
Yolo发展史(v4/v5的创新点汇总!)
大家好,接上面一篇文章:网易面试原题|简述Yolo系列网络的发展史
原问题是系列网络的发展。这篇文章,我们主要看下与的创新点。
看文章之前,别忘了关注我哈~ 向你呀!
YOLOv4
YOLOv4的三大贡献:
设计了强大而高效的检测模型,任何人都可以用 1080Ti 和 2080Ti训练这个超快而精准的模型。 验证了很多近几年 SOTA 的深度学习目标检测训练技巧。 修改了很多 SOTA 的方法, 让它们对单GPU训练更加高效,例如 CmBN,PAN,SAM等。
作者总结了近几年的单阶段和双阶段的目标检测算法以及技巧,并用一个图概括了单阶段和双阶段目标检测网络的差别,two-stage的检测网络,相当于在one-stage的密集检测上增加了一个稀疏的预测器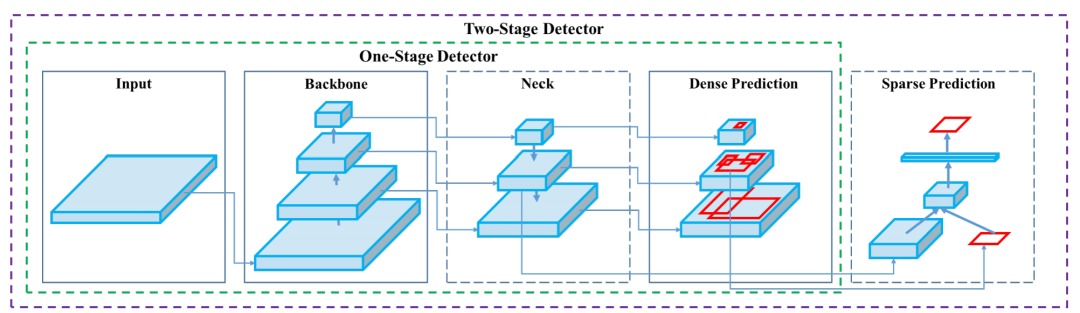
作者也对多种方法进行实验,做了详尽的测试,作者将那些增加模型性能,只在训练阶段耗时增多,但不影响推理耗时的技巧称为 —— bag of freebies;而那些微微提高了推理耗时,却显著提升性能的,叫做 —— bag of specials。
bag of freebies
数据增强
光度变换 调整亮度,对比度,色相,饱和度和噪点 几何变换 随机缩放,裁剪,翻转和旋转 模拟目标遮挡 random erase CutOut Hide and Seek grid Mask 图像融合 MixUp CutMix Mosaic
常见的正则化方法:
DropOut DropConnect DropBlock
处理数据不平衡
two-stage网络使用的难例挖掘,但是这种方式不适合one-stage检测 Focal Loss
标签平滑(Label Smoothing)
边界框回归的损失函数
IOU Loss GIOU Loss DIOU Loss CIOU Loss
Bag of specials
增强感受野
SPP ASPP RFB
注意力模块
通道注意力(channel-wise) SE 空间注意力(point-wise) SAM
特征融合
跳层连接 FPN SFAM ASFF BiFPN(EfficientNet中提出)
激活函数
LReLU(解决当输入小于0时ReLU梯度为0的情况) PReLU(解决当输入小于0时ReLU梯度为0的情况) ReLU6(专门为量化网络设计) hard-swish(专门为量化网络设计) SELU(对神经网络进行自归一化) Swish(连续可微激活函数) Mish(连续可微激活函数)
