
依托目前的发展阶段和特征,试图对相关核心问题进行拆解、梳理与展望。
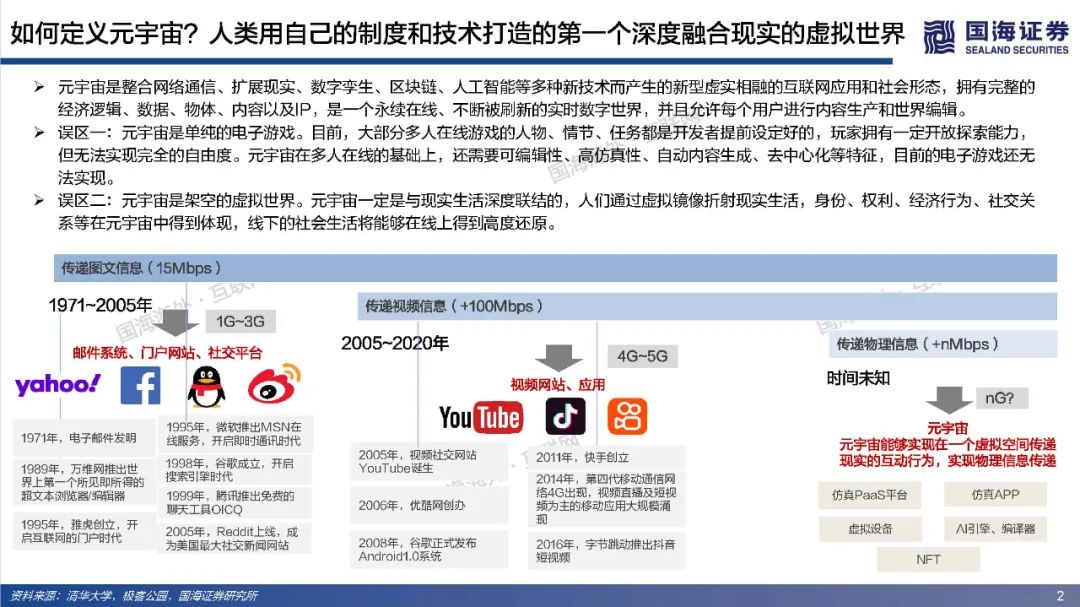
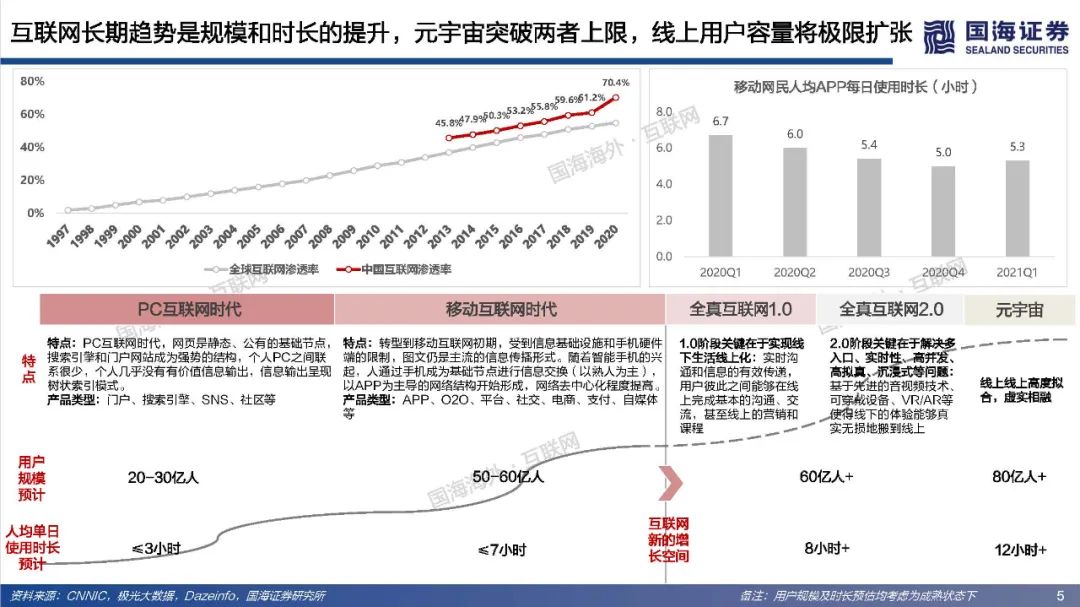
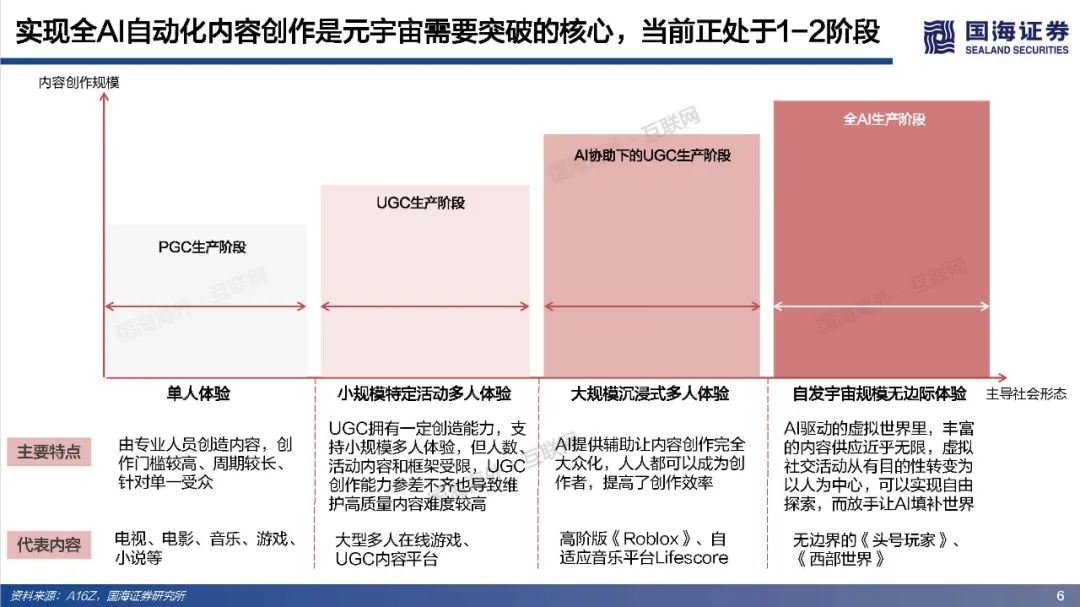
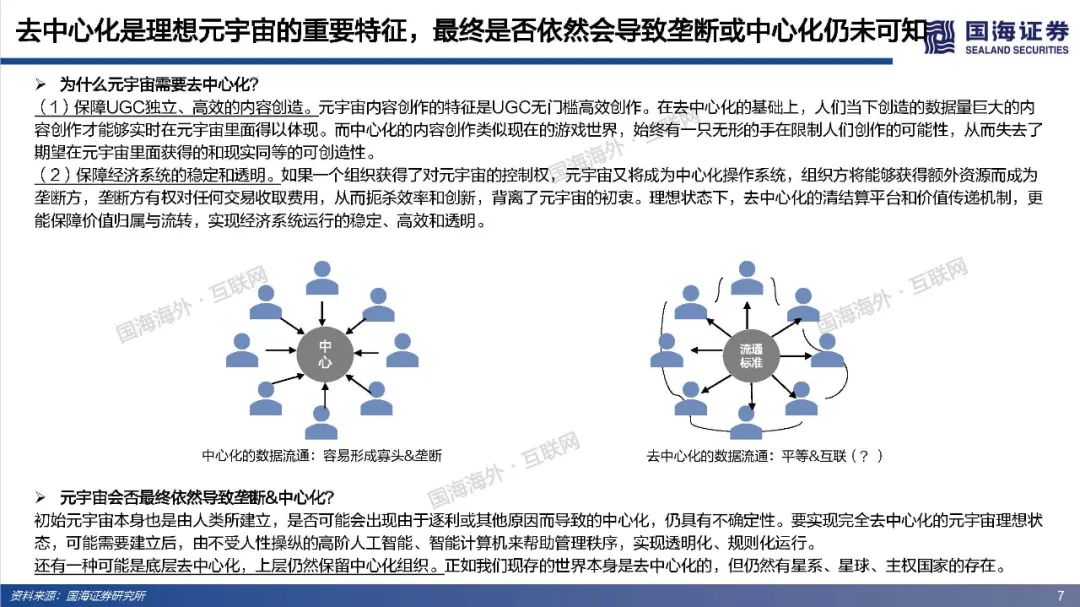
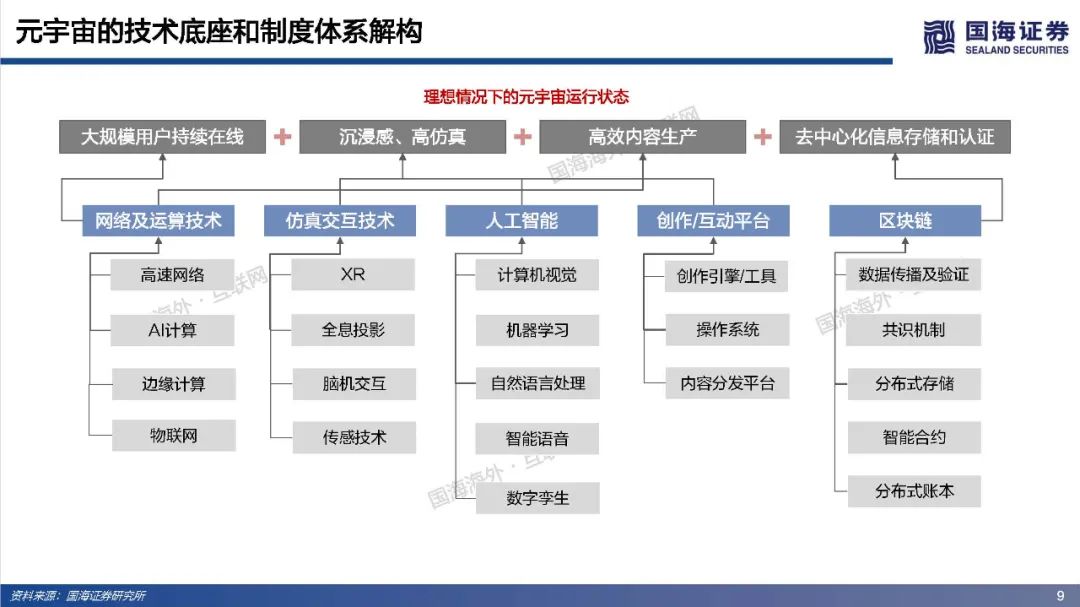
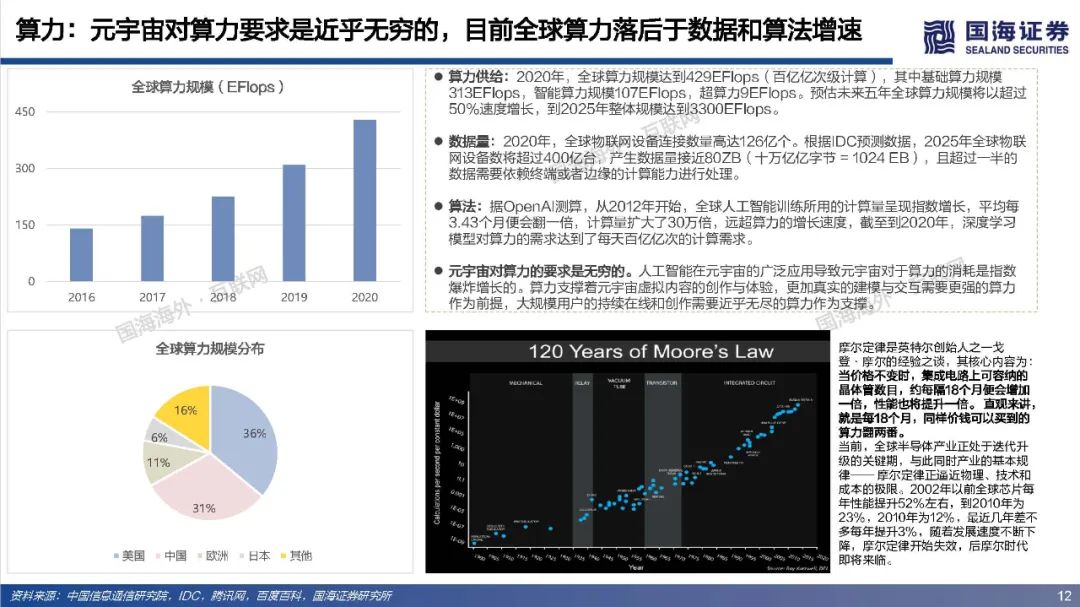
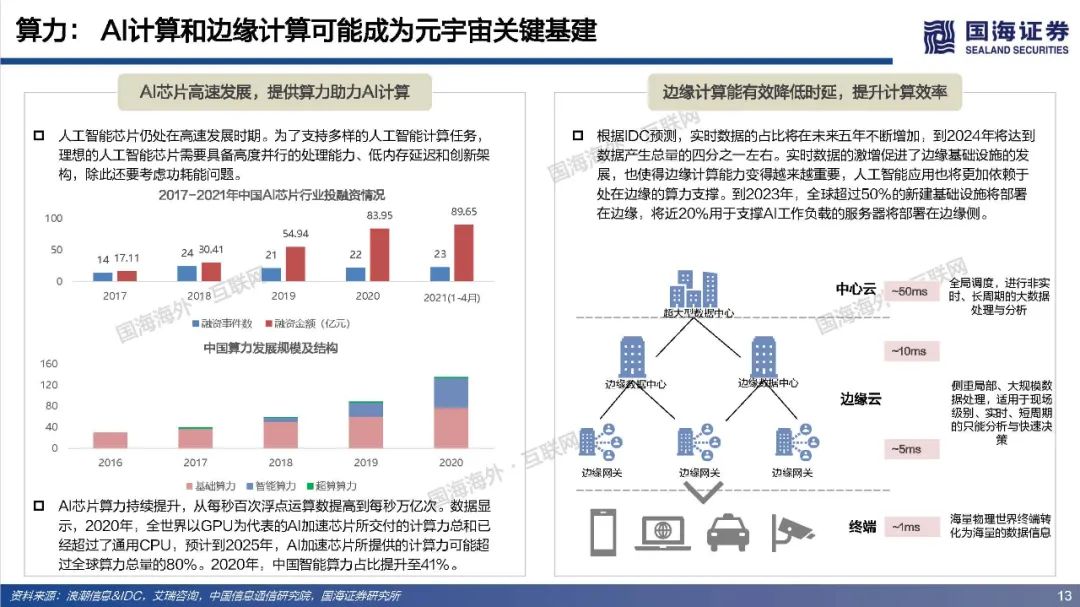
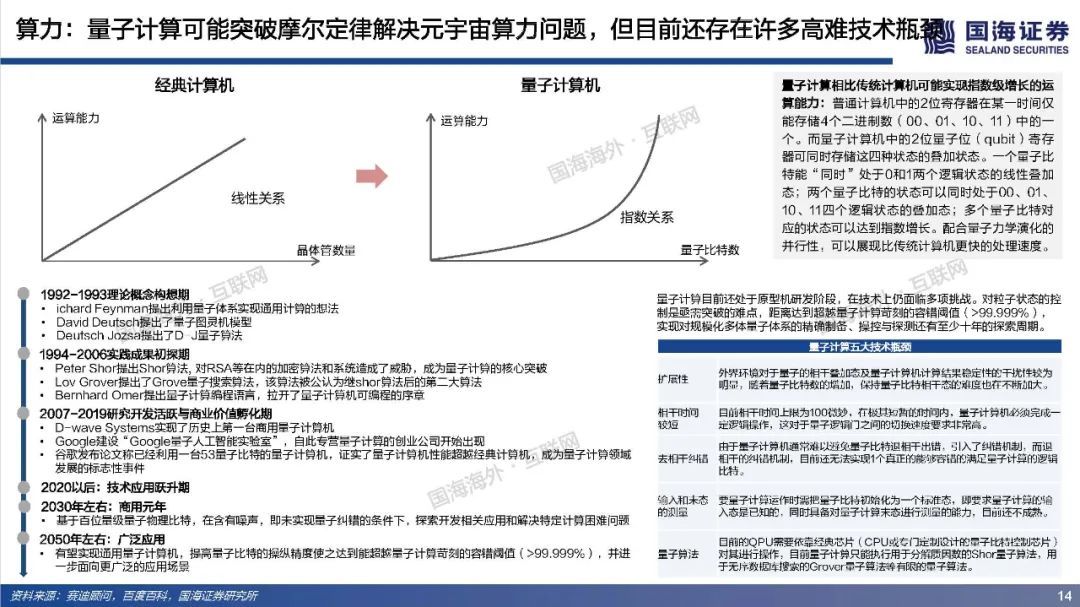
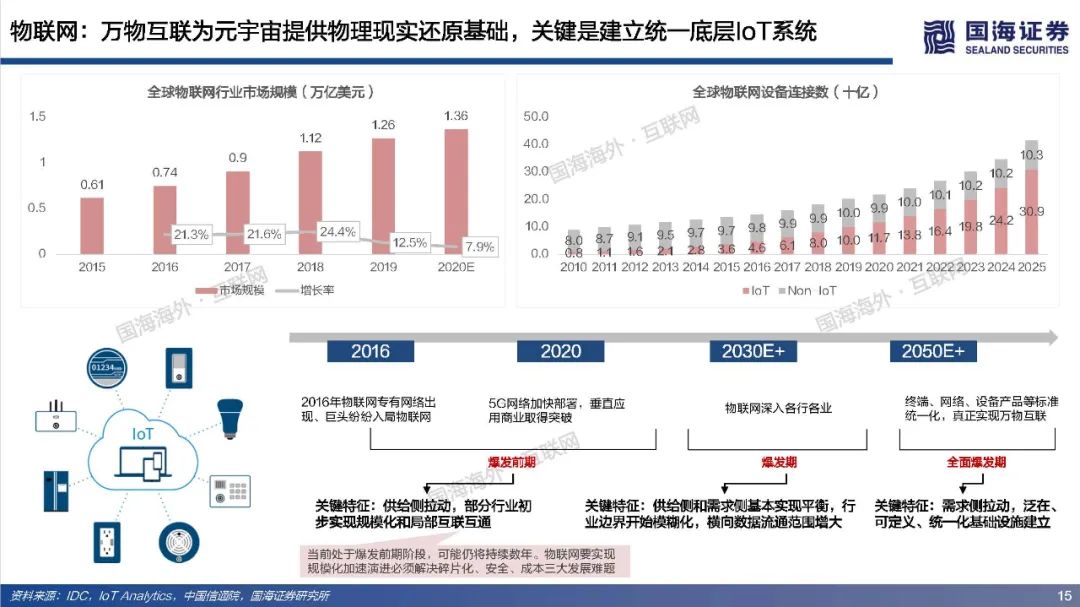
元宇宙寄托了人类对自由探索理想虚拟世界的美好愿景,其部分功能和应用可能得到阶段性实现,但其终极形态尚未达成共识,元宇宙最终会是人类得以自在生活其中的第二乐园,还是如《黑客帝国》Matrix一样的反乌托邦世界?本篇专题报告,依托目前的发展阶段和特征,试图对相关核心问题进行拆解、梳理与展望,主要包括:如何理解元宇宙?理想的元宇宙有何关键特征?