
本文约5400字,建议阅读5分钟
本文想要和大家分享的是在深度学习背景下,京东基于语义的搜索召回技术和新的进展。

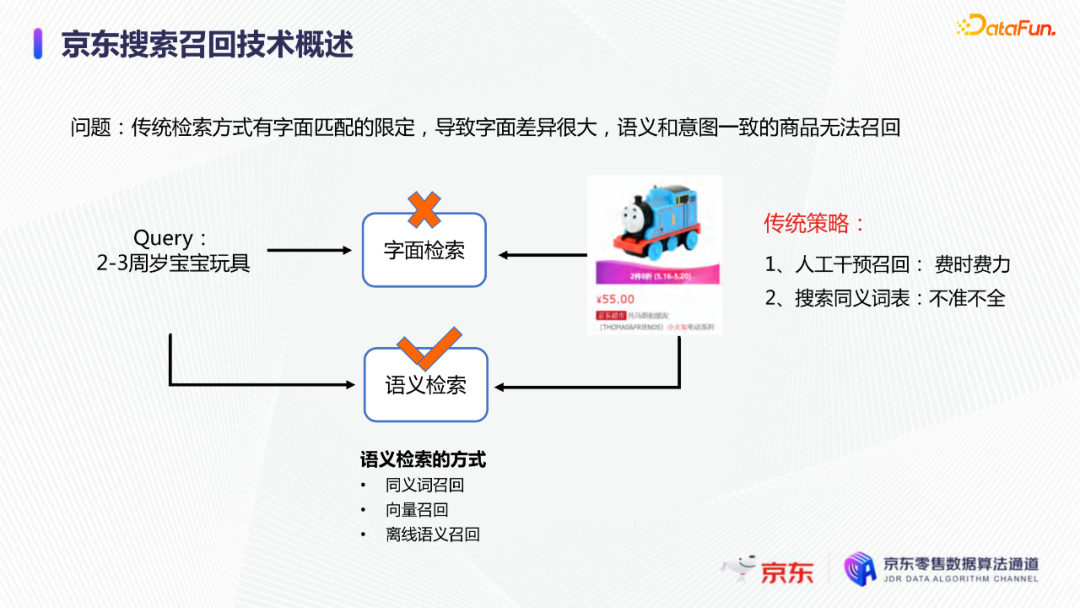
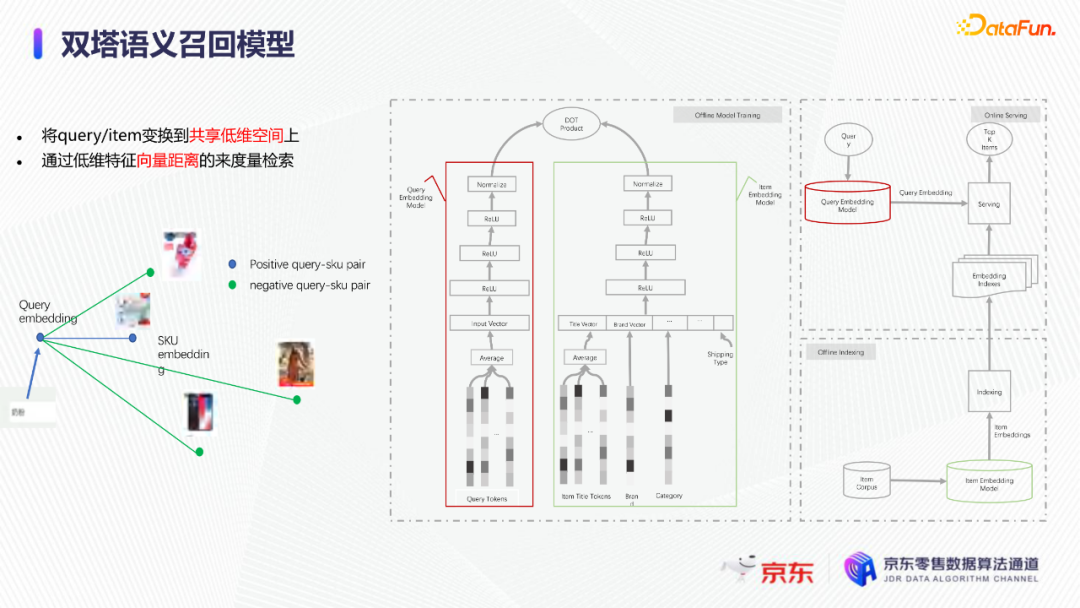
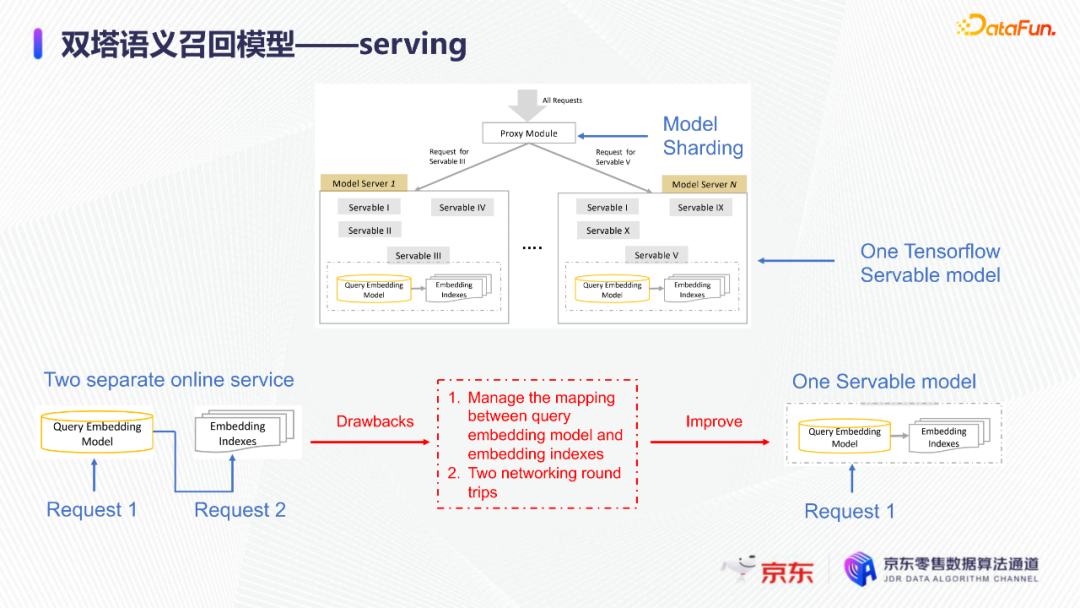
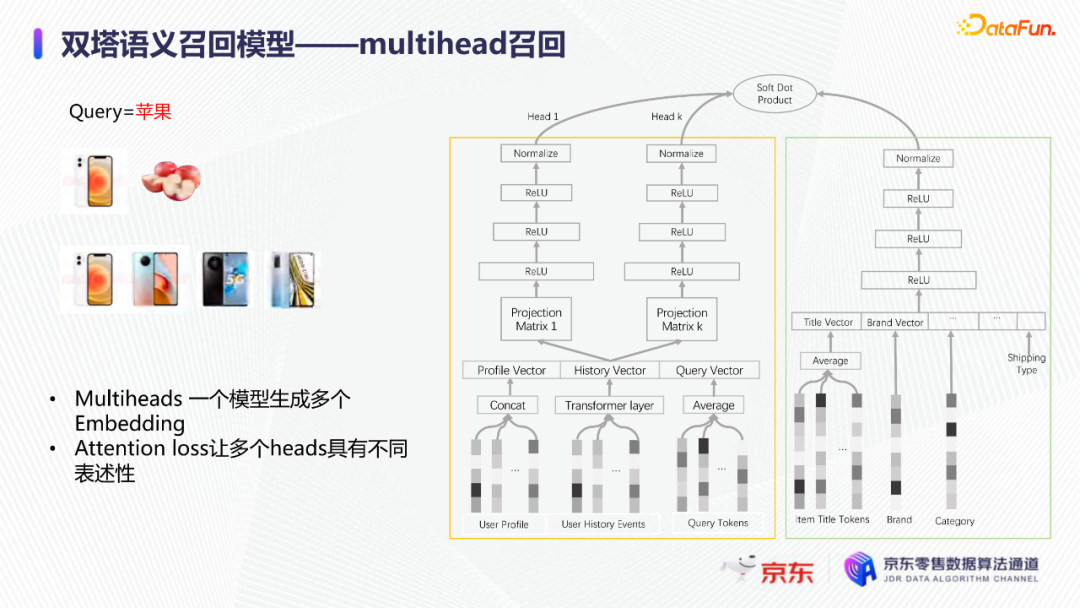
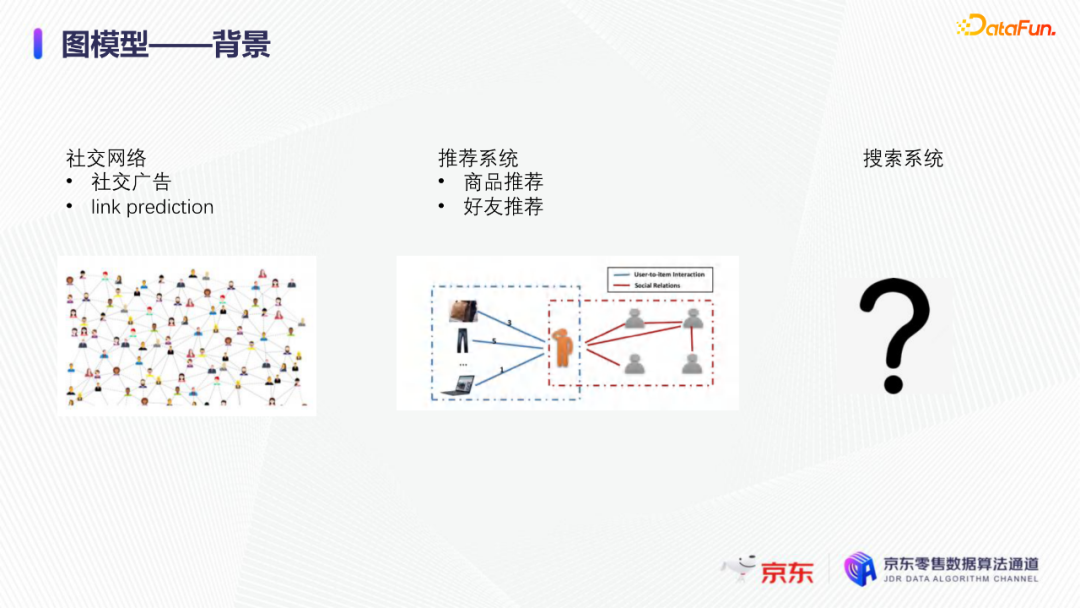
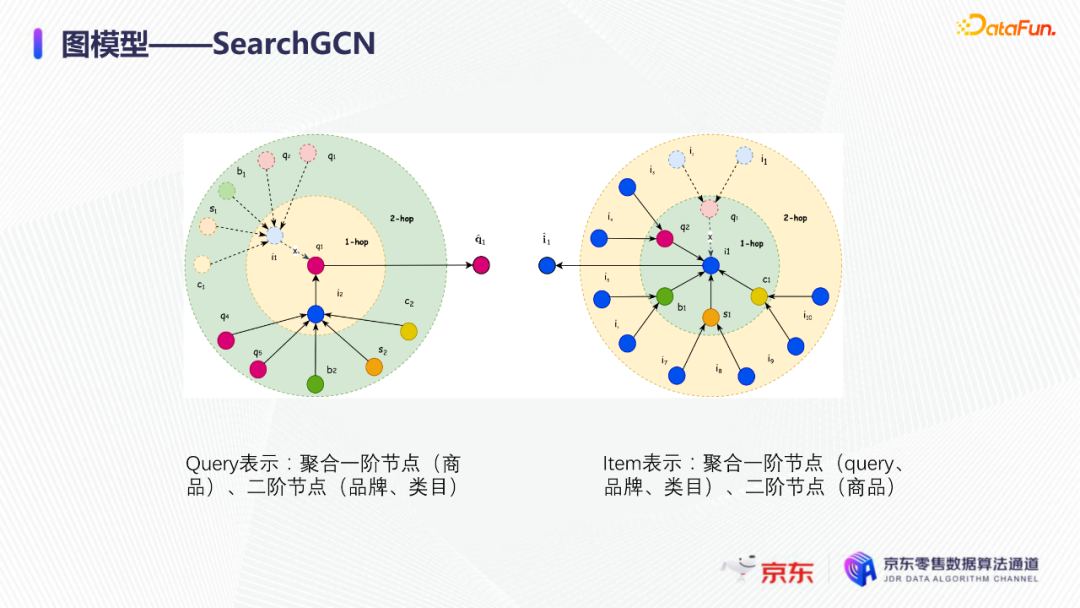
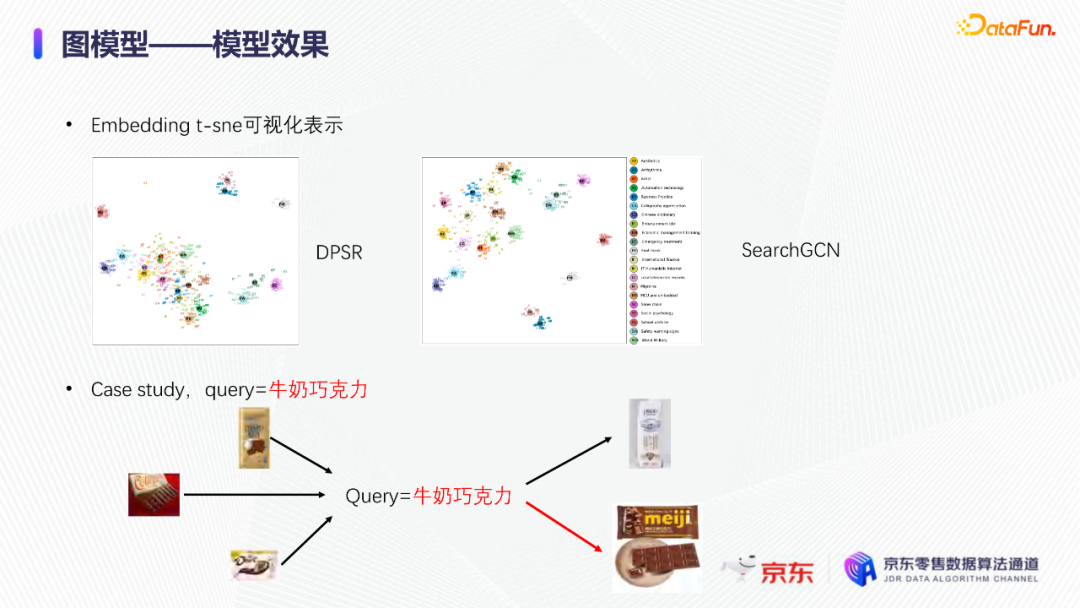
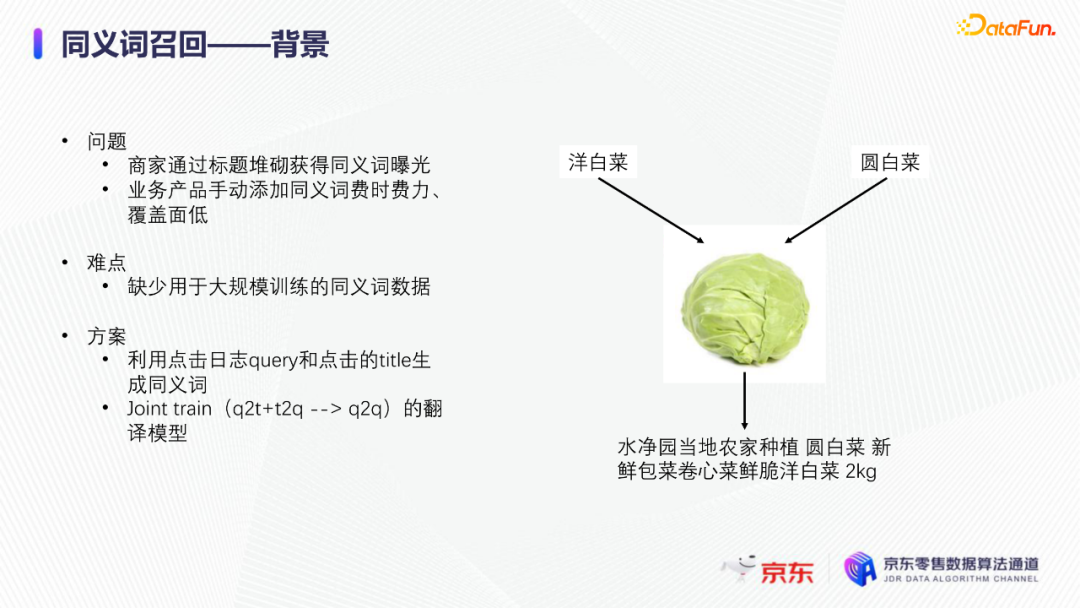
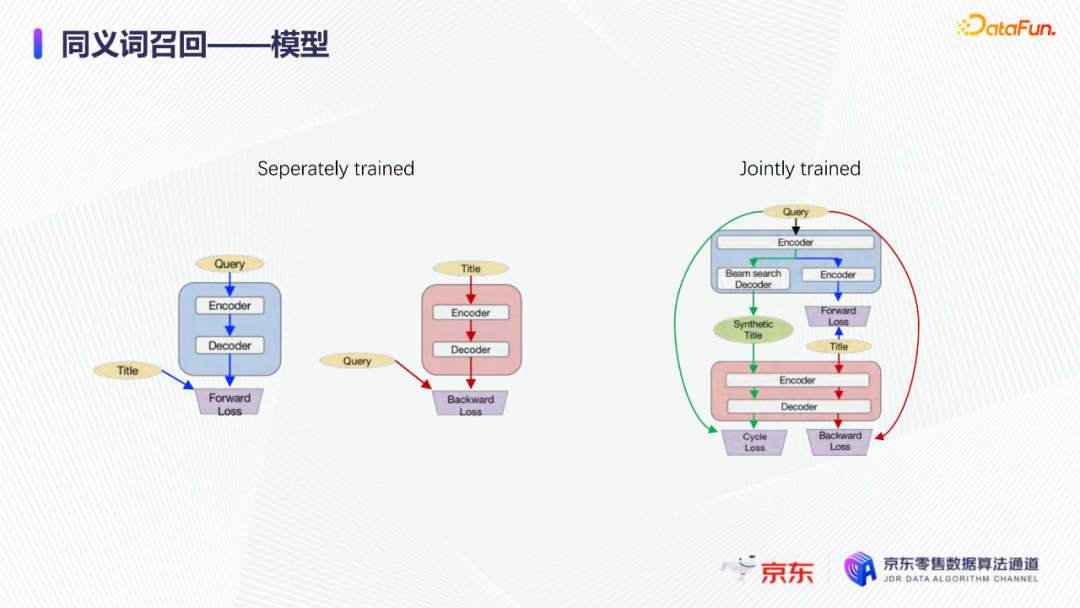
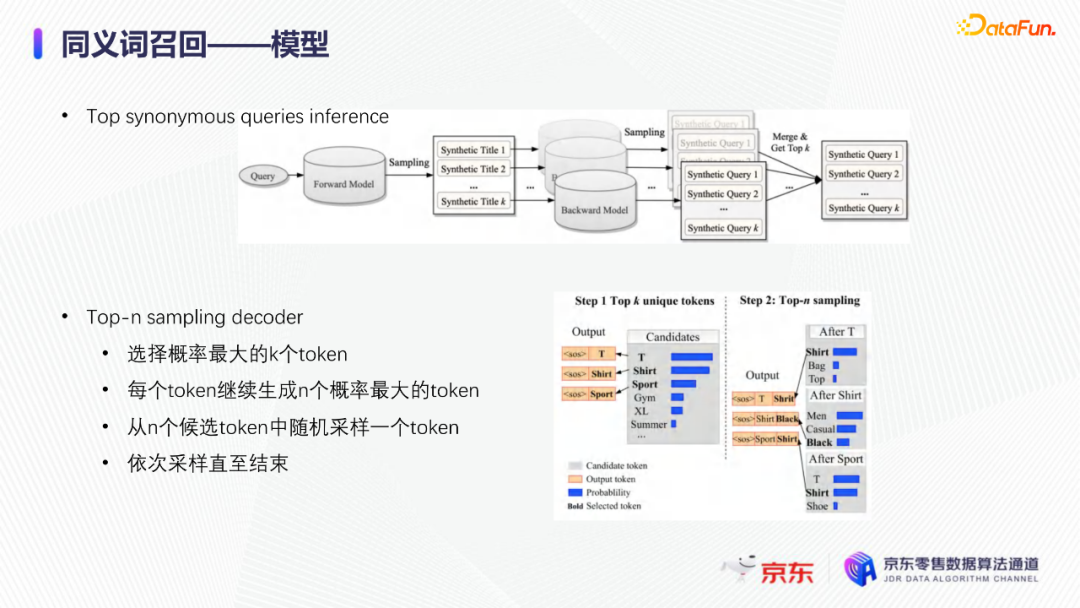
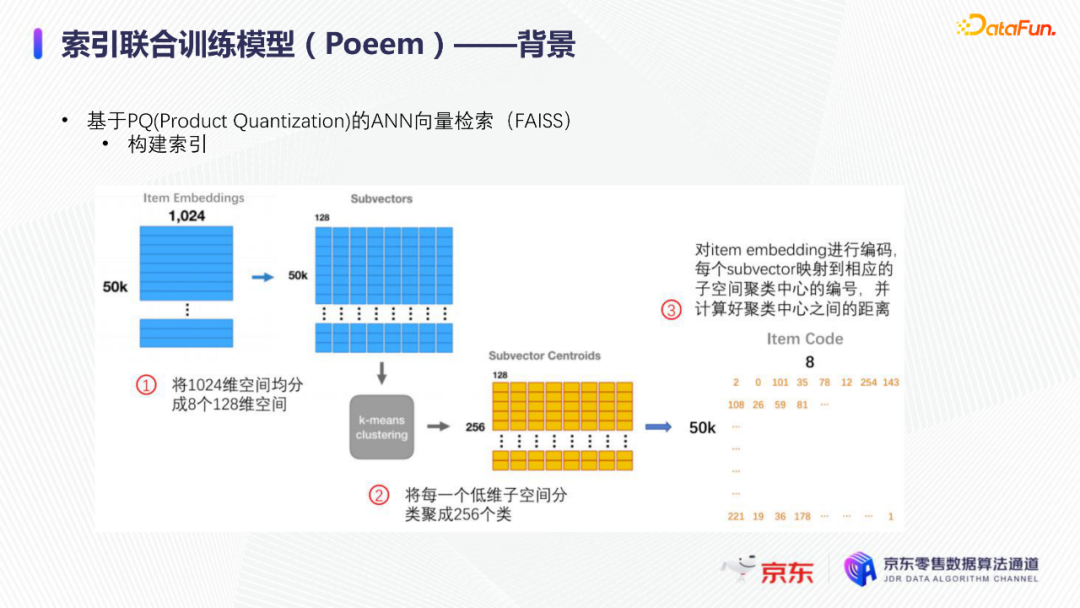
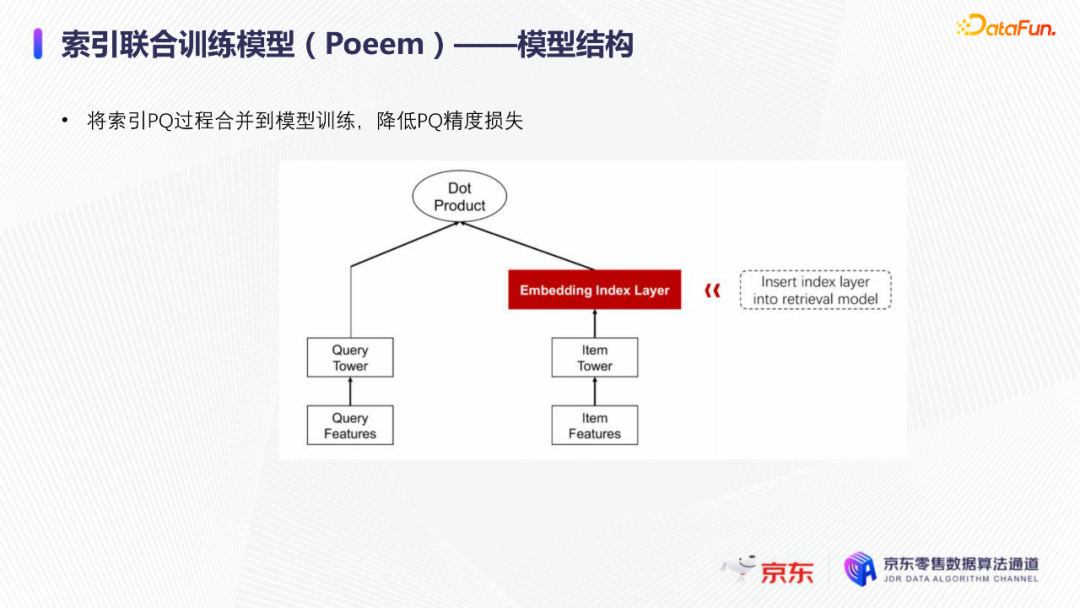
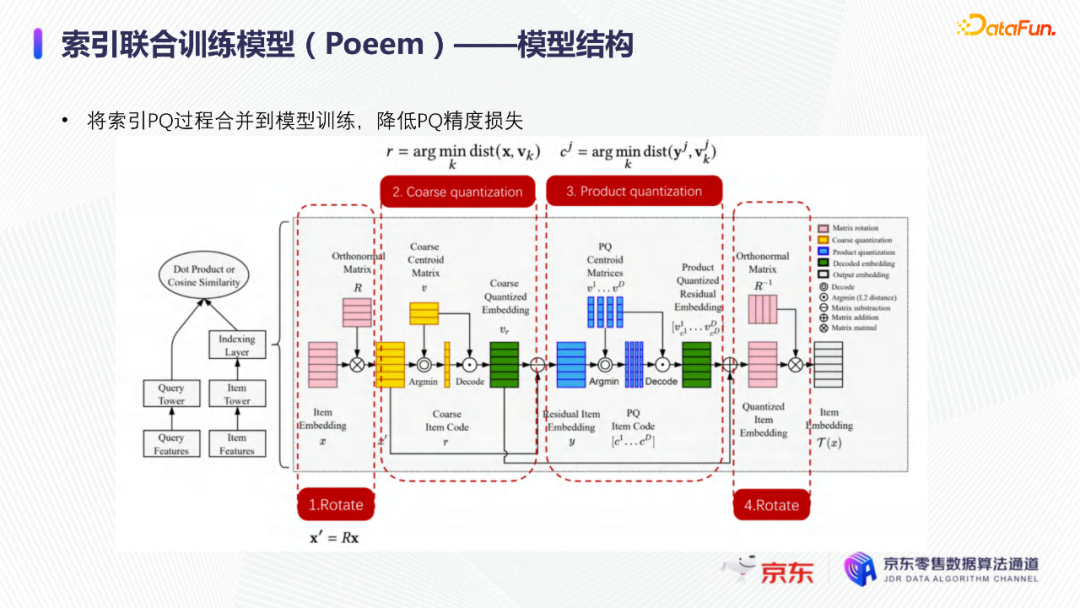
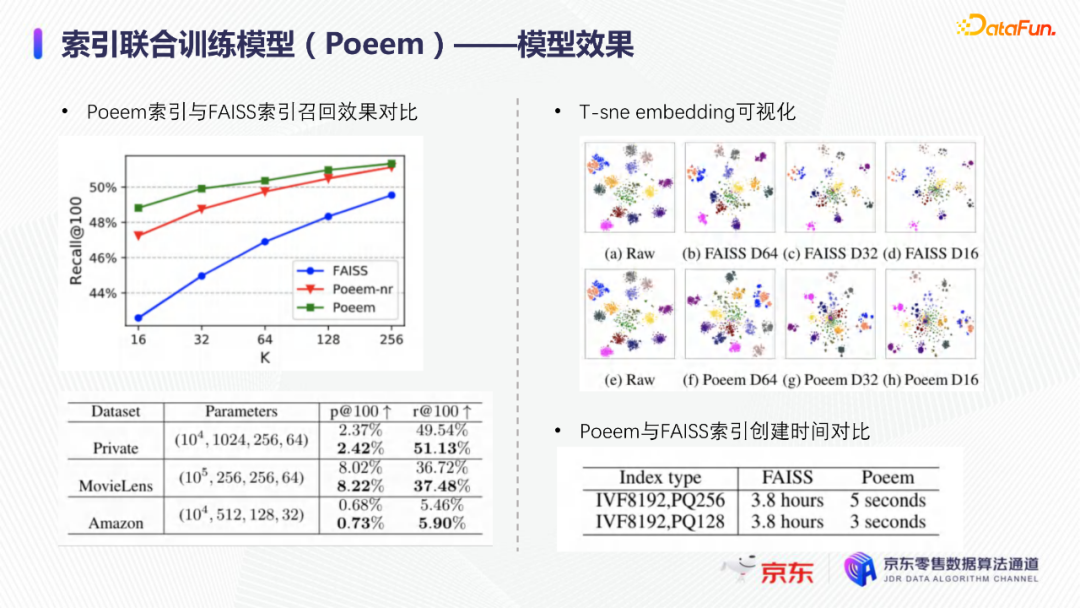
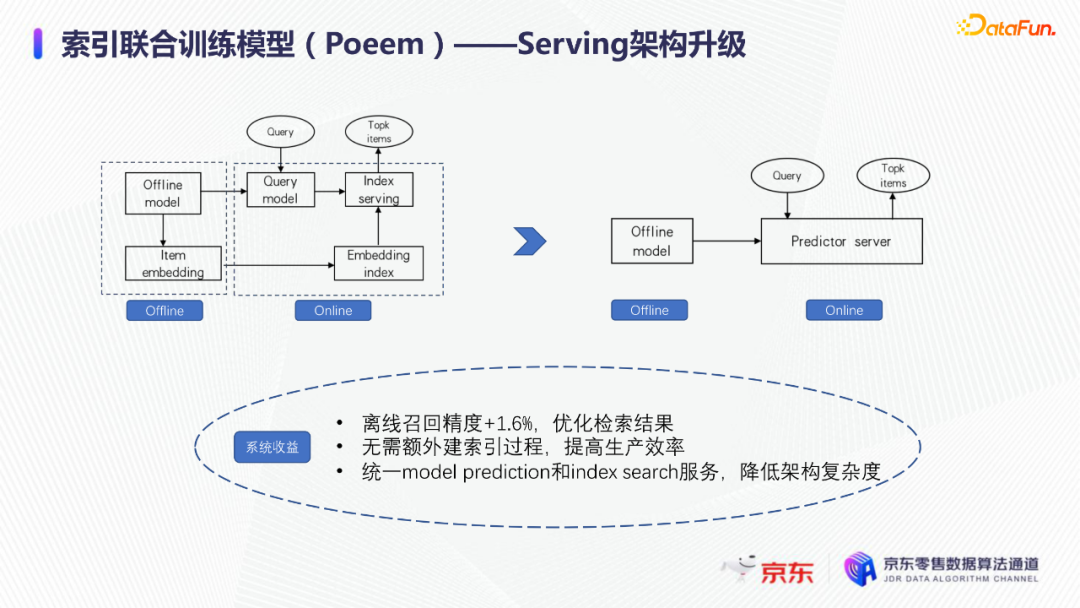
导读:搜索主要经历四个阶段:召回、粗排、精排和重排,最后呈现给用户最终的结果。而召回的结果主要来自两个部分:倒排检索和语义召回。传统的倒排检索依赖字面匹配,很难去召回一些语义相似但是字面不匹配的商品。传统的语义召回策略有人工干预召回、人工构建同义词表进行同义词替换等等。但是相比于深度语义模型,这些技术费时费力,并且覆盖率低下,很难适应快速增长的海量商品的召回需求。