
AAAI 2021 | 华为诺亚方舟实验室AI&上交大叶南阳提出算法DecAug,面向多维度非独立同分布域泛化问题

新智元报道
新智元报道
来源:AAAI 2021
【新智元导读】华为诺亚方舟实验室AI理论团队和上海交通大学叶南阳联合提出一种面向多维度非独立同分布域泛化问题的算法DecAug 。
华为诺亚方舟实验室AI理论团队和上海交通大学叶南阳联合提出一种面向多维度非独立同分布域泛化问题的算法DecAug 《DecAug: Out-of-Distribution Generalization via Decomposed Feature Representation and Semantic Augmentation》,已在AAAI 2021 (论文地址: https://arxiv.org/pdf/2012.09382)发表。
该工作首次将此前联系较少的数个领域,如Domain generalization, stable learning, causal inference统一在Out-of-Distribution (OoD) 的问题背景下,揭示了机器学习中受到广泛关注的不同领域方向的内在联系,提出了第一种同时在几个领域都取得SOTA性能的方法。
研究背景
传统的机器学习算法,通常假设训练样本和测试样本来自同一概率分布 Independent and Identically Distributed (IID)。但是对于 Out-of-Distribution (OoD)场景,即训练样本的概率分布和测试样本的概率分布不同的情况,训练出的模型很难在目标域取得良好的表现。如何设计出一种通用的OoD泛化框架是一项具有挑战性的任务,这主要是由于在现实生活中广泛存在的correlation shift和diversity shift问题。大多数以前的方法只能处理单一维度的OoD问题,例如跨域偏移或相关性外推,这限制了其在实际场景中的广泛应用。
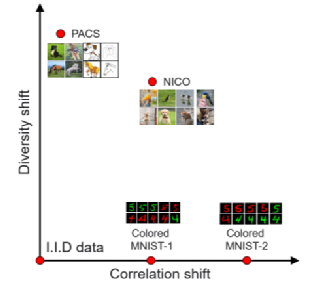
图1:不同的数据集存在两种维度OoD问题:Correlation shift 和 Diversity shift。实验表明现有的许多OoD算法只能处理好单一维度的OoD问题。
因此,本文提出了基于特征分解和语义增广的方法DecAug,来处理多维度非独立同分布数据的问题,同时可以泛化到未知目标域的情况。具体地,首先在特征层面分解高维表征,基于损失函数梯度正交的正则化方式分解类别相关与语境相关的高维向量。针对语境相关的特征,利用基于梯度的增广机制,在特征层面生成新语境的样本,从而增强模型的域泛化性能。
方法概述
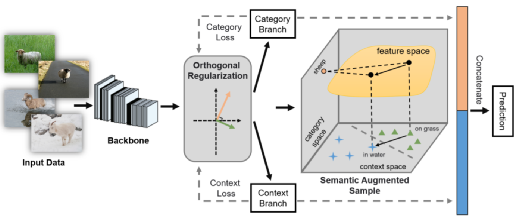
图2:DecAug框架:输入的图片首先通过骨干网络提取特征,基于损失函数梯度正交的正则化方式,高维表征被分解为类别相关和语境相关的两个分支。基于梯度的语义增广机制作用于语境相关分支,在特征层面生成新语境样本。
![]() 特征分解:
特征分解:
图2为本文提出的DecAug框架,可以同时处理两种维度的OoD问题。考虑训练数据集为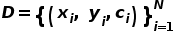 的图片分类任务,输入图片首先通过骨干网络映射到特征空间,获得高维特征
的图片分类任务,输入图片首先通过骨干网络映射到特征空间,获得高维特征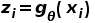 ,并在特征层面分解为两个分支:类别相关分支
,并在特征层面分解为两个分支:类别相关分支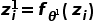 与语境相关分支
与语境相关分支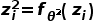 。我们使用标准交叉熵函数
。我们使用标准交叉熵函数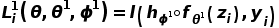 和
和 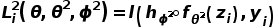 来分别优化这两个分支。为了更好的分解类别相关与语境相关的高维特征,DecAug限制类别相关分支的损失函数对于
来分别优化这两个分支。为了更好的分解类别相关与语境相关的高维特征,DecAug限制类别相关分支的损失函数对于 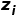 的梯度正交于语境相关的损失函数对于 的梯度。为了确保正交性,DecAug会最小化损失函数:
的梯度正交于语境相关的损失函数对于 的梯度。为了确保正交性,DecAug会最小化损失函数:
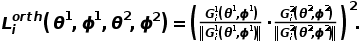
![]() 数据增广:
数据增广:
DecAug针对语境相关特征进行数据增广的操作来减轻分布偏差带来的影响。在语义特征空间存在着多个不同的分布偏差方向。为了确保在不同的环境中都有好的效果,本文针对OoD泛化的最差场景,通过在特征空间生成对抗扰动的样本来进行数据增广操作和训练模型。具体来说,DecAug对语境相关的特征进行语义增广操作:
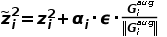 ,
,
其中,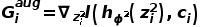 代表了语境相关分支对于
代表了语境相关分支对于 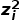 的梯度。
的梯度。
语义增广操作之后,DecAug合并类别相关特征及增广后的语境相关特征进行最终的类别预测。整体的损失函数如下定义:
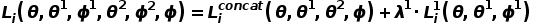
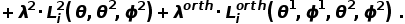
本文将DecAug的训练过程定义为如下优化问题:
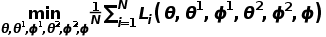 ,
,
随机梯度优化算法可以被用来优化所提到的目标函数。
实验验证
我们在公开数据集PACS,Colored MNIST和NICO上验证DecAug算法,对比其他的OoD generalization算法。
![]() 准确性:
准确性:
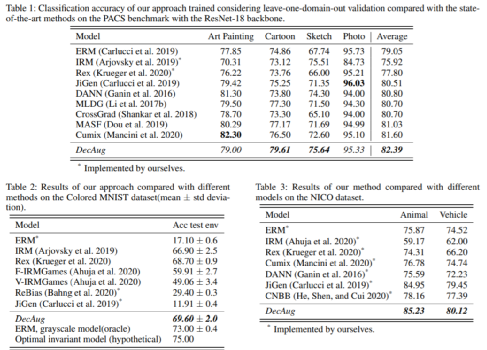
从上图实验结果可以看出,相比于风险正则化方法(e.g., Rex, IRM) 以及典型的域泛化方法比如 (e.g., JiGen), 通过基于损失函数梯度正交的正则化方式以及语义增广机制,DecAug算法在不同数据集上均取得最优表现。
![]() 消融分析:
消融分析:
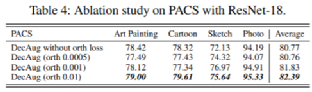
上图展示了在PACS数据集上基于损失函数梯度正交正则化方式对模型的贡献度。without orth loss 表示不使用损失函数梯度正交,下面三行是不同的正则化强度。从结果可见,使用基于损失函数梯度正交的正则化方式可以带来OoD泛化性能的提升。

