
多维度分片需求,如何解决查询问题?
点击上方蓝字“设为星标”
大家好,我是【架构摆渡人】,一只十年的程序猿。这是分库分表系列的第一篇文章,这个系列会给大家分享很多在实际工作中有用的经验,如果有收获,还请分享给更多的朋友。
其实这个系列有录过视频给大家学习,但很多读者反馈说看视频太慢了。也不好沉淀为文档资料,希望能有一系列文字版本的讲解,要用的时候可以快速浏览关键的知识点。那么它就来了,我再花点时间写成几篇连续的文章供大家学习。

需求背景
单库单表的时候,我们在实现业务需求的时候,是不会考虑说哪些字段不能用于查询,只要表中有的字段就可以用它来做条件查询。
当分库分表后,就必须要要考虑查询条件中得有哪些字段。必须要有的肯定是分片的字段,比如你根据用户ID进行分片,然后查询的时候却没有用户ID,这样就没办法知道这条SQL到底要去哪个库哪个表查询,只能查询所有的库表进行结果的聚合逻辑,性能非常差。
比如我们以订单来说明,常用的查询场景有根据订单号查询,根据买家查询订单,根据卖家查询订单。
比如我们以用户来说明,常用的查询场景有根据用户ID查询,根据用户名查询,根据手机号码查询。
但是大家想一个问题,就是你分表都是根据一个字段去分的,比如订单的买家,也就是所有买家的订单都会在某个库的某个表中存储。直接根据买家是可以定位到数据的位置,但是如果直接根据订单号和卖家去查,是无法定位数据的存储位置。用户的查询也是一样的问题,这就是我们今天要讲的内容。
实现方式
映射表方式
目前查询订单有三个场景,分别是买家,订单号,卖家或者店铺。分表字段的选择肯定是优先选择查询量最大的场景进行分片,所以订单最适合的分片字段就是买家。
那现在要根据订单号和卖家去查询订单使用映射表的方式该如何实现呢?
映射表其实就是单独为卖家和订单号建立一个映射关系,当我们通过订单号取查询的时候,先通过映射关系找到订单号对应的买家,然后再通过买家就能找到数据的存储位置了。