今天想要和大家分享的是在深度学习背景下,京东基于语义的搜索召回技术和新的进展。多路语义召回包含同义词召回、向量召回和离线语义召回。这些语义召回方式能够解决传统策略费时费力、不准不全的问题,但是同样也面临着一些技术难点,包括准确性、相关性和丰富性等。准确性是向量召回技术存在的一个基本问题,主要原因是因为大规模向量的近似查找会引入精度损失。而语义匹配也很容易引入相关性问题,比如品牌一致性、型号一致性等。不仅如此,语义召回在满足前两个问题的前提下,还应该尽量地召回更多更丰富的商品,提高类目多样性、品牌多样,为下游任务提供更多的选择。接下来我们就详细介绍一些我们目前采用的一些语义召回的模型和技术。首先是一个基础的双塔语义召回模型。双塔语义召回模型的核心思想是将query/item嵌入到共享低维空间上,然后通过向量距离来度量相关性。上图右侧是我们整体的模型和线上服务的框架。其中左边是离线的双塔模型,包含一个query塔和一个item塔,分别用来进行query和item的语义表征。Query侧主要使用其文本信息,分词方式是n-gram,实际应用时会使用unigram和bigram。右侧item塔主要使用item的自身特征,包括标题、品牌、类目、派送方式等信息。Query和item塔在结构上大体是分离的,但是它们之间需要一些信息的共享。信息共享主要由两个方面实现:输入层的query embedding和item的标题embedding共享embedding矩阵;输出层query与item的embedding会进行点乘来实现信息交互。右侧是模型服务的流程,主要分为两个过程。首先是一个离线导出过程,需要将item的embedding导出,建立索引。与此同时,我们还需要将query一侧的模型导出。导出的query模型和建好的索引共同服务线上召回任务。具体地,对于用户的一次请求,我们首先调用query模型server来得到query embedding,然后用query embedding请求索引服务得到最终召回的商品。