通往元宇宙需要怎样的技术底座和制度体系?当前的技术发展现状距离元宇宙有多远?如何看待元宇宙产业链机会?巨头的布局情况如何?https://data.eastmoney.com/report/zw_industry.jshtml?infocode=AP2021111815297433811、如何理解元宇宙?——理想状态是自发无边际的社会体验(1)如何定义元宇宙:从信息传递角度,元宇宙将使得人类从传递图文信息、传递视频信息进化到传递物理信息,实现在一个虚拟空间传递现实的互动行为。元宇宙是整合网络通信、扩展现实、数字孪生、区块链、人工智能等多种新技术而产生的新型虚实相融的互联网应用和社会形态,拥有完整的经济逻辑、数据、物体、内容以及IP,是一个永续在线、不断被刷新的实时数字世界,并且允许每个用户进行内容生产和世界编辑。(2)理想的元宇宙将实现效率的革命性提升和线上用户容量的极限扩张。在一个理想的元宇宙世界,物理世界的无限虚拟化使得生产要素无限丰富、生产力无限充足、近乎于0的边际成本使得社会生产效率得到了巨大的提升;互联网长期趋势是规模和时长的持续提升,元宇宙突破两者在现有条件下的上限,人类线上用户容量将极限扩张(80亿人+、12小时+)。(3)实现全AI自动化内容创作是元宇宙需要突破的核心。