后处理方式
NMS soft NMS DIOU NMS(在soft NMS的基础上将重心距离的信息添加到删选BBOx的过程中)
YOLOv4网络结构
图片引自:江大白
YOLOv4整个网络架构组成
Backbone: CSPDarknet53 Neck: SPP, PAN Head: YOLOv3
YOLOv4 各部分使用到的Bags:
Bag of Freebies (BoF) for backbone:
CutMix、Mosaic data augmentation DropBlock regularization Class label smoothing
Bag of Specials (BoS) for backbone:
Mish activation Cross-stage partial connections (CSP) Multiinput weighted residual connections (MiWRC)
Bag of Freebies (BoF) for detector:
CIoU-loss CmBN DropBlock regularization Mosaic data augmentation Self-Adversarial Training Eliminate grid sensitivity Using multiple anchors for a single ground truth Cosine annealing scheduler Optimal hyperparameters Random training shapes
Bag of Specials (BoS) for detector:
Mish activation SPP-block SAM-block PAN path-aggregation block DIoU-NMS
BackBone
CSPDarknet53是在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。作者在实验中得到结论,CSPResNeX50分类精度比CSPDarknet,但是检测性能却不如后者。
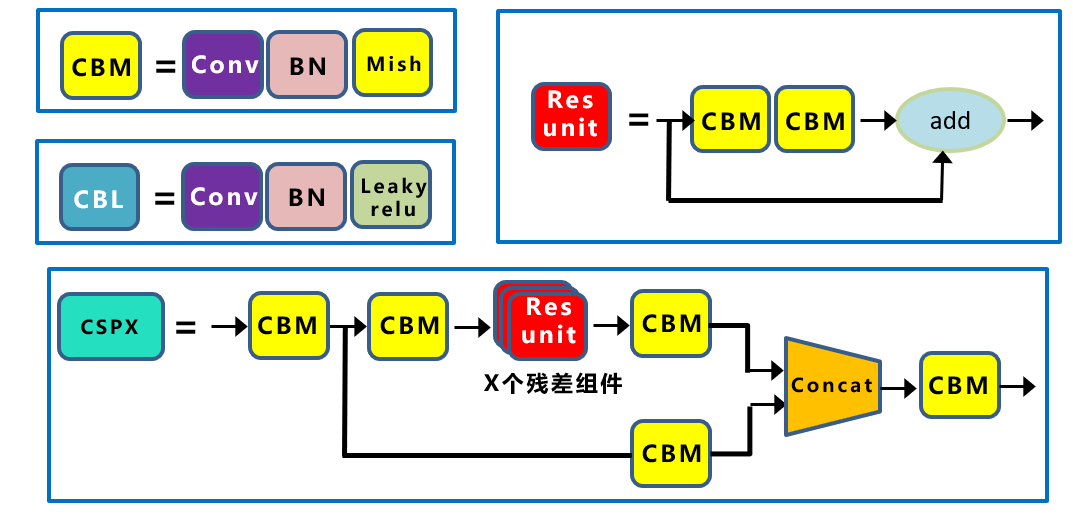
每个CSP模块第一个卷积核的大小都是 ,stride=2,因此可以起到下采样的作用。因为Backbone有5个CSP模块,输入图像是,所以特征图变化的规律是:。