如果分为两阶段服务,存在两个问题:首先,我们需要管理query模型服务和索引服务之间的映射关系;其次,每次用户请求会在内部经历两次网络请求,增加召回时延。所以在工程上,我们将query的模型服务和索引服务整合成一个服务,使得我们可以通过一次请求得到召回结果。在此基础上,我们还做了一些改进的工作。比如部分搜索词具有一定的语义多义性。例如,苹果这个词既可以表示苹果的电子产品,也可以表示水果苹果。在上一版的语义模型中,我们发现这种多义的搜索词通常会倾向于表达用户点击更频繁的商品。比如在苹果这一例子下,上一版模型召回的更多是苹果手机。但是在实际召回中,就语义相关性而言,更合理的状态应该是既能召回苹果产品,又能召回水果苹果。因此我们修改了网络结构来提升模型的多语义表征能力。具体地,我们会为query学习多个head,然后在输出层使用注意力机制来使query的每个head具有不同的表征性,从而实现多义商品的召回。为了更直观地呈现最终的召回效果,我们对embedding做了t-sne的可视化展示,不同的簇代表不同的类目或者品牌。图一和图二代表的是不同类目,图三对应不同的品牌。从图一可以看到当模型只有一个头的情况下,召回还是倾向于苹果手机;而在使用两个头时可以看到第一个头主要还是召回iPhone,但第二个头更倾向于召回水果苹果。第三张图是query为手机的情况下,两个头的双塔模型在召回品牌上的分布。我们可以发现不同的head是分别倾向于召回不同的手机品牌,这也证明了多head对于解决语义多义性有比较明显的效果。接下来为大家介绍的是图模型在召回中的应用。图结构适合的任务有:社交网络中广告的投放,社交关系的预测,推荐系统中商品的推荐,新用户的推荐等。那么图模型能够解决搜索中的什么问题呢?前面的语义模型具有一些遗留问题,比如低频商品的embedding学习得不够充分,因为在训练时我们的训练样本使用的是点击的数据,数据分布与线上用户的点击分布是一致的,所以一些低频商品无法获得比较充分的学习。