Metaverse是内容创作的最高阶,Metaverse将实现一个AI驱动的虚拟世界,丰富的内容供应近乎无限,虚拟社交活动从有目的性转变为以人为中心,可以实现自由探索,能够放手让AI填补世界,才能真正实现自发宇宙规模无边际体验。(4)去中心化是理想元宇宙的重要特征,最终是否依然会导致垄断或中心化仍未可知。元宇宙的去中心化一方面是为了保障UGC独立、高效地内容创造;另一方面是保障经济系统的稳定和透明,遏制寡头和垄断。然而初始元宇宙本身也是由人类所建立,是否可能会出现由于逐利或其他原因而导致的中心化,仍具有不确定性。要实现完全去中心化的元宇宙理想状态,可能需要建立后,由不受人性操纵的高阶人工智能、智能计算机来帮助管理秩序,实现透明化、规则化运行。还有一种可能是底层去中心化,上层仍然保留中心化组织。理想情况下的元宇宙运行状态=大规模用户持续在线+高沉浸感/高仿真+高效内容生产+去中心化信息存储和认证。为实现这一理想运行状态,至少需要五层基础技术底座支撑:网络及运算技术、仿真交互技术、人工智能技术、创作工具/内容分发平台和区块链技术。整体来看,我们认为元宇宙是人类对一个能够自由探索的理想虚拟世界的美好愿景,但目前距离元宇宙得以实现所要求的技术基础还相去甚远,未来还有很长的路要走。(1)网络:预计元宇宙至少需要6G以上网络,6G网络有望在2030年开始商用。