YOLOv4 和 YOLOv5 都使用 CSPDarknet作为BackBone,从输入图像中提取丰富的特征信息。CSPNet叫做Cross Stage Partial Network,跨阶段局部网络。其解决了其他大型卷积网络结构中的重复梯度问题,减少模型参数和FLOPS。这对 YOLO 有重要的意义,即保证了推理速度和准确率,又减小了模型尺寸。
CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet基于Densnet的思想,复制基础层的特征映射图,通过dense block 传递到下一个阶段进行合并,从而将基础层的特征映射图分离出来。这样可以实现更丰富的梯度组合,同时减少计算量。
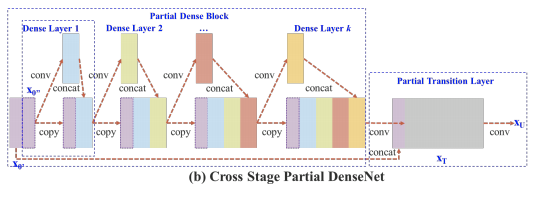
因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点:
优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。 优点二:降低计算瓶颈 优点三:降低内存成本
详细了解CSPNet,https://zhuanlan.zhihu.com/p/124838243
而且作者只在Backbone中采用了Mish激活函数,网络后面仍然采用Leaky_relu激活函数。Yolov4作者实验测试时,使用CSPDarknet53网络在ImageNet数据集上做图像分类任务,发现使用了Mish激活函数的TOP-1和TOP-5的精度比没有使用时精度要高一些。因此在设计Yolov4目标检测任务时,主干网络Backbone还是使用Mish激活函数。
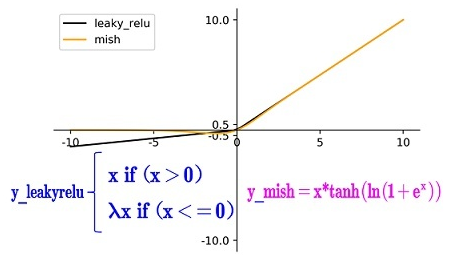
数据增强

Mosaic是一种新的混合4幅训练图像的数据增强方法,使四个不同的上下文信息被混合,丰富了图像的上下文信息,这使得网络能够检测正常图像之外的对象,增强模型的鲁棒性。此外,批处理规范化BN层从每一层上的4个不同图像计算激活统计信息。这大大减少了对large mini-batch-size的需求。Mosaic,就是把四张图片拼接为一张图片,这等于变相的增大了一次训练的图片数量,可以让最小批数量进一步降低,让在单GPU上训练更为轻松。

在YOLOv4中,通过引入CutMix和Mosaic数据增强、类标签平滑和Mish激活等功能,分类精度得到了提高。因此,本文用于分类训练的BoF骨干(免费包)包括以下内容:CutMix和Mosaic数据增强和类标签平滑。此外,本文使用Mish激活作为补充选项,
