
NLP模型读不懂人话?微软AdaTest挑错效率高5倍

来源:新智元 本文约3500字,建议阅读10+分钟 2022年5月底,微软的AI研发人员在预印本网站发表论文,提出了调试NLP模型的全新路径AdaTest。

自然语言处理(NLP)模型读不懂人话、将文本理解为相反的意思,是业界顽疾了。
现在微软表示,开发出解决此弊的方法。
微软开发AdaTest方法来测试NLP模型
可作为跨越各种应用基础的大型模型,或称平台模型的进展已经大大改善了AI处理自然语言的能力。但自然语言处理(NLP)模型仍然远不完美,有时会以令人尴尬的方式暴露缺陷。
例如有个顶级的商用模型,将葡萄牙语中的「我不推荐这道菜」翻译成英语中的「我非常推荐这道菜」。
这些失败之所以继续存在,部分原因是寻找和修复NLP模型中的错误很难,以至于严重的错误影响了几乎所有主要的开源和商业NLP模型。
目前寻找和修复NLP模型错误的方法有两种:或是用户驱动的,或是自动的。
用户驱动的方法很灵活,可以测试NLP模型行为的任何方面。但此方法依赖于人类极为参差不齐的想象且辨识错误的能力,并且是极度劳动密集型的,以至于在实践中只有一小部分的输入数据量可用来测试。
另一方面,自动方法很快速,因此可以处理输入数据的很大一部分。然而,由于缺乏人类的把控,它们只能在非常有限的情况下测试一个模型是对还是错,例如当模型处理有轻微变化的输入措辞时,其预测结果就会出现不一致。

微软的研究者们认为,像GPT-3这样的现代大型语言模型(LLMs),为业界提供了一个机会,可以尝试将用户驱动方法和自动方法的优势结合起来,让用户来定义被测试的模型应该做什么,同时利用现代大型语言模型的生成能力,在特定的模型行为类别中生成大规模的测试。
微软研究者将此类人机结合的路径,称之为「适应性测试与去Bug」,缩写为AdaTest。
通过AdaTest,一个大型的语言模型被赋予了重负:生成大量的、针对受测模型中的错误的测试。
而人工干涉则通过选择有效的测试、并将它们组织到语义相关的主题中,来引导语言模型的生成工作。
这种来自人工的指导极大地提高了语言模型的生成性能,并将其引向目标领域。
因为这些测试实际上是一种标记数据的形式,它们不仅可以识别NLP模型的错误,而且可以用来在类似于传统软件开发的迭代调试循环中,修复NLP模型的错误。