在覆盖范围上,6G网络将是一个地面无线与卫星通信集成的全连接世界,通过将卫星通信整合到6G移动通信,实现全球无缝覆盖,“万物互联”才可能真正实现。具有AI功能的6G有望释放无线电信号的全部潜力,转变为智能无线电,为元宇宙用户提供实时、流畅的沉浸式体验。(2)算力:元宇宙对算力要求是近乎无穷的,目前全球算力远远落后于数据和算法增速。人工智能在元宇宙的广泛应用导致元宇宙对于算力的消耗是指数爆炸增长的,算力支撑着元宇宙虚拟内容的创作与体验,更加真实的建模与交互需要更强的算力作为前提,大规模用户的持续在线和创作需要近乎无尽的算力作为支撑。量子计算可能突破摩尔定律解决元宇宙算力问题,但目前还存在许多高难技术瓶颈,预计在2050年以后才有可能实现通用量子计算机,提高量子比特的操纵精度,从而有条件进行面向更广泛的应用场景。(3)物联网:万物互联为元宇宙提供物理现实还原基础,当前物联网发展还处于爆发前期阶段,可能仍将持续数年。物联网要实现规模化加速演进必须解决碎片化、安全、成本三大发展难题。要真正实现真正实现万物互联,关键是建立统一底层IoT系统,实现终端、网络、设备产品等标准统一化。(4)仿真交互:2021年,全球市场VR头显预计出货837万台,其中中国市场VR头显预计出货143万台,预计全球AR/VR硬件市场出货量在未来五年呈现稳步增长趋势,全球市场规模有望在2025年超3500亿元。