DropBlock
Yolov4中使用的Dropblock,其实和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式。传统的Dropout很简单,一句话就可以说的清:随机删除减少神经元的数量,使网络变得更简单。 而Dropblock和Dropout相似,比如下图:
而Dropblock和Dropout相似,比如下图: 上图中,中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
上图中,中间Dropout的方式会随机的删减丢弃一些信息,但Dropblock的研究者认为,卷积层对于这种随机丢弃并不敏感,因为卷积层通常是三层连用:卷积+激活+池化层,池化层本身就是对相邻单元起作用。而且即使随机丢弃,卷积层仍然可以从相邻的激活单元学习到相同的信息。因此,在全连接层上效果很好的Dropout在卷积层上效果并不好。所以右图Dropblock的研究者则干脆整个局部区域进行删减丢弃。
这种方式其实是借鉴2017年的cutout数据增强的方式,cutout是将输入图像的部分区域清零,而Dropblock则是将Cutout应用到每一个特征图。而且并不是用固定的归零比率,而是在训练时以一个小的比率开始,随着训练过程线性的增加这个比率。
Dropblock的研究者与Cutout进行对比验证时,发现有几个特点:
Dropblock的效果优于Cutout Cutout只能作用于输入层,而Dropblock则是将Cutout应用到网络中的每一个特征图上 Dropblock可以定制各种组合,在训练的不同阶段可以修改删减的概率,从空间层面和时间层面,和Cutout相比都有更精细的改进。
Yolov4中直接采用了更优的Dropblock,对网络进行正则化。
Neck创新
Yolov4的Neck结构主要采用了SPP模块、FPN+PAN的方式。
SPP

作者在SPP模块中,使用的最大池化的方式,再将不同尺度的特征图进行Concat操作。最大池化采用padding操作,移动的步长为1,比如的输入特征图,使用大小的池化核池化,,因此池化后的特征图仍然是大小。

和Yolov4作者的研究相同,采用SPP模块的方式,比单纯的使用最大池化的方式,更有效的增加BackBone感受野。Yolov4的作者在使用大小的图像进行测试时发现,在COCO目标检测任务中,以0.5%的额外计算代价将AP50增加了2.7%,因此Yolov4中也采用了SPP模块。