上图展示了DecAug在PACS数据集上不同变体的性能表现。可以看到,直接地融合DecAug 和DANN对抗损失,效果提升有限。另外,将正交正则化限制直接作用于特征,甚至可能带来负向提升。由此可见,DecAug的两分支结构及针对语境特征的对抗增广机制有助于提升模型的OoD泛化性能。
![]() 模型可视化:
模型可视化:

上图可视化了两个分支的梯度注意力分布,考察模型的可解释性。第一行是在PACS数据集随机选出的4种类别8个图片,下面两行分别是对应的类别分支及语境分支的注意力。可以看到,类别分支注意力会更关注在前景部分,而语境分支会同时对包含域信息的不同背景语境敏感,说明DecAug有效分解了类别相关及语境相关的高维特征。
总结
本文提出了一种基于特征分解和语义增广面向多维度OoD泛化问题的模型DecAug。基于损失函数梯度正交的正则化方式,DecAug将输入数据在特征层面分解为类别相关及语境相关的特征,来处理训练数据与测试数据之间的分布偏差。基于梯度的语义增广机制作用于语境相关分支来提升模型的OoD泛化性能。DecAug在三个公开数据集上均呈现出比之前的基于风险最小化正则及传统域适应算法更好的OoD泛化性能。
参考文献:
[1] Bai, H., Sun, R., Hong, L., Zhou, F., Ye, N., Ye, H. J., Li, Z. (2020). DecAug: Out-of-Distribution Generalization via Decomposed Feature Representation and Semantic Augmentation. arXiv preprint arXiv:2012.09382.