目前,虚拟现实已经有较多垂直领域落地应用场景,产业机会值得关注,然而XR设备尚未实现理想的沉浸式体验,仍存在价格成本高、使用感差、使用空间限制、便携性差、续航时间短、设备兼容性较差等问题,距离元宇宙所要求的高沉浸、高便携度、高兼容性,能够进行大规模推广的状态还相去甚远,同时在XR设备内容供给上也存在内容品类少、内容数量少、开发节奏慢等问题,内容供给端仍需大量扩充以满足多人群多场景需求。(5)区块链:从发展历程来看,区块链经历了去中心化账本、去中心化计算平台、去中心化金融,现在已经发展至NFT阶段,NFT可能解决元宇宙生产资料和资产所有权问题。近一年来,海外NFT交易平台火爆,国内互联网大厂也纷纷试水数字藏品,但国内出于监管考虑目前暂时无法公开自由交易。当前的NFT市场,流动性相对匮乏,应用领域和场景较为单一和小众,也存在一些炒作行为,暂时没有实现市场自由定价,距离大规模落地,还需要长期的积累和沉淀。3、如何看待元宇宙产业链机会?——巨头涌入,机遇与风险并存(1)Roblox:初具元宇宙雏形,在游戏层面实现了内容可编辑性,平台年轻化的群体和良好的游戏社区氛围实现高用户活跃度和粘性,2021Q3Roblox日活跃用户数4730万人,人均单日使用时长高达2.63小时。