance, e.g. localhost>
port: <port of your redis instance, usually 6379>
password: <password used for authentication>
db: <number of your database within redis, e.g. 0>
key_prefix: <alphanumeric value to prepend to lock store keys>模型加载路径
模型保存在hdfs上,为了和rasa服务解耦,我们在rasa中使用从server加载,这样模型保存以后,启动一个http服务,通过http服务可以下载模型,然后再rasa的endpoints.yml中配置server地址
models:
url: http://model-server.com/models/default
wait_time_between_pulls: 10 # In seconds, optional, default: 100Action Server配置
需要运行ActionServer才可以调用自定义Action。Actionserver的配置也在endpoints.yml里面。
action_endpoint:
url: "http://localhost:5055/webhook"Action server的启动方式
rasa run actions启动Action Server的时候,需要在配置文件的路径下,且里面必须包含actions路径,如典型一个机器人的配置如下,其中helloworld.py就是一个自定义action。
├── actions
│ ├── helloworld.py
│ └── __init__.py
├── config.yml
├── credentials.yml
├── data
│ ├── nlu.yml
│ ├── rules.yml
│ └── stories.yml
├── domain.yml
├── endpoints.yml
├── models
│ └── 20201228-084711.tar.gz
└── tests
└── test_stories.yml自定义action
KBQA、DrQA 、闲聊机器人、检索机器人、业务系统相关查询,都是基于自定义Action实现的。actions路径下有如下文件:
├── actions
│ ├── drqa_action.py
│ ├── kbqa_action.py
│ ├── chat_action.py
│ ├── retrival_action.py
│ ├── business_action.py
│ └── __init__.py这些自定义action主要是实现了rasa_sdk的api和各个能力之间的适配。具体能力的实现在不同的系统中,后续我们会依次介绍各个系统的实现。
机器人能力扩展开发规范
由于机器人能力是动态扩展的,而且要嵌入到rasa系统中,因此要有遵循一定规则:
支持命令行启动训练和推理
支持http调用,并满足统一的接口规范
支持训练数据和模型远程存储