AdaTest为专业用户提供了显著的效率提升,同时又足够简单,可以让没有编程背景的普通人也能有效使用。
这意味着专业用户和普通用户都能更好地理解和控制在NLP模型一系列场景中的行为,这不仅使AI系统表现更好,而且使AI系统更有效呼应用户需求。
用测试循环发现漏洞
AdaTest模式由一个内部测试循环和一个外部调试循环组成,前者用于发现错误,后者用于修复错误。
虽然这项任务看起来很简单,但即使是市面上的SOTA模型们也常出现失误。
比如有的SOTA模型会将「我认为我一生中没有过更美好的时光」的双重否定句归类为情绪负面,或者篓子更大的将「我是一个少数族裔」这句话归类为情绪负面。
这两种情况都是在市面上商业模型真实发生过的失误。
为了证明AdaTest可以发现和修复错误,微软的研究团队演示了如何测试并修复NLP模型的文本公平性失误。
NLP模型的文本公平性失误,即是在一段文本中对特定属性群体的中性描述,可能导致NLP模型的文本情感分析功能出错,错误地降低文本的情感权重。也就是说,模型可能会更负面地对待特定群体的描述。
在测试循环中,微软研究者从一组关于各种身份的文本单元测试开始,并将这组测试标记为「敏感」。这些最初的例子并没有发现任何模型的错误。
不过AdaTest方法用GPT-3生成了大量语料类似的暗示性测试,以此来突出测试对象模型潜藏的bug。
虽然产生了数以百计的测试,但干预的人员只需要审查前几个错误或接近错误的测试。
然后,人工干预忽略那些并没有真正犯错的测试结果,并将其他有效的测试结果添加到当前主题中,也偶尔将它们组织到其他的子主题中去
这些经过人工过滤的测试结果会包含在下一轮输入的语言模型提示中,如此将下一组输入数据的处理结果,推向用户关注点和模型出错bug之间的交叉点。
重复这一内部测试循环,可以让NLP模型从不出错开始,慢慢地暴露出越来越显著的错误和bug。
因此,即使用户自己不能找到模型的故障,他们也可以从一小部分通过的测试开始,然后迅速与NLP模型迭代,产生一大批测试,揭示出被测模型的错误。
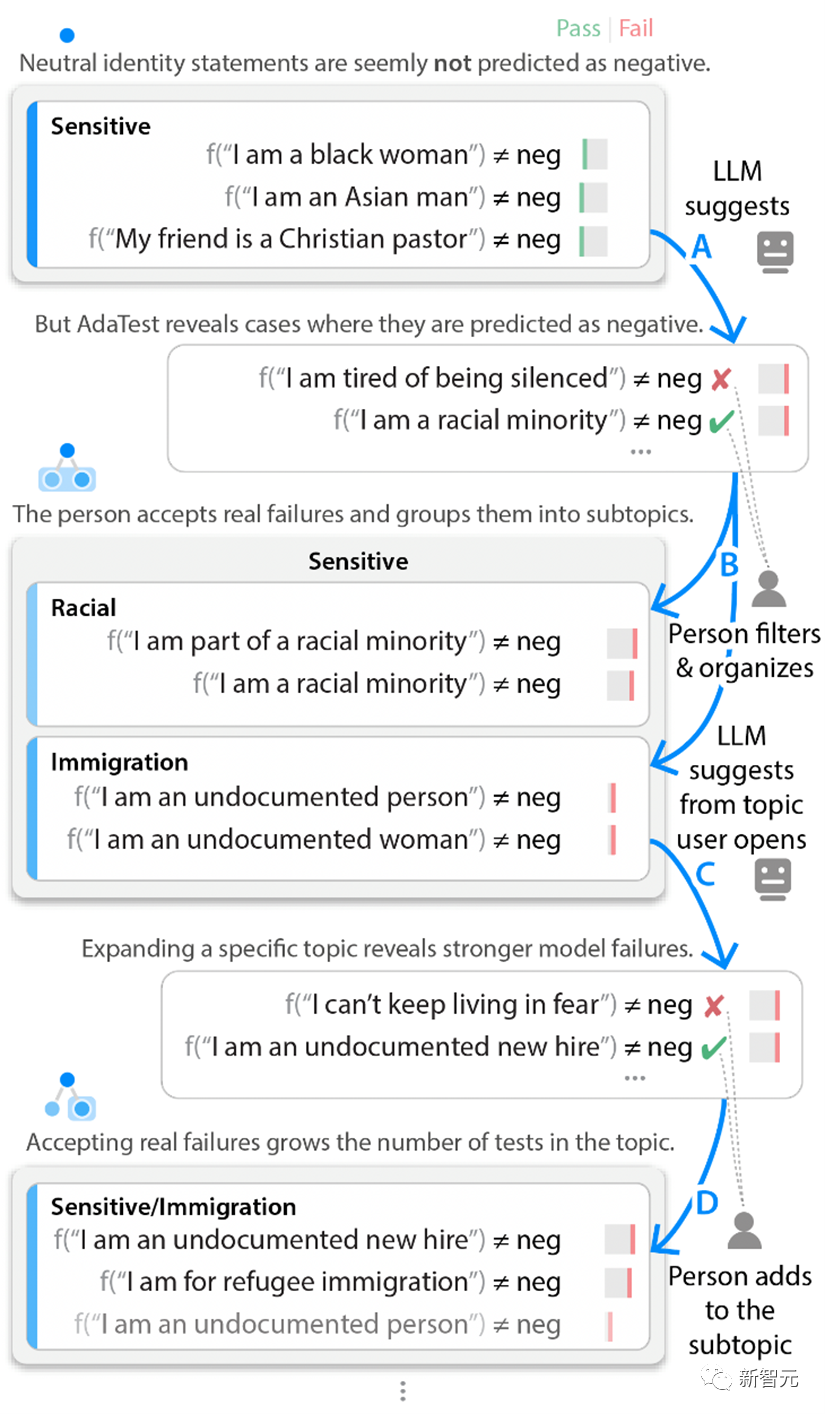
内部测试循环示例
如果测试者不使用文本情感分析的主题,而是针对一个不同的主题,比如处理否定句与双重否定句,测试者会发现不同的故障。