其次,在电商场景下搜索query通常比较短,query侧语义信息比较匮乏。另外,我们的训练数据是由一对query和商品组成的,训练效率较低。使用图模型可以相应地解决这些问题,主要做法是利用用户的点击行为来构建一个异构点击网络。网络节点除了query和商品之外,还有商品的店铺、品牌等。query与商品之间的边是点击关系,商品和品牌以及店铺之间的边是从属关系。利用这样的图结构,我们就可以把更多的query和商品的语义信息聚合,进而提升query和商品的语义表征能力。上图是SearchGCN的网络结构。左边是以query为中心的图结构,右边是以item中心的图结构。两侧我们都是使用二阶的信息:query侧,一阶的节点是用户点击过的商品,二阶节点是商品关联的query和商品本身的属性特征(如品牌、类目等);item侧,一阶的节点是与item关联的query和属性,二阶的节点是一阶节点关联的商品。在实际使用的时候,我们分别聚合query和item侧的二阶信息。值得注意的是,对于当前聚合操作的query和商品的点击对,我们需要分别mask掉对应商品的节点信息,同理对于item侧也需要mask掉对应query的节点信息,以防止训练过程出现信息泄露,导致模型过拟合。图模型中比较关键的是选取消息传递的方式,即如何对节点信息进行聚合和更新。对于第L层的节点,我们需要聚合第L-1层的节点信息,具体做法是对第L-1层的节点使用attention机制做加权求和的计算。我们还需要一个融合操作来对节点本身的信息做聚合,这里我们使用了直接求和的操作,即直接对所有层的节点embedding进行求和,来得到这个节点的最终表示。通过embedding的t-sne可视化表示可以观察模型的效果,上图左侧是baseline语义模型的embedding分布,右侧是SearchGCN得到的embedding分布。