
我扔掉FPN来做目标检测,效果竟然这么强!YOLOF开源:你只需要看一层特征|CVPR2021

极市导读
旷视科技&中科院对单阶段目标检测中的FPN进行了重思考,采用一级特征进行检测替换复杂的特征金字塔来解决优化问题,提出了YOLOF。该方法取得了与RetinaNet相当的性能且推理速度快2.5倍。>>加入极市CV技术交流群,走在计算机视觉的最前沿

paper: https://arxiv.org/abs/2103.09460
code: https://github.com/megvii-model/YOLOF
本文是旷视科技&中科院孙剑团队在单阶段目标检测方面一次突破性的创新,它针对单阶段目标检测中的FPN(特征金字塔)进行了深入的分析并得出:FPN最重要的成分是分而治之的处理思路缓解了优化难问题。针对FPN的多尺度特征、分而治之思想分别提出了Dilated编码器提升特征感受野,Uniform Matching进行不同尺度目标框的匹配;结合所提两种方案得到了本文的YOLOF,在COCO数据集上,所提方案取得了与RetinaNet相当的性能且推理速度快2.5倍;所提方法取得了与YOLOv4相当的性能且推理速度快13%。
Abstract
本文对单阶段目标检测中的FPN进行了重思考并指出FPN的成功之处在于它对目标检测优化问题的分而治之解决思路而非多尺度特征融合。从优化的角度出发,作者引入了另一种方式替换复杂的特征金字塔来解决该优化问题:从而可以仅仅采用一级特征进行检测。基于所提简单而有效的解决方案,作者提出了YOLOF(You Only Look One-level Feature)。
YOLOF有两个关键性模块:Dilated Encoder与Uniform Matching,它们对最终的检测带来了显著的性能提升。COCO基准数据集的实验表明了所提YOLOF的有效性,YOLOF取得与RetinaNet-FPN同等的性能,同时快2.5倍;无需transformer层,YOLOF仅需一级特征即可取得与DETR相当的性能,同时训练时间少7倍。以大小的图像作为输入,YOLOF取得了44.3mAP的指标且推理速度为60fps@2080Ti,它比YOLOv4快13%。
本文的贡献主要包含以下几点:
FPN的关键在于针对稠密目标检测优化问题的“分而治之”解决思路,而非多尺度特征融合; 提出了一种简单而有效的无FPN的基线模型YOLOF,它包含两个关键成分(Dilated Encoder与Uniform Matching)以减轻与FPN的性能差异; COCO数据集上的实验证明了所提方法每个成分的重要性,相比RetinaNet,DETR以及YOLOv4,所提方法取得相当的性能同时具有更快的推理速度。
Introduction
本文主要针对单阶段检测器中的FPN的两个重要因素进行了研究,作者以RetinaNet为基线,通过解耦多尺度特征融合、分而治之进行实验设计。作者将FPN视作多输入多输出编码器(MiMo,见下图),它对骨干网络的多尺度特征进行编码并为后接的解码器提供多尺度特征表达。
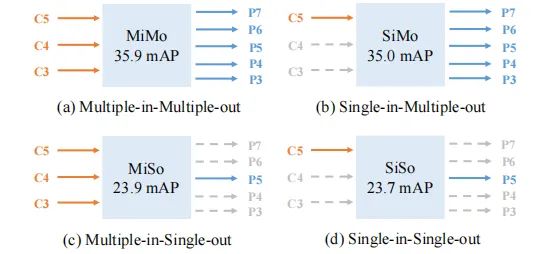
为进行更好的对比分析,作者设计了MiMo、SiMo、MiSo、SiSo等四种类型的解码器,见上图。令人惊艳的是:SiMo编码器仅仅采用C5特征且不进行特征融合即可取得与MiMo编码器相当的性能,且性能差异小于1mAP。相反,MiSo编码器的性能则出现了显著下降。这个现象意味着:
C5包含了充分的用于检测不同尺度目标的上下文信息,这促使SiMo编码器可以取得与MiMo相当的结果; 多尺度特征融合带来的收益要远小于分而治之带来的收益,因此多尺度特征融合可能并非FPN最重要的影响因素;相反,分而治之将不同尺度的目标检测进行拆分处理,缓解了优化问题。
Cost Analysis of MiMo Encoders
如前所述FPN的成功在于它对于优化问题的解决思路,而非多尺度特征融合。为说明这一点,作者对FPN(即MiMo)进行了简单的分析。

以RetinaNet-ResNet50为基线方案,作者将检测任务的流水线分解为三个关键部分:骨干网络、Encoder以及Decoder。下图给出了不同部分的Flops对比,可以看到:
相比SiMoEncoder,MiMoEncoder带来显著的内存负载问题(134G vs 6G); 基于MiMoEncoder的检测器推理速度明显要慢于SiSoEncoder检测器(13FPS vs 34FPS); 这个推理速度的变慢主要是因为高分辨率特征部分的目标检测导致,即C3特征部分。
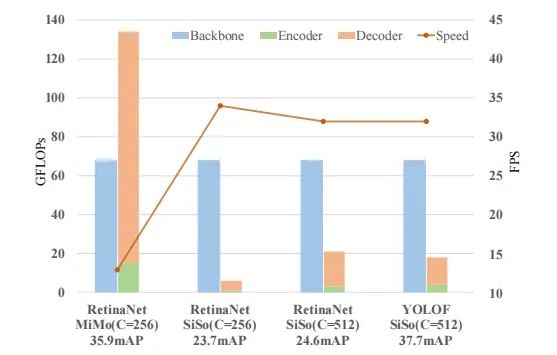
基于上述分析,作者期望寻找另一种解决优化问题的方案,且保持检测器简单、精确、快速。
Method