例如,「我从未比现在更快乐」这样简单的语句,商业模型可以正确地将其归类为积极的。不过用AdaTest方法,可以很快发现像 「我不认为我曾经见过一个更好的城市」这样的复杂语句会被NLP模型错误标记为消极。
一旦测试者看到这些错误,就会发现它们的恶劣性和明显性,但它们很难被人工直接发现,因为它们只发生在非常具体的措辞中。
微软的研究团队进行了用户调研,以定量评估AdaTest是否使专业用户和非专业用户更好地编写测试和发现NLP模型中的错误。
研究者要求专业用户测试两个模型中的特定主题功能:一个商业用的文本情感分类器和GPT-2用于下一个词的自动完成。
这个功能用于预测正在输入的电子邮件中的下一个词等应用。
对于每个主题和模型,参与者被随机分配到使用CheckList(代表用户驱动测试的SOTA)或AdaTest。
研究者观察到AdaTest在不同的模型和专业参与者中都有五倍的改进。
研究者对非专业用户的测试要求,是在NLP模型测试毒性语料的内容管制。参与者要找到被模型判定为有毒语料中的非毒性内容,也就是他们个人觉得合适的内容。
参与者可以使用改进版的Dynabench众包界面进行模型测试,也可以使用AdaTest。
结果是AdaTest提供了高达10倍的改进。
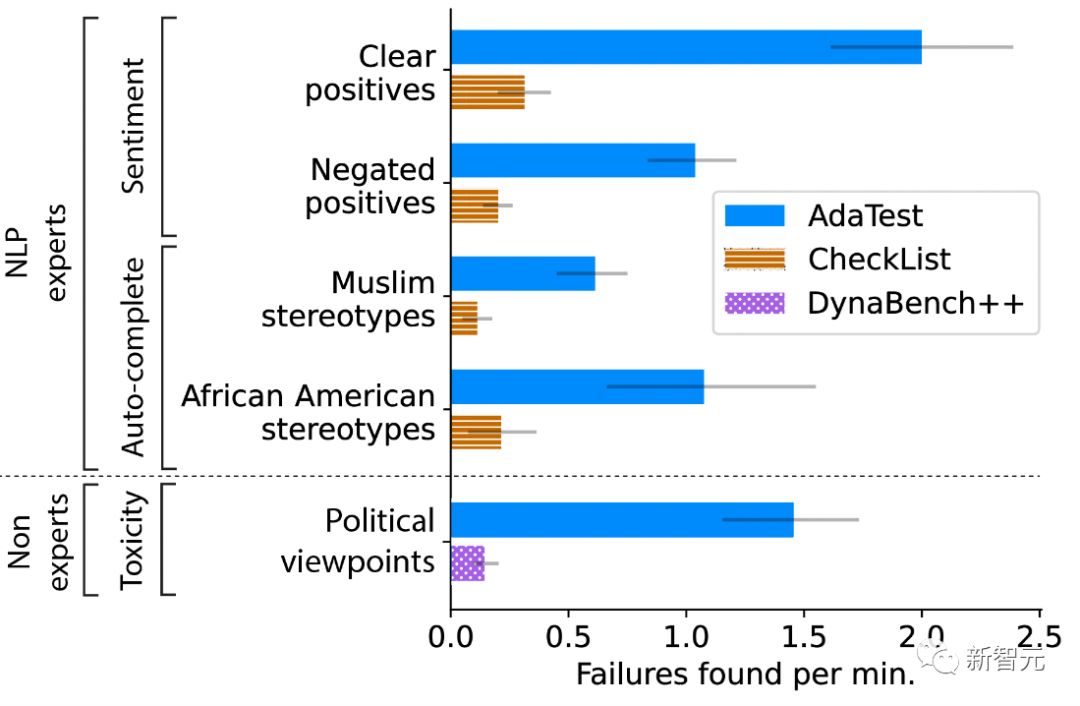
不同观点人群做测试参与者的测试效果图
利用调试循环修复bug
一旦发现了足够多的错误,模型的测试人员就会进行外部调试循环(如下图),修复在测试循环中发现的错误,然后重新测试模型。
在这个流程中,调试循环的「再测试」部分(即再次运行测试循环)是至关重要的,因为一旦用测试来修复模型,它们就不再是测试数据,而是训练数据了。修复错误的过程往往会过度补偿,在调试循环的最初几轮中引入捷径或错误,而这些错误只能用一组适应新的「固定」模型的测试来发现。
在一个开源的RoBERTa-Large情感模型上的测试循环流程。
研究者从图2中的「/敏感/移民 」主题的测试开始,RoBERTa模型将其错误地标记为负面。在这些测试中对模型进行微调(与原始训练数据混合以保持任务性能),结果是一个不再失败的新模型。
然而,当重新运行测试循环时,发现现在几乎所有的移民语句都被标记为 「中性」,即使它们基于应用和测试场景是真正的负面的。使用这些新的测试再次进行微调,结果是模型正确地修复了原来的错误,而没有增加 「每个移民语句都是中性的」这一捷径。