然而在元宇宙的进程中,Roblox还处于比较早期阶段,其提供的工具虽然实现了自由创作,仍然具备一定门槛性,限制了人们自由创作的边界,后续全球化+高龄化的扩张破圈有待观察。(2)腾讯:从消费互联网到产业互联网,腾讯对Metaverse的布局已深入底层基础架构、线上商业平台、内容版权、社交媒体等各个层面,同时通过对外投资并购进一步打开元宇宙技术边界。整体来看腾讯在游戏、社交、音视频解决方案、数字孪生和全息投影、引擎技术等方面都处于行业领先位置,在目前元宇宙相关赛道公司中具备较强优势,持续看好公司未来在开放世界游戏、云计算、人工智能、仿真交互设备等方向布局。(3)字节跳动:短视频形态产品优势稳固,全球化能力较强,同时积极布局游戏、虚拟社交、VR等元宇宙细分赛道,包括收购中国版Roblox《重启世界》母公司,在海外推出主打AI捏脸功能的虚拟社交产品Pixsoul,90亿收购国内排名第一的VR厂商Pico等。未来重点关注在游戏和社交领域布局产品增长情况,以及硬件设备Pico出货和用户破圈能力。(4)Facebook:改名Meta,宣布5年内转型元宇宙公司,涉足最深最广,在组织架构、软件、硬件、内容、数字货币等全方位进行元宇宙布局。