受上述目标驱动以及新发现:C5特征包含足够的信息进行大量目标检测,作者尝试用简单的SiSoEncoder替换复杂的MiCoEncoder。但是,这种简单的替换会带来显著性的性能下降(35.9mAP vs 23.7mAP),见上图。对于这种情况 ,作者进行了仔细分析得出SiSoEncoder性能下降的两个重要原因:
The range of scales matching to the C5 feature's receptive field is limited The imbalance problem on positive anchors
接下来,作者将针对这两个问题进行讨论并提出对应的解决方案。
Limited Scale Range
识别不同尺寸的目标是目标检测的一个根本挑战。一种常见的方案是采用多级特征。在MiMo与SiMoEncoder检测器中,作者构建了不同感受野的多级特征(C3-C7)并在匹配尺度上进行目标检测。然而,单级特征破坏了上述游戏规则,在SiSoEncoder中仅有一个输出特征。
以下图(a)为例,C5特征感受野仅仅覆盖有限的尺度范围,当目标尺度与感受野尺度不匹配时就导致了检测性能的下降。为使得SiSoEncoder可以检测所有目标,作者需要寻找一种方案生成具有可变感受野的输出特征,以补偿多级特征的缺失。
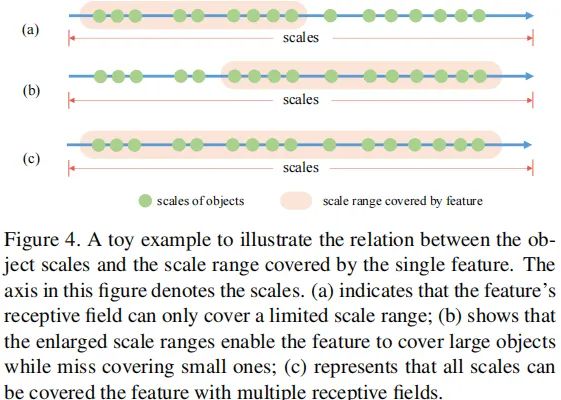
在C5特征的基础上,作者采用堆叠扩张卷积方式提升其感受野。尽管其覆盖的尺度范围可以在一定程度上扩大,但它仍无法覆盖所有的目标尺度。以上图(b)为例,相比图(a),它的感受野尺度朝着更大尺度进行了整体的偏移。然后,作者对原始尺度范围与扩大后尺度范围通过相加方式进行组合,因此得到了覆盖范围更广的输出特征,见上图(c)。
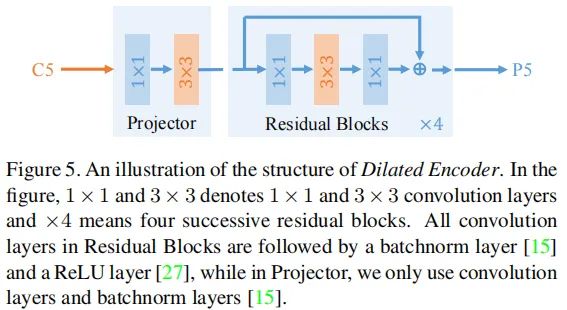
上图给出了采用本文所提SiSoEncoder结构示意图,作者称之为Dilated Encoder。它包含两个主要成分:Prejector与Residual Block。投影层采用卷积,然后采用卷积提取上下文语义信息(作用类似FPN);然后堆叠四个不同扩张因子的残差模块以生成多感受野的输出特征(覆盖所有的目标尺度)。
Imbalance Problem on Positive Anchors