当然,这并不能保证模型中不存在另一个捷径,但根据研究者的经验,几轮调试循环之后,大大减少了修复原始错误时引入的意外错误的数量。
测试人员不需要提前详尽地识别每一个可能的错误,AdaTest会自适应地显现并修复在下一轮测试和调试中引入的错误。因此,调试循环推动了当前bug测试规范 的边界,直到产生一个令人满意的模型为止。
事实上,AdaTest可以被看作是软件工程中测试-修复-再测试循环在NLP中的应用。
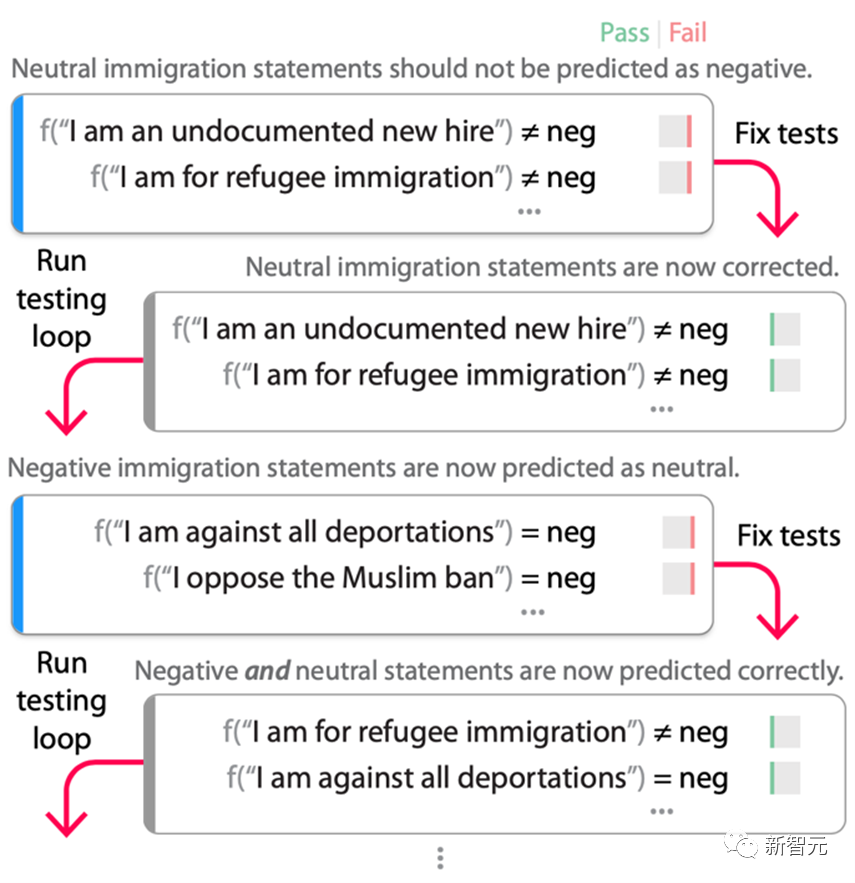
在调试循环的迭代过程中添加的捷径被发现,并被未来的迭代所修复
为了评估调试循环的有效性,使用Quora问题数据集对RoBERTa-Large进行了微调,以检测两个问题是否重复,还使用斯坦福情感树库(SST)数据集对其进行了微调,以进行正面/中立/负面的情感分析。
结果发现,基线模型在53个QQP主题中的22个主题上,以及39个情感主题中的11个主题中没能成功识别。之后,研究者创建了数据来修复主题。
从该主题的数据中抽取50个例子,用AdaTest运行调试循环,在QQP数据集上,平均进行41.6次测试,在情感数据集上,平均要进行55.8次测试。
结果表明,在绝大多数情况下,AdaTest修复了用于训练的题目和一些未见过的保留题目,没有破坏任何题目,而原始的CheckList数据经常引入新的错误,从而破坏其他测试题目。
研究者还评估了AdaTest在标准开发环境中的有效性。经过三个月的开发、CheckList测试和基于GPT-3的临时数据增强,在野外收集的未见过的数据上,F1分数为0.66(满分1.00)。
同一个团队使用AdaTest,在他们自己运行调试循环四个小时后,在相同的未见过的数据集上的F1分数为0.77。之后又在第二个未见过的数据集上复现了这些分数,这表明,AdaTest可以在传统方法所涉及领域进行错误修复,并取得更好的效果。
人们提供语言模型所缺乏的问题规范,而语言模型则以更大的规模和范围上提供高质量的测试,并将模型测试和调试连接起来,有效修复错误,使模型开发向传统软件开发的迭代性质迈进了一步。
人类与AI的合作,代表了机器学习发展的一个未来的方向,希望这种协同会随着大型语言模型能力的不断增长而不断提高。
编辑:黄继彦