
AAAI 2020 | 上交大&云从科技提出DCMN+ 模型,破解「阅读理解」难题,获全球领先成绩
来源:知乎
Dual Co-Matching Network for Multi-choice Reading Comprehension
DCMN+是一种针对多选阅读理解的预训练词嵌入微调方法,能在BERT和XLNet输出的基础上达到在多选阅读理解任务上的SOTA水平。
We will show the way to use a strong pre-trained language model may still have a heavy impact on MRC performance no matter how strong the language model itself is.
作者认为:无论预训练模型本身多强大,针对具体任务定制的恰当的应用方法都能使它们如虎添翼。
而对于多选阅读理解任务,提高性能的关键在于对P(Passage,即文本段落)、Q(Question,问题)、A(Answer,备选答案)之间关联的建模。
多选阅读理解的样本以  三元组的形式描述,DCMN+的设计思路就是先从文本中双向地提取P-Q、P-A、Q-A之间的关联,再通过门机制将其融合到词嵌入中。在此基础上,作者又引入了两种策略以模仿人类答阅读理解问题的思维模式:Passage Sentence Selection和Option Interaction。最后,模型通过一个双向匹配模块(Bidirectional Matching)来预测答案选项。
三元组的形式描述,DCMN+的设计思路就是先从文本中双向地提取P-Q、P-A、Q-A之间的关联,再通过门机制将其融合到词嵌入中。在此基础上,作者又引入了两种策略以模仿人类答阅读理解问题的思维模式:Passage Sentence Selection和Option Interaction。最后,模型通过一个双向匹配模块(Bidirectional Matching)来预测答案选项。
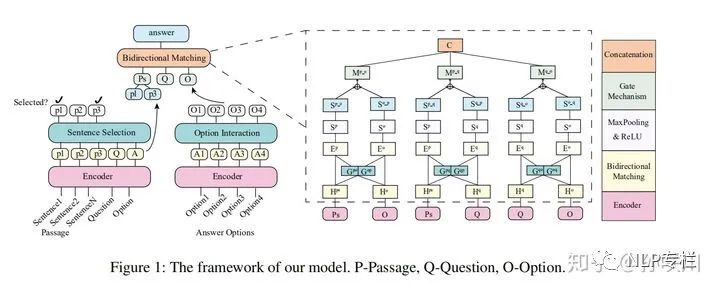
Model
Input Representation
以BERT或XLNet输出的预训练词嵌入作为输入文本的词向量表示。
Passage Sentence Selection
通常在完成阅读理解选择题时,对于每一个选项,我们会尝试从原文中找出与其最密切相关的段落或语句作为选择或排除这个选项的依据。此前的多选阅读理解模型都是一次性扫描整篇文章来学习文章的表示,这实际上是低效且违背直觉的。
如下图所示,作者对阅读理解数据集如RACE和COIN进行了采样分析,发现能作为选项依据的内容通常集中在原文中的1-3句话中,这侧面表明了将关注的焦点放在这些关键少数上的重要性。

为了找出原文中的选项依据,作者引入了2种打分机制:
设原文表示为:  ,对于任取的句子
,对于任取的句子  ,考察三元组
,考察三元组  。