FPN+PAN
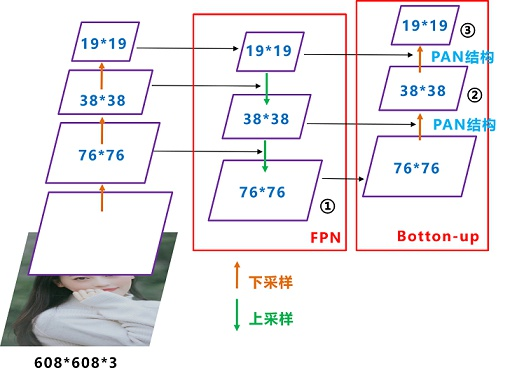
Yolov4在FPN层的后面还添加了一个自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行参数聚合。
FPN+PAN借鉴的是18年CVPR的PANet,当时主要应用于图像分割领域,但Alexey将其拆分应用到Yolov4中,进一步提高特征提取的能力。
原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4中则采用concat(route)操作,特征图融合后的尺寸发生了变化。

Head头
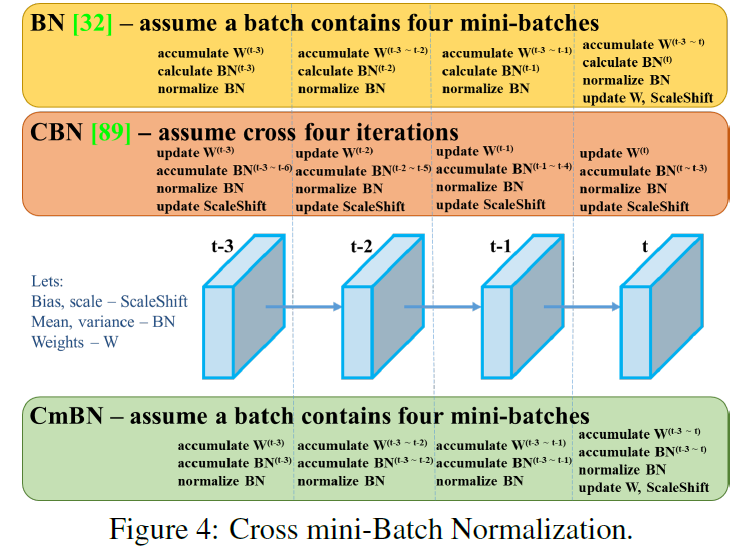
CmBN
CmBN 为 CBN 的改进版本,定义为交叉小批量归一化 (CmBN)。这仅在单个批次内的小批次之间收集统计信息(收集一个batch内多个mini-batch内的统计数据)。
Bounding Box Regeression Loss
目标检测任务的损失函数一般由Classificition Loss(分类损失函数)和Bounding Box Regeression Loss(回归损失函数)两部分构成。
Bounding Box Regeression的Loss近些年的发展过程是:
Smooth L1 Loss-> IoU Loss(2016)-> GIoU Loss(2019)-> DIoU Loss(2020)->CIoU Loss(2020)
我们从最常用的IOU_Loss开始,进行对比拆解分析,看下Yolov4为啥要选择CIOU_Loss。
IOU LOSS
IOU Loss主要考虑检测框和目标框的重叠面积,公式如下:
IOU Loss存在两个问题:
问题一:当预测框和目标框不相交时,也就是当IOU=0时,无法反映两个框距离的远近,此时损失函数不可导。所以IOU Loss无法优化两个框不相交的情况 问题二:当两个预测框和同一个目标框相重叠,且两者IOU相同,这时IOU Loss对两个预测框的惩罚相同,无法区分两个预测框与GT目标框的相交情况
GIOU Loss
由于IOU Loss的不足,2019年提出了GIOU Loss,我们先定义一下符号: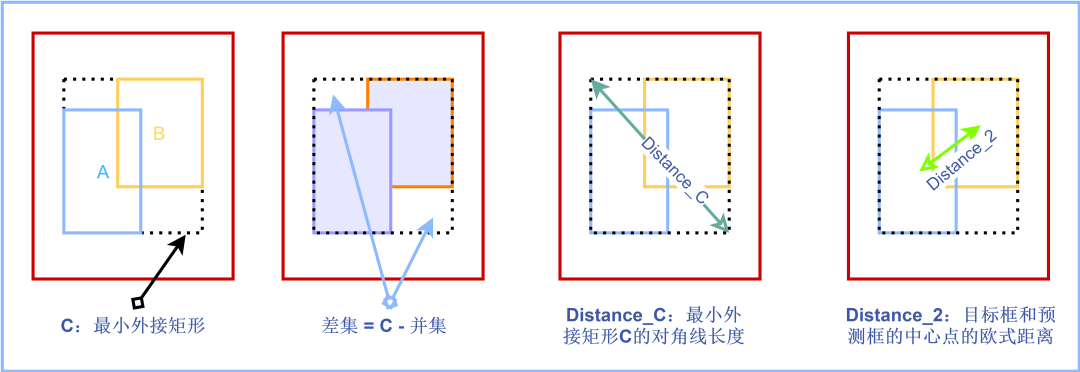
定义为预测框,为目标框,为目标框和预测框的最小外接矩形,公式如下:
可以看到,相比于IOU Loss,GIOU Loss衡量了目标框和预测框的相交程度,缓解了IOU Loss的问题。
但是当预测框在目标框内部,且预测框大小一致时,这时候预测框和目标框的差集相等,这是GIOU Loss会退化成IOU Loss,无法区分各个预测框的位置关系。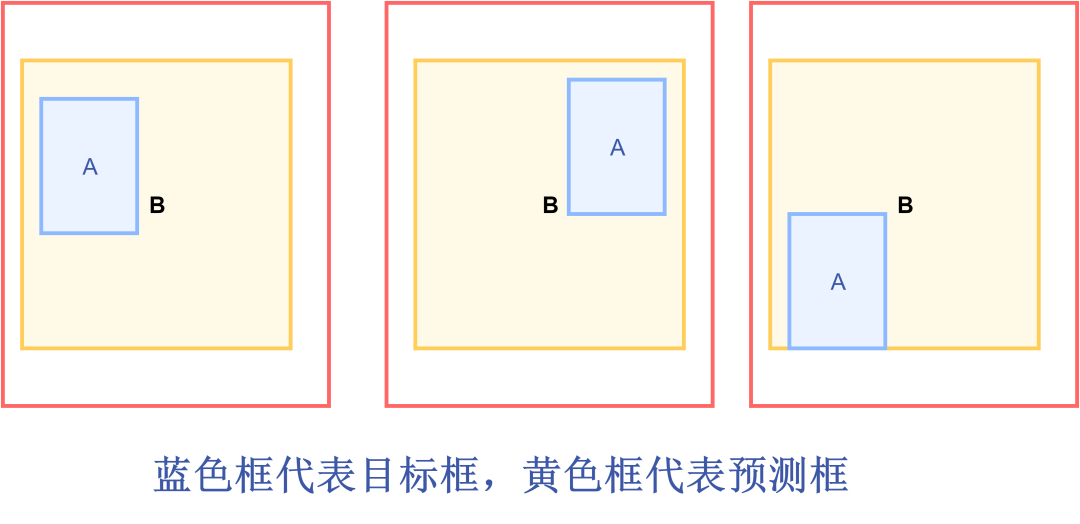
DIOU Loss 和 CIOU Loss
好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比。
针对IOU Loss和GIOU Loss存在的问题,DIOU Loss考虑重叠面积、中心点距离,公式如下:
设:为预测框和目标框的最小外接矩形,表示最小外接矩形的对角线距离,表示预测框的中心点到目标框中心点的欧式距离
由上述公式可以看出,当遇到GIOU Loss 无法解决的问题时,DIOU即考虑了重叠面积,也考虑了目标框和预测框的中心点的距离,就可以衡量两者之间的位置关系。所以当目标框包裹预测框的时候,DIOU可以衡量两者之间的距离。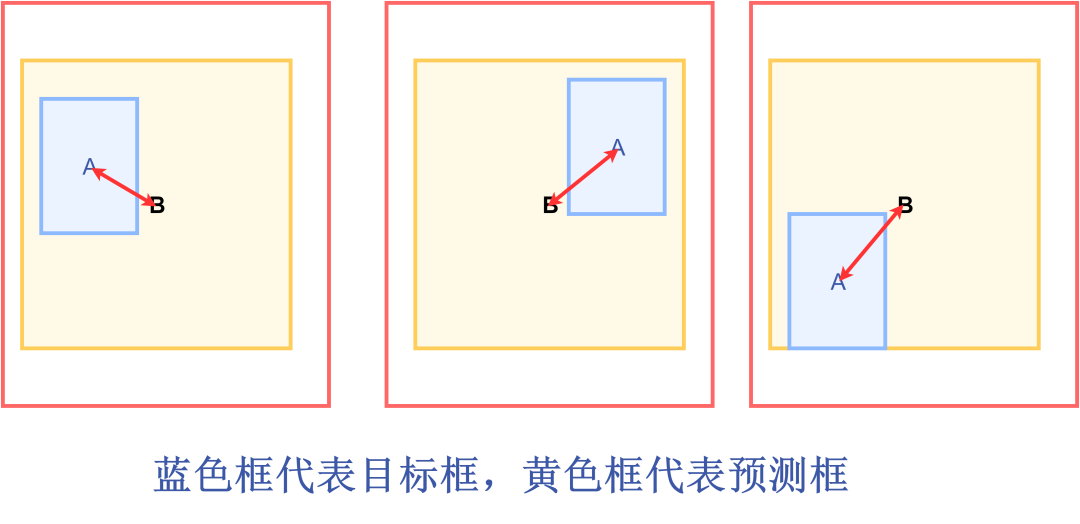
但是DIOU Loss没有考虑长宽比,当预测框在目标框内部时,且多个预测框的中心点的位置都一样时,这时候DIOU Loss无法区分这几个预测框的位置。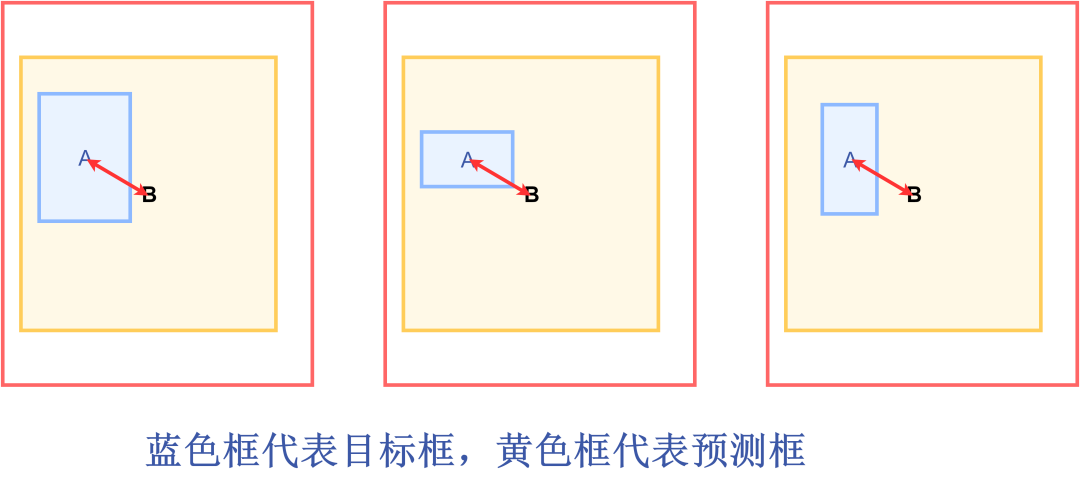 所以提出了CIOU Loss,其在DIOU Loss的基础上增加了一个影响因子,将预测框和目标框的长宽比都考虑进去,公式如下:
所以提出了CIOU Loss,其在DIOU Loss的基础上增加了一个影响因子,将预测框和目标框的长宽比都考虑进去,公式如下:
其中,是一个衡量长宽比一致性的参数,我们可以定义为:
代表目标框,代表预测框。
至此,CIOU Loss包含了一个好的预测框回归函数的三个重要的几何因素:重叠面积、中心点距离、长宽比。
NMS
NMS主要用于预选框的筛选,常用于目标检测算法中,一般采用普通的nms的方式,Yolov4则借鉴上面D/CIOU loss的论文:https://arxiv.org/pdf/1911.08287.pdf

因为DIOU在计算loss的时候,需要考虑边界框中心点的位置信息,所以一些重叠物体也可以回归出来。因此在重叠目标的检测中,DIOU_nms的效果优于传统的nms。
CIOU Loss的性能要比DIOU Loss好,那为什么不用CIOU_nms,而用DIOU_nms?