正锚点的定义对于目标检测中的优化问题尤其重要。在基于锚点的检测方案中,正锚点的定义策略主要受锚点与真实box之间的IoU决定。在RetinaNet中,如果IoU大于0.5则锚点设为正。作者称之为Max-IoU matching。
在MiMoEncoder中,锚点在多级特征上以稠密方式进行预定义,同时按照尺度生成特征级的正锚点。在分而治之的机制下,Max-IoU匹配使得每个尺度下的真实Box可以生成充分数量的正锚点。然而,当作者采用SiSoEncoder时,锚点的数量会大量的减少(比如从100K减少到5K),导致了稀疏锚点。稀疏锚点进一步导致了采用Max-IoU匹配时的不匹配问题。以下图为例,大的目标框包含更多的正锚点,这就导致了正锚点的不平衡问题,进而导致了检测器更多关注于大目标而忽视了小目标。
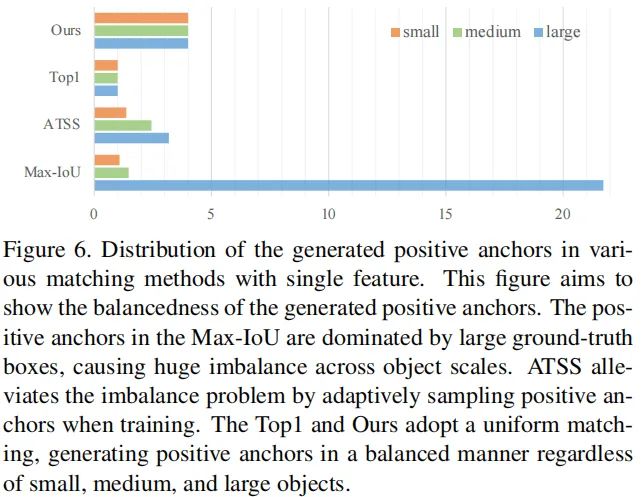
为解决上述正锚点不平衡问题,作者提出了Uniform Matching策略:对于每个目标框采用k近邻锚点作为正锚点,这就确保了所有的目标框能够以相同数量的正锚点进行均匀匹配。正锚点的平衡确保了所有的目标框都参与了训练且贡献相等。在实现方面,参考了Max-IoU匹配,作者对Uniform matching中的IoU阈值进行设置以忽略大IoU负锚点和小IoU正锚点。
YOLOF
基于上述解决方案呢,作者提出了一种快速而直接的单级特征检测框架YOLOF,它由骨干网络、Encoder以及Decoder构成,整体结构如下图所示。
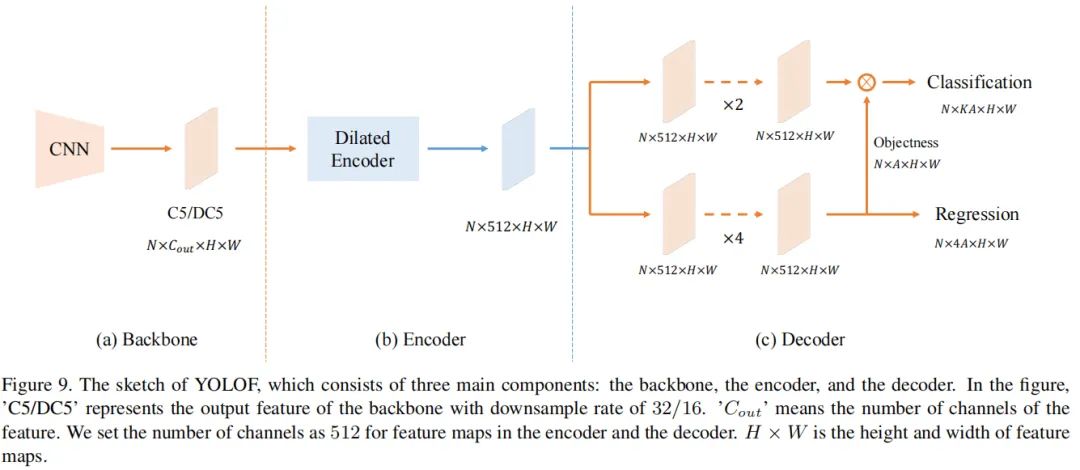
BackBone。在所有模型中,作者简单的采用了ResNet与ResNeXt作为骨干网络,所有模型在ImageNet上与训练,输出C5特征该通道数为2048,下采样倍率为32; Encoder。在这部分,作者参考FPN添加了两个投影层,将通道数降到512,然后堆叠四个不同扩张因子的残差模块; Decoder。在这部分,作者采用了RetinaNet的主要设计思路,它包含两个并行的任务相关的Head分别用于分类和回归。作者仅仅添加两个微小改动:(1) 参考DETR中的FFN设计让两个Head的卷积数量不同,回归Head包含4个卷积而分类Head则仅包含两个卷积;(2) 作者参考AutoAssign在回归Head上对每个锚点添加了一个隐式目标预测。 Other Detail。正如前面所提到的YOLOF中的预定义锚点是稀疏的,这会导致目标框与锚点之间的匹配质量下降。作者在图像上添加了一个随机移动操作以缓解该问题,同时作者发现这种移动对于最终的分类是有帮助的。