从分布的情况与召回的结果来看,右边图模型的分布更为合理,即相同类目的商品的分布更加集中,类目之间的边界也更为清晰。从召回结果来看,电商场景下有一类比较典型的搜索词,即一次搜索中出现多个产品词,如牛奶巧克力。牛奶和巧克力分别是两个产品词,单从字面语义相关性来看,既可以召回牛奶也可以召回巧克力,但是从自然语言理解的角度,牛奶是一个修饰词,真正的产品词是巧克力。在实际的训练数据里,用户点击更多的都是巧克力的商品,所以在图中这个query的邻居节点更多的也是巧克力的商品,这就使得巧克力可以获得更高的学习权重,最终的embedding也更倾向于召回巧克力商品。下面给大家介绍一下同义词模型和同义词模型的召回效果。我们知道同义词改写可以一定程度上扩大商品召回的丰富性。很多商家会在标题中通过同义词堆砌来获得更多曝光,过长的标题会造成不好的用户搜索体验。针对这个问题,业务层面上我们会使用人工构造同义词表的方法来解决,但是这一方法效率低下。所以对同义词的自动生成有一定的需求。这里最大的难点在于缺乏用于大规模训练的同义词对齐语料,所以我们想利用query和点击商品的标题来生成同义词训练样本。模型上主要分为两个阶段,一个query到title的前向生成模型,一个title到query的反向生成模型,模型结构基于transformer。如上图左侧所示,通过两阶段的训练得到query到query的生成模型。但是这种训练方式没有达到我们从query到query生成的直接目的,缺乏query与query的对齐效果。因此,我们将两阶段整合成了一个联合训练的模型,增加了query到query的生成损失。模型的推理是两段式的。对于用户的一个搜索词而言,我们首先会通过前向的生成模型生成一些候选的标题,然后在候选标题中选取概率较高的title,通过反向生成模型来生成最终的query。为了提高生成query的多样性,我们在decode的过程中做了采样的操作。