。
 、
、  、
、  为相应的词嵌入矩阵,其中
为相应的词嵌入矩阵,其中  为词嵌入向量的大小,
为词嵌入向量的大小,  表示句子
表示句子  的长度。定义如下的评分标准,选取分数最高的
的长度。定义如下的评分标准,选取分数最高的  个句子。
个句子。
step1.Cosine score

如上所示,首先依次对各单词对计算余弦相似度,上式中的  表示candidate option和句子 的相似度矩阵,其中
表示candidate option和句子 的相似度矩阵,其中  为candidate option的第
为candidate option的第  个单词与句子 中的第
个单词与句子 中的第  个单词的余弦相似度;
个单词的余弦相似度;  表示问题和句子 的相似度矩阵,矩阵元素与 同理。
表示问题和句子 的相似度矩阵,矩阵元素与 同理。
接着对相似度矩阵的各行求最大值,得到一个最大相似度向量以描述句子 与问题、句子 与candidate option之间的相关程度。
最后对两个最大相似度向量的元素求和,依长度分别得到两项加权平均相似度,相加得到最终的score,它描述的是三元组 的综合相关度。
step2.Bilinear score
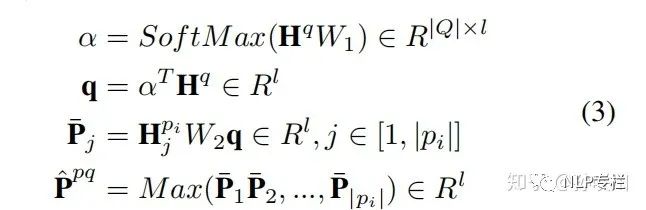
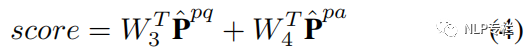
其中  、
、  都是可训练参数矩阵。前两行得到的
都是可训练参数矩阵。前两行得到的  是类似于一个Attention Head的输出,即引入了自注意力的Question representation,这么做有利于找到问题句子中的重点。
是类似于一个Attention Head的输出,即引入了自注意力的Question representation,这么做有利于找到问题句子中的重点。
 表示句子 的第 个单词与Question的双线性相关度,在各相关度中取最大值,得到
表示句子 的第 个单词与Question的双线性相关度,在各相关度中取最大值,得到  即 与
即 与  的相似度向量,
的相似度向量,  的计算同理。
的计算同理。
最后对两者加权求和再相加得到最终的相关度评分。
将得分最高的 个原文句子选出并拼接起来,得到新的段落  待用。
待用。
Answer Option Interaction
在人类做阅读理解题的时候,之所以最终选择某一个选项并不单纯是因为这个选项看上去正确,而是通过与其它选项进行对比后认定其它选项不对,才确定要选择这个选项作为答案。
作者以此为灵感,引入了comparison information以将各个选项关联起来以进行对比。
对于备选选项  ,其词嵌入矩阵为
,其词嵌入矩阵为  ,定义选项 与
,定义选项 与  的对比向量如下:
的对比向量如下:

上述两式通过双线性注意力融合 与 的表示,得到的  是 的 -aware representation,文中称为interaction representaion。