Experiments
为说明所提方案的有效性,作者在MS COC数据集上与RetinaNet、DETR、YOLOv4进行了对比。
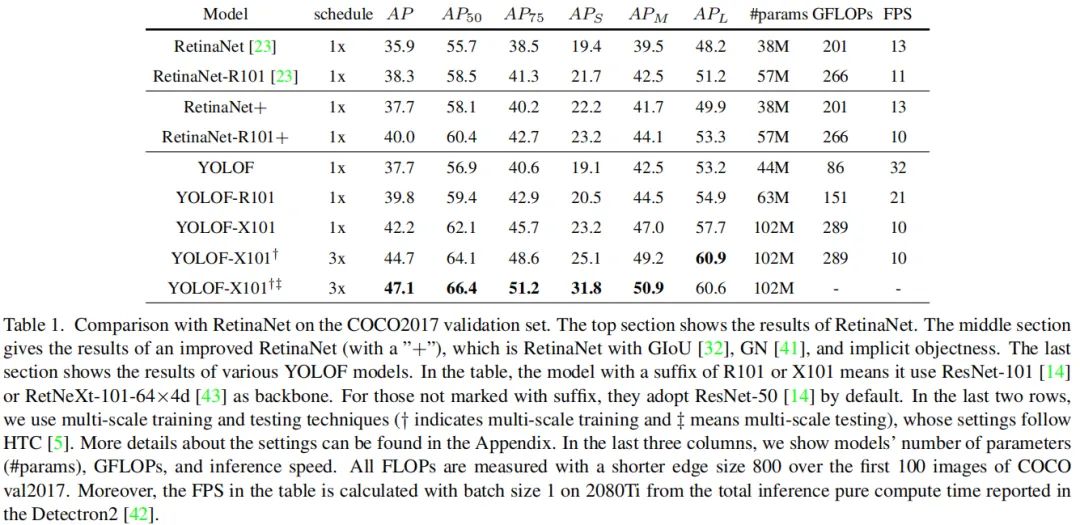
上表给出了所提方法与RetineNet在COCO数据集上的性能对比。从中可以看到:
YOLOF取得了与改进版RetinaNet+相当的性能,同时减少了57%的计算量,推理速度快了2.5倍; 当采用相同骨干网络时,由于仅仅采用C5特征,YOLOF在小目标检测方面要比RetinaNet+弱一些(低3.1);但在大目标检测方面更优(高3.3); 当YOLOF采用ResNeXt作为骨干网络时,它可以取得与RetinaNet在小目标检测方面相当的性能且推理速度同样相当。 经由多尺度测试辅助,所提方法取得了47.1mAP的指标,且在小目标方面取得了极具竞争力的性能31.8mAP。
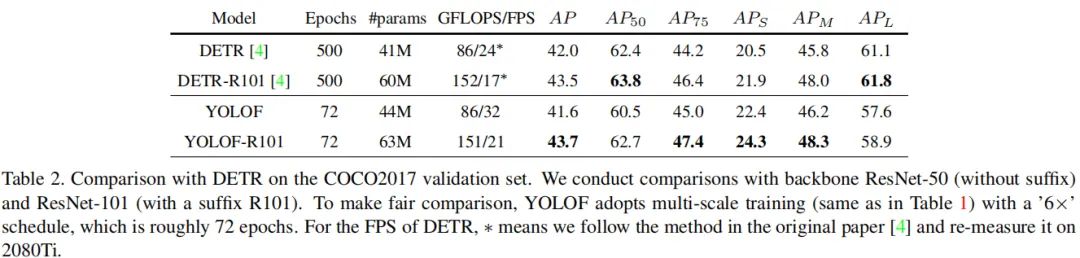
上图给出了所提方法与DETR的性能对比。从中可以看到:
YOLOF取得了与DETR相匹配的的性能; 相比DETR,YOLOF可以从更深的网络中收益更多,比如ResNet50时低0.4,在ResNet10时多了0.2; 在小目标检测方面,YOLOF要优于DETR;在大目标检测方面,YOLOF要弱于DETR。 在收敛方面,YOLOF要比DETR快7倍,这使得YOLOF更适合于作为单级特征检测器的基线。

最后,作者再来看一下所提方法与YOLOv4的性能对比(注:这里采用了与YOLOv4类似的数据增强方法,并采用了三阶段训练方案,同时对骨干网络的最后阶段进行了调整)。从上表作者可以看到:
YOLOF-DC5取得了比YOLOv4快13%的推理速度,且性能高0.8mAP; YOLOF-DC5在小目标检测方面弱于YOLOv4,而在大目标检测方面显著优于YOLOv4; 这也就意味着:单级检测器具有极大的潜力获得SOTA速度-精度均衡性能。
全文到此结束,更多消融实验与分析建议各位同学查看原文。
推荐阅读
2021-03-11

2021-03-16

2021-03-15


# 极市原创作者激励计划 #