具体地,在decode 的第一步,模型会根据最终的生成概率来选取概率最大的K个token,但是在后续decode时不会继续保留所有token,而是会在K个token里做一个随机采样的过程。以此提高模型的泛化能力,增强最终生成query的多样性。上图罗列可一些在实际应用过程中模型生成query的效果,其中上半部分是分离式模型的生成效果,下半部分是联合式模型的生成效果。两个模型都有一定的生成偏好,但是可以发现相较于分离式模型,联合式模型的生成query的相关性明显更优。最后介绍一下我们的一项新工作:索引联合训练模型。这个工作的主要目的是为了降低ANN向量检索的精度损失问题。现在工业界使用的检索方式大多是基于PQ(Product Quantization)的向量检索,用得比较多的工具是facebook的开源检索库FAISS,而我们前面所介绍的语义模型也是使用FAISS索引。首先来介绍一下基于PQ的向量检索的基本原理。PQ的基本思想是将高维空间映射成低维空间的笛卡尔积,然后在低维空间进行向量的相似度计算。举个例子,首先将1024维的向量划分为8个128维的向量,然后在每个子向量空间里做聚类,得到聚类中心,对聚类中心进行编码后,计算好item向量的子向量到聚类中心的距离,使用最近的中心的编码来表示当前的子向量,同时计算出编码之间的距离并存表,这就是索引构建的基础过程。在进行检索时,首先将query embedding,进行相应的向量切分,然后使用query的子向量在索引空间中寻找最近的类中心,用提前计算好的类中心以及类中心之间的距离和item子向量的类编码,就可以通过查表得到query到item之间的近似距离。通过这样的方法,我们可以极大地减少浮点运算的次数,从而获得检索速度的提升,且量化程度越高检索速度越快。量化操作虽然能够带来速度的提升,但是引入了检索精度损失的问题,它包含两部分:子空间划分带来的计算误差以及通过聚类中心衡量item相似度的计算误差。为此,我们将PQ的过程移植到了模型内部,将子空间和聚类中心进行参数化学习,从而减少计算损失。