是 的 -aware representation,文中称为interaction representaion。
接着通过一个门将interaction representation融合到原始的representation中。

 是选项 的
是选项 的 个interaction representation竖向拼接得到的矩阵,通过一个可训练矩阵将其变形,通过门以后得到
个interaction representation竖向拼接得到的矩阵,通过一个可训练矩阵将其变形,通过门以后得到  即选项 的other-options-aware-represention。
即选项 的other-options-aware-represention。
记  为问题 的所有candidate options的集合。
为问题 的所有candidate options的集合。
Bidirectional Matching
通过前述的两个方法,将  替换为 ,将
替换为 ,将  替换为
替换为  ,得到新的三元组
,得到新的三元组  ,现在就可以通过Bidirectional Matching得到三元组中两两之间的pairwise representation。
,现在就可以通过Bidirectional Matching得到三元组中两两之间的pairwise representation。
以Question和Answer的Bidirectional Matching Representation为例说明:
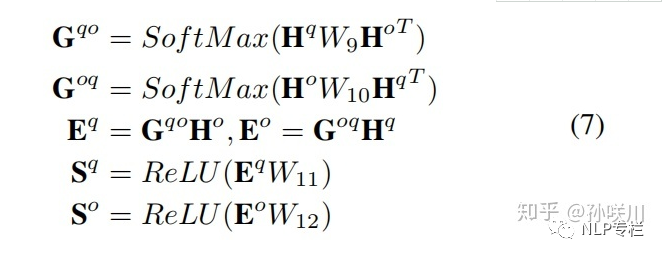
上述过程同样通过双线性注意力机制来得到对称的双向表示。
其中  和
和  分别为Q与A的双线性权重矩阵,
分别为Q与A的双线性权重矩阵,  和
和  分别为Question的Option-Aware Representation和Option的Question-Aware Representation。
分别为Question的Option-Aware Representation和Option的Question-Aware Representation。
接着按行MaxPooling再通过一个门计算出融合后的QA-Pair-Representation  ,过程如下:
,过程如下:
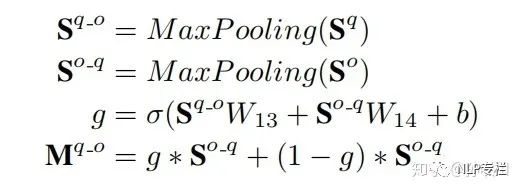
 和
和  的计算同理。
的计算同理。
Objective Function
对于每一个三元组,将  拼接起来得到这个三元组的联合表示
拼接起来得到这个三元组的联合表示  。
。
设  为三元组
为三元组  的联合表示,再设
的联合表示,再设  为题目的答案选项,定义目标函数如下:
为题目的答案选项,定义目标函数如下:

其中  为candidate option的个数,