因为CIOU_loss,是在DIOU_loss的基础上,添加了一个的影响因子,包含groundtruth标注框的信息,在训练时用于回归。但是NMS在推理过程中,并不需要groundtruth的信息,所以CIOU NMS不可使用。
CIOU Loss 代码
def box_ciou(b1, b2):
"""
输入为:
----------
b1: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
b2: tensor, shape=(batch, feat_w, feat_h, anchor_num, 4), xywh
返回为:
-------
ciou: tensor, shape=(batch, feat_w, feat_h, anchor_num, 1)
"""
# 求出预测框左上角右下角
b1_xy = b1[..., :2]
b1_wh = b1[..., 2:4]
b1_wh_half = b1_wh/2.
b1_mins = b1_xy - b1_wh_half
b1_maxes = b1_xy + b1_wh_half
# 求出真实框左上角右下角
b2_xy = b2[..., :2]
b2_wh = b2[..., 2:4]
b2_wh_half = b2_wh/2.
b2_mins = b2_xy - b2_wh_half
b2_maxes = b2_xy + b2_wh_half
# 求真实框和预测框所有的iou
intersect_mins = torch.max(b1_mins, b2_mins)
intersect_maxes = torch.min(b1_maxes, b2_maxes)
intersect_wh = torch.max(intersect_maxes - intersect_mins, torch.zeros_like(intersect_maxes))
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
b1_area = b1_wh[..., 0] * b1_wh[..., 1]
b2_area = b2_wh[..., 0] * b2_wh[..., 1]
union_area = b1_area + b2_area - intersect_area
iou = intersect_area / torch.clamp(union_area,min = 1e-6)
# 计算中心的差距
center_distance = torch.sum(torch.pow((b1_xy - b2_xy), 2), axis=-1)
# 找到包裹两个框的最小框的左上角和右下角
enclose_mins = torch.min(b1_mins, b2_mins)
enclose_maxes = torch.max(b1_maxes, b2_maxes)
enclose_wh = torch.max(enclose_maxes - enclose_mins, torch.zeros_like(intersect_maxes))
# 计算对角线距离
enclose_diagonal = torch.sum(torch.pow(enclose_wh,2), axis=-1)
ciou = iou - 1.0 * (center_distance) / torch.clamp(enclose_diagonal,min = 1e-6)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(b1_wh[..., 0]/torch.clamp(b1_wh[..., 1],min = 1e-6)) - torch.atan(b2_wh[..., 0]/torch.clamp(b2_wh[..., 1],min = 1e-6))), 2)