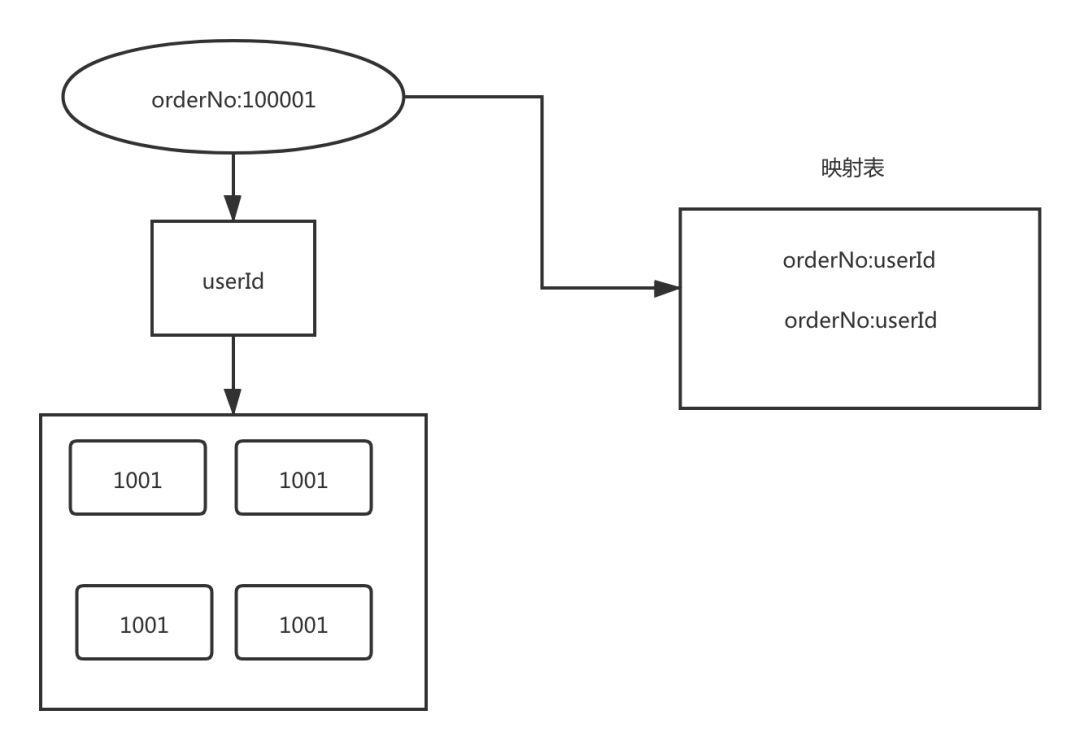
映射可以用普通的表进行存储,也可以用KV的Nosql存储。
二级索引
索引的方式其实跟映射差不多,不同的点在于映射是一一对应的,而索引方式是一对多的场景。
也就是说我们将买家,卖家,订单号都存储起来,这个存储可以用ES,因为ES天生就支持水平扩展,能否存储大数据量。
要注意的是这里只是存储要搜索的条件,所以是没办法替代数据库的分库分表。
那么怎么去构建这个索引呢?可以采用代码的方式,直接在数据创建的时候往索引里面写一份,也可以基于binlog的方式,去构建,这样耦合度更低,数据存储稍微有点延迟。
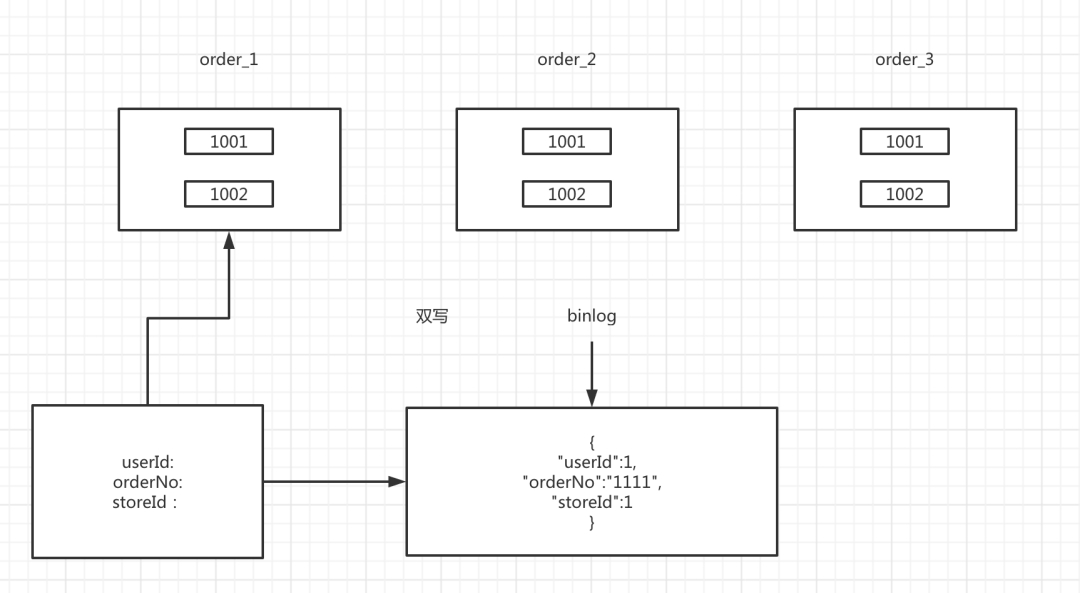
有了这个索引之后,比如根据订单号去查询的时候,就直接先查索引,得到买家,再去查询原始数据。卖家的查询也是一样的逻辑。
融合方式
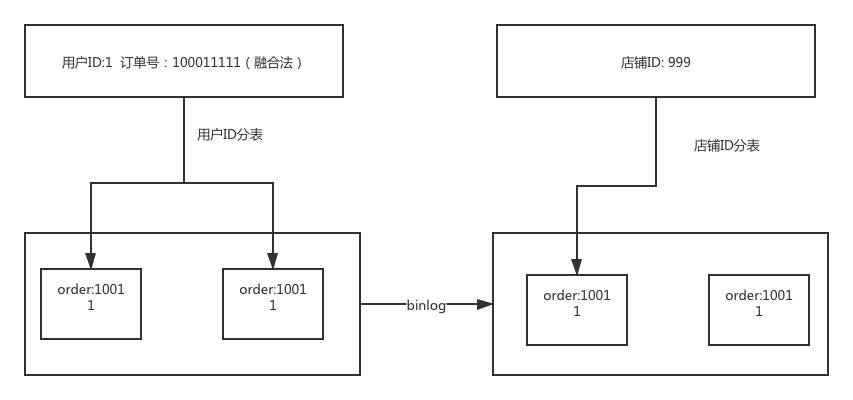
比如根据订单号去查询,无论是通过映射还是索引的方式,都需要一次查询操作。如果我们能直接通过订单号就知道这个订单号是哪个买家的,这样就不用多出一次查询操作了呀。
所以我们可以在订单号里面融入买家的信息,一般订单号都比较长,大家可以去看看自己淘宝的订单号,是不是能发现什么规律,比如前几位是固定的,或者后几位是固定的,讲到这里大家都懂了吧。
把买家融入到订单号里面后,查询的时候就可以直接提取出买家,完美的省掉了一次多余的查询操作。
空间换时间
总结
这篇文章主要给大家介绍了在分库分表过程中,如何去满足我们业务需求的多维度查询问题。实现方案有很多,大家要根据场景选择合适的方式。
原创:架构摆渡人(公众号ID:jiagoubaiduren),欢迎分享,转载请保留出处。