为candidate option的个数,  为可学习参数向量。
为可学习参数向量。
最小化上式即最大化选中正确选项的概率。
Experiment
实验数据集概览如下表:
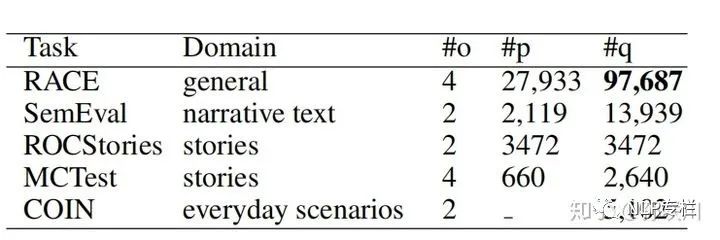
其中#o表示备选选项的平均个数,#p表示文章个数,#q表示问题个数。
一、在RACE数据集上的表现
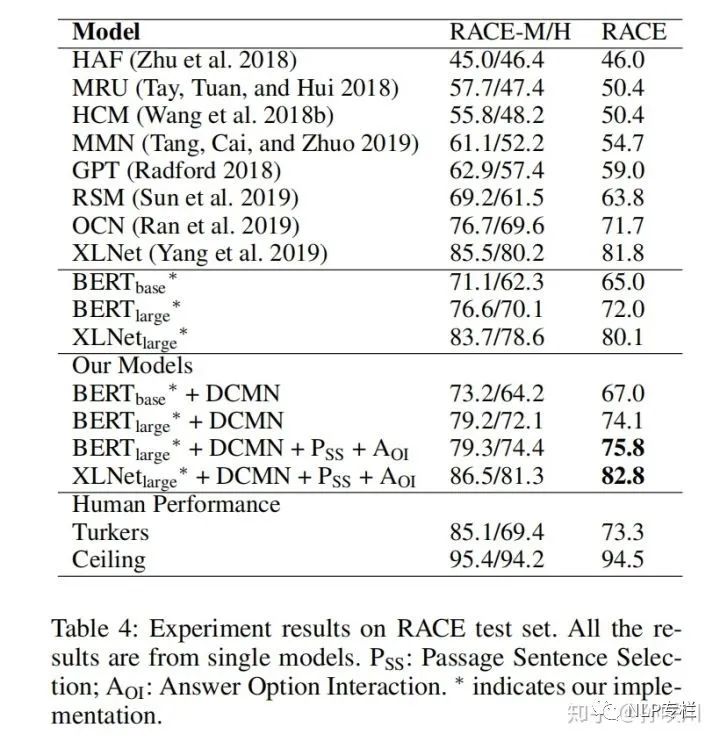
其中  表示Passage Sentence Selection,
表示Passage Sentence Selection,  表示Answer Option Interaction,DCMN表示 bidirectional matching strategy。
表示Answer Option Interaction,DCMN表示 bidirectional matching strategy。
从上表可以看出,将本文提出的方法应用到BERT和XLNet输出的词嵌入上可以大幅提升它们在多选项阅读理解任务中的性能。
对于BERT-base,DCMN=2%;
对于BERT-large,DCMN=2.1%,PSS+AOI=1.7%;
对于XLNet-large,DCMN+PSS+AOI=2.7%。
二、消融实验
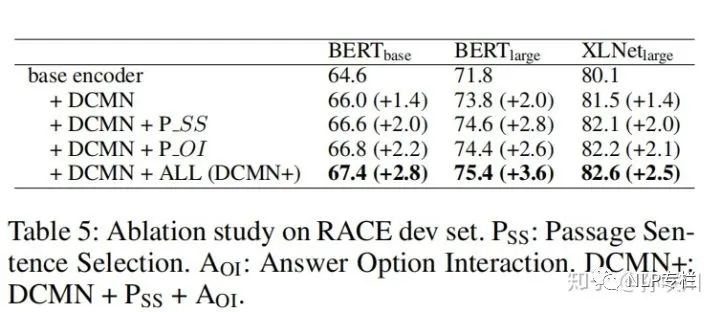
可以看出对性能影响最大的还是DCMN,但PSS和AOI也能各自带来一些提升。
三、在其它数据集上的表现
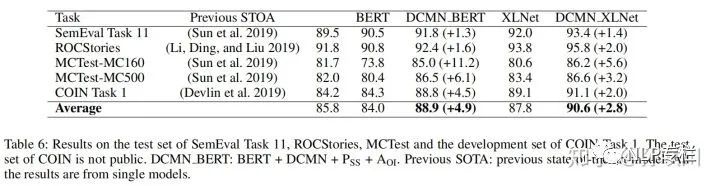
可以看出本文的模型在各数据集上都达到了SOTA表现。
四、模型细节设定的影响
1、单向表示和双向表示在RACE上的对比
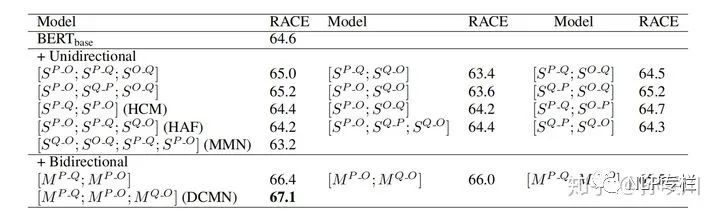
可以看出三元组两两之间的双向表示相较于单向表示带来了显著的性能提升。
2、余弦和双线性两种评分标准的比较和不同的 值的差异
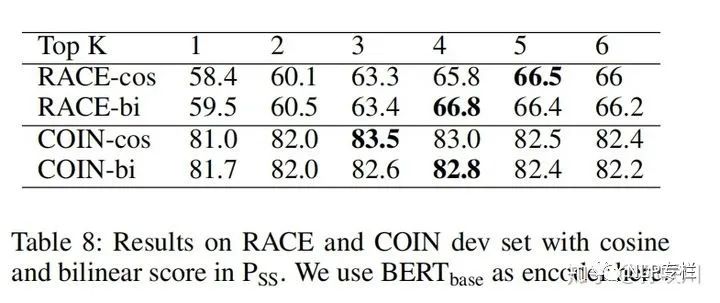
余弦和双线性相关度各有所长,没有明显的差距。
3、 取值对性能的影响可视化:
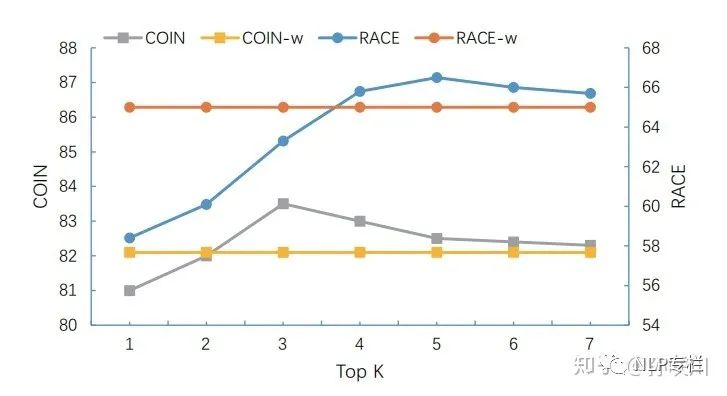
可以认为在BERT-base下最佳的取值在3-5之间。
五、模型在不同类型问题上的准确率
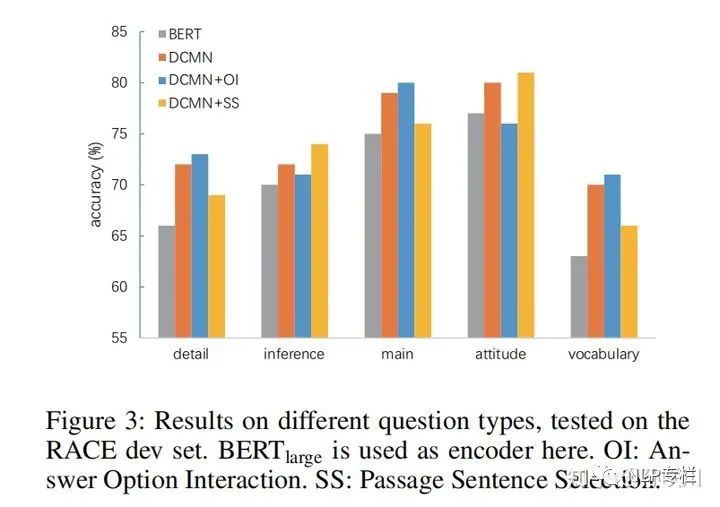
detail:文章细节
inference:推理
main:主旨
attitude:作者态度
vocabulary:同义词
可以看出模型对于把握文章主旨和作者态度更加擅长;PSS有助于推断作者态度却会干扰对文章主旨的解读;AOI则更有助于把握文章主旨,但同时也会干扰对作者态度的判断。
Related Works
作者总结了本文模型之所以超越以往工作的理由在于:
(1)单向表示不能很好地捕捉两个序列之间的相关性