为了提高可用性,我们将整个PQ过程封装在完整的层中,只需要将嵌入在模型item塔的输出层即可,可移植性较高。PQ层的具体实现可以分为四个过程。首先是旋转操作,即将原始向量与一个正交矩阵相乘,目的是希望将item embedding的dimension做重排序,使得在子空间划分后,落在相同子空间的子向量的相关度更高。第二步是一个粗粒度的量化过程(coarse quantization),其目的是为了提高检索效率。具体做法是对完整的item向量做一次聚类,计算向量到类中心的距离,最后使用最近的中心对来表示原始向量。第三步是PQ,这一步与前面介绍的过程一致。首先进行子空间的划分,然后在子空间内对子向量进行聚类,最后利用子空间类中心来做向量表示。最后一步我们需要使用第一步的正交矩阵的逆来恢复原始向量dimension的顺序。由于我们子空间的划分和聚类中心始终是与最终的优化目标保持一致,这样做就能够减少直接PQ所造成的的精度损失。我们通过多维度的实验对模型效果进行了对比。从实验结果中可以看到,在不同的数据集上(private数据集(京东电商的数据)、MovieLens和Amazon数据集(开源数据集)),precision@100和recall@100都有不同程度的效果提升。上图右上侧展示了t-sne embedding可视化的结果,横向对比来看,同一个模型在不同量化参数下,随着量化程度的加深(即量化子空间划分程度加深),embedding的分布会从均匀分布逐渐转变为很多更小的簇,这与PQ的过程保持一致。因为在PQ的过程中,我们对向量做了子空间的划分,在子空间内部会将向量纳入不同的类中心,所以子向量会在类内形成更小的簇。纵向对比来看,在使用相同量化参数时,可以发现Poeem的分布更加均匀,子空间的聚类更加合理。这也解释了为什么我们的联合训练模型在召回率和准确性上回去的更好的效果。其次,在工程上,索引联合训练模型也会有一定的效率提升。由于索引的构建是在训练模型时就已经完成,所以就不需要额外构建索引,从时间开销上具有更高的效率价值。