组织架构上,成立高规格元宇宙产品团队,由FacebookAR/VR领域副总裁和Instagram现任产品副总裁带队;软件上推出SparkAR、PresencePlatform、Pytorch等底层开发工具,帮助发展和搭建元宇宙社区;硬件上Oculus系列在全球XR设备市场中占据领先地位,最新产品OculusQuest2在2021Q1出货量高达460万台,占据了75%的市场份额;内容上收购多家VR游戏、云游戏开发商,推出HorizonWorlds、HorizonWorkrooms等虚拟社交和办公平台;数字货币上,继libra之后积极推广数字货币diem。(5)EpicGames:融资10亿押注元宇宙赛道,兼具内容和技术优势,《堡垒之夜》保持高热度运营并多次探索具有元宇宙体验的内容形态如线上演唱会、线上电影等,虚幻引擎作为目前行业最强引擎,在模型质量、真实度等方面长期领先。然而高难度的虚幻引擎,开发门槛较高,目前还难以成为元宇宙所要求的低门槛UGC平台的创作工具,未来关注公司在自动化AI生成等方面技术进展。(6)英伟达:在虚拟世界中进行实时协作的计算机图形与仿真模拟协作平台Omniverse以其高效、低成本特征,在建筑、传媒、产品设计、自动驾驶等多个领域得到快速应用,元宇宙在Omniverse的推动下率先在工业领域有了切实的落地,同时英伟达在在AI和高性能计算以及芯片领域有深厚积累,有望为元宇宙底层技术架构添砖加瓦。











 下载APP
下载APP