(2)本文在融合双向表示时保持了在两个方向上的对称性,作者认为在双向表示中,保持两个方向上表达的对称性是十分重要的。例如:对两个地位并不等价的矩阵进行拼接就会破坏表达的对称性,这往往会带来次优的结果。
They are different from our work in that
(i) we select the sentences by modeling the relevance among sentence-question-option triplet, not sentence question pair.
(ii) Our model uses the output of language model as the sentence embedding and computes the relevance score using these sentence vectors directly, without the need of manually defifined labels.
(iii) We achieve a generally positive impact by selecting sentences while previous sentence selection methods usually bring performance decrease in most cases.
作者认为本文与以往工作的不同之处在于:
(1)对整个三元组中两两之间的关联进行建模,而不仅仅是文章-问题这种二元句对。
(2)本文直接使用预训练模型中得到的词嵌入作为输入和计算相关度的因子,而不需要人工标签。
(3)本文通过PSS取得了广泛的正面作用,而之前的工作中PSS通常会导致性能下降。
Our answer option interaction module is different from previous works in that:
(i) we encode the comparison information by modeling the bilinear representation
among the options at sentence-level which is similar to modeling passage-question sequence relationship, other than attention mechanism.
(ii) We use gated mechanism to fuse the comparison information into the original answer option representations.
本文采用双线性表示而不是注意力机制来编码选项之间的对比信息,并使用门机制来将对比信息融合到原始表示中,作者认为这是本文超越以往使用AOI思想的工作的关键之一。