从模型serving的角度来看,索引联合训练模型在训练完毕后可以同时将模型和索引导出成一个整体,线上可以直接使用model server进行模型的加载,不需要人工地将model server和index server构建一个完整的服务。所以无论从召回精度,生产效率还是从模型服务的工程复杂度而言,索引联合训练模型都具备巨大的优势。这个项目已经在github上开源,里面做了一些tutorial,比较容易上手,整个代码库也已经封装成一个python包,大家可以很方便地通过下载安装python包来将PQ层引入到相应的模型中。 A:我们首先会将正交矩阵初始化为identity矩阵,随后会有一个初始化的迭代过程,采用的是steepest block coordinate descent算法。我们最终的训练目标是希望优化子向量空间的分布,使得PQ后落在同一子空间的embedding相似度尽量高,从而减少PQ精度损失。Q:同义词构建的模型的损失函数是前向损失和后向损失相加吗?A:对,在分离式模型中,损失函数就是将这两部分加在一起。在联合训练模型中,我们额外加入了query到query的生成概率损失,并加入一个权重进行调节。A:京东APP是京东零售的载体和渠道。当然还有其他的渠道,比如PC端、微信小程序、京喜APP、京东极速版等。召回侧的话,我们会负责所有渠道的召回工作,但是在不同渠道,因为用户的表现和偏好有差异,所以召回模型对于特征处理和训练数据也有所不同。Q:多头注意力的双塔模型中projection matrix是全连接层吗?A:对,我们第一版模型是每个头分别乘上一个权重矩阵来做query的映射。但是后面我们进行了改进,在query侧,在输入层会进行dimension上的翻倍操作,即将维度扩展为原维度的head倍,然后直接做split操作即可,我们发现效果比直接使用多个权重矩阵进行映射的效果更好。




 下载APP
下载APP