论文:You Only Look One-level Feature
下载地址:
https://arxiv.org/abs/2103.09460
代码:
https://github.com/megvii-model/YOLOF
针对多尺度特征融合提出多层输入和单层输入的方式,针对分而治之提出在单层检测和多层检测的方式,两者结合就是如下图所示的MiMo,SiMo,MiSo,SiSo。
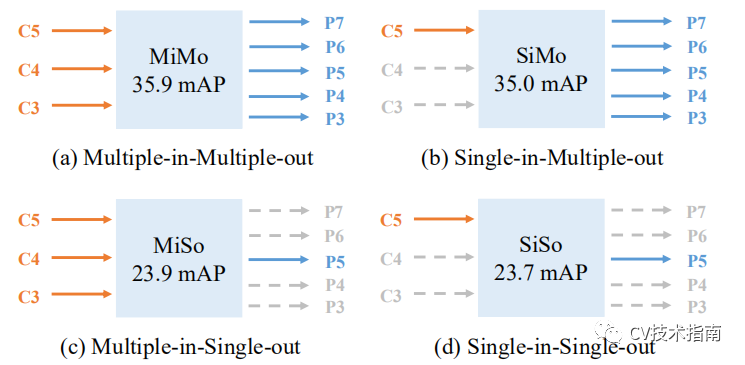
根据图a和b可得出多尺度融合的特征所带来的精度提升很少。对比图a和c,分而治之的方式可带来12的mAP的提升。(1) 这表明C5层基本融合了全部语义信息,没必要进行多尺度融合。
(2) 分而治之带来的益处远多于多尺度特征融合。
然而相比于单层检测,使用分而治之意味着需要更多的内存,降低推理速度,且对于one-stages的检测器来说结构更复杂。
基于第一个实验的结论,作者进行了第二个实验--比较MiMo和SiSo这两种Encoder-Decoder方式。
实验结果如下图所示,MiMo的精度比SiSo更高,但推理速度慢了很多,且MiMo与SiSo的内存之比为134G vs 6G。
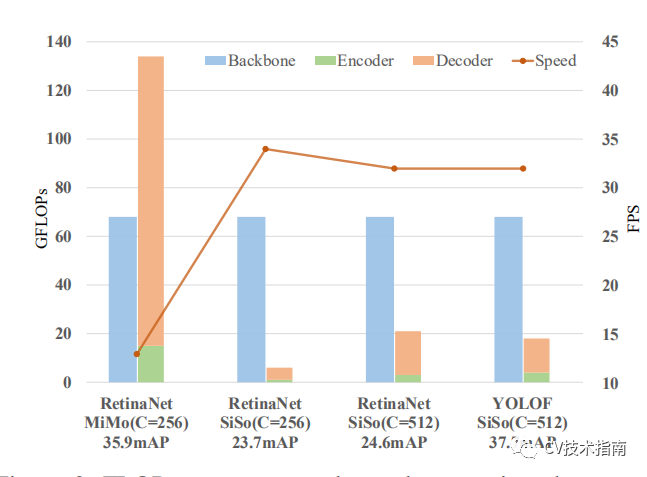
经过分析,SiSo精度低的原因是有两个:
(1) 与C5的特征感受野的匹配的尺度范围有限。
(2) 在单层通过稀疏anchor方式产生的positive anchor数量极其不平衡。
基于以上两个实验,作者提出不再使用多尺度融合,而是要扩大C5所能匹配的尺度范围,这样能在提高精度的同时,充分利用SiSo的速度和低内存的优点。所使用的方式就是对这两个问题进行改进。
提出Dilated Encoder来解决C5的尺度匹配范围的问题,提出Uniform Matching来解决单层positive anchors数量不平衡的问题。Dilated Encoder
为方便读者理解,先补充一点说明,特征金字塔的一种方式就是FPN这种使用降采样来构建,另一种方式就是通过多支路使用不同空洞率的空洞卷积 (dilation convolution)来构建。关于特征金字塔这种技术,在很多论文中提出了一些新的特征融合方式,在下一篇中将对特征金字塔进行技术总结,感兴趣的读者请关注公众号《CV技术指南》的技术总结部分。在这里就是使用了第二种方式来构建特征金字塔,但有所不同的是,这里并不是使用多支路,而是将其串联,一条支路中使用四种空洞率的空洞卷积,看图更容易理解。
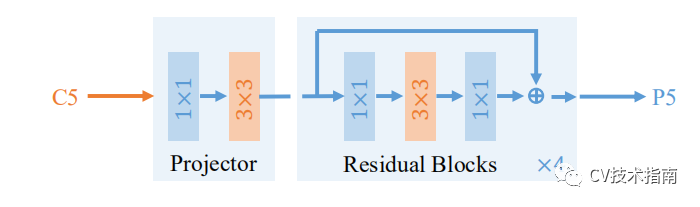
Dilated Encoder由一个Projector和四个Residual Blocks组成,其中Residual Blocks中3x3卷积的空洞率是不一样的。
Uniform Matching
MiMo和SiSo产生的anchor的数量比为100K vs 5K,由于使用Max-IOU这种匹配方式,大的GT boxes会比小的GT boxes产生更多的positive anchor,这使得网络在训练过程中将更多的注意放在了大的 GT boxes,而忽视了小的。因此Uniform Matching的方式是使用最近邻方式来匹配。具体方式是选择GT boxes最近的K个boxes, 这样的方式不管GT boxes大小可以匹配相同数量的Boxes。
1.以608x608的输入,YOLOF 在2080Ti上以60fps的速度实现了44.3 mAP的精度。
2.与YOLO_v4相比,在提高了0.8mAP的基础上快了13%。
3.达到RetinaNet的精度,并比它快2.5倍。
4.仅用了一层特征就达到了DETR的精度,训练速度快了7倍。
✄------------------------------------------------
欢迎微信搜索并关注「目标检测与深度学习」,不被垃圾信息干扰,只分享有价值知识!
10000+人已加入目标检测与深度学习
敬正在努力的我们! 