alpha = v / torch.clamp((1.0 - iou + v),min=1e-6)
ciou = ciou - alpha * v
return ciou
def clip_by_tensor(t,t_min,t_max):
t=t.float()
result = (t >= t_min).float() * t + (t < t_min).float() * t_min
result = (result <= t_max).float() * result + (result > t_max).float() * t_max
return result
YOLOv5
yolov5没有发布论文,所以更加精细的内容,只能研究其代码,该代码仓库仍然保持高频率更新:https://github.com/ultralytics/yolov5
YOLOv5 🚀 是一系列在 COCO 数据集上预训练的对象检测架构和模型,代表 Ultralytics 对未来视觉 AI 方法的开源研究,结合了在数千小时的研究和开发中获得的经验教训和最佳实践。
网络模型结构
YOLOv5给出了四种版本的目标检测网络,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。YOLOv5s是深度最浅,特征图的宽度最窄的网络,后面三种在此基础上不断加深,加宽。YOLOv5s的网络结构图如下所示:
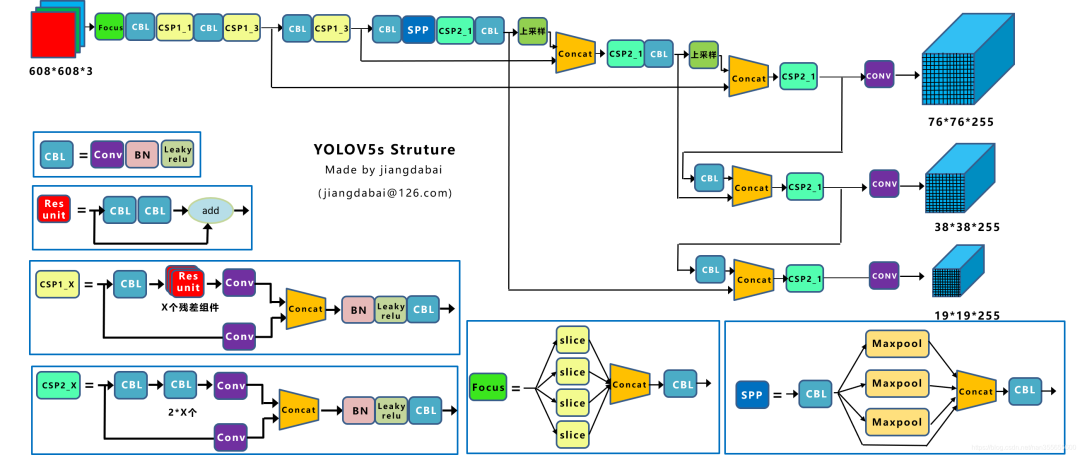
YOLOv5各部分改进
输入端:Mosaic数据增强、自适应锚框计算 Backbone:Focus结构,CSP结构 Neck:FPN+PAN结构 Prediction:GIOU_Loss
Mosaic数据增强
YOLOV5会进行三种数据增强:缩放,色彩空间调整和马赛克增强。其中马赛克增强是通过将四张图像进行随机缩放、随机裁剪、随机分布方式进行拼接,小目标的检测效果得到提升。

自适应锚框计算
YOLO系列中,可以针对数据集设置初始的Anchor。在网络训练中,网络在Anchor的基础上输出预测框,进而和GT框进行比较,计算loss,在反向更新,迭代网络参数。在YOLOv3、4版本中,设置初始Anchor的大小都是通过单独的程序使用K-means算法得到,但是在YOLOv5中,将此功能嵌入到代码中,每次训练数据集之前,都会自动计算该数据集最合适的Anchor尺寸,该功能可以在代码中设置超参数进行关闭。
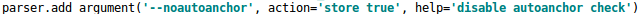 train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
train.py中上面一行代码,设置成False,每次训练时,不会自动计算。
CSP BackBone-跨阶段局部网络
YOLOv4 和 YOLOv5 都使用 CSPDarknet作为BackBone,从输入图像中提取丰富的特征信息。CSPNet叫做Cross Stage Partial Network,跨阶段局部网络。其解决了其他大型卷积网络结构中的重复梯度问题,减少模型参数和FLOPS。这对 YOLO 有重要的意义,即保证了推理速度和准确率,又减小了模型尺寸。
YOLOv4只有主干网络中使用了CSP结构,而YOLOv5中设计了两种CSP结构,CSP1_X应用于BackBone主干网络,另一种CSP_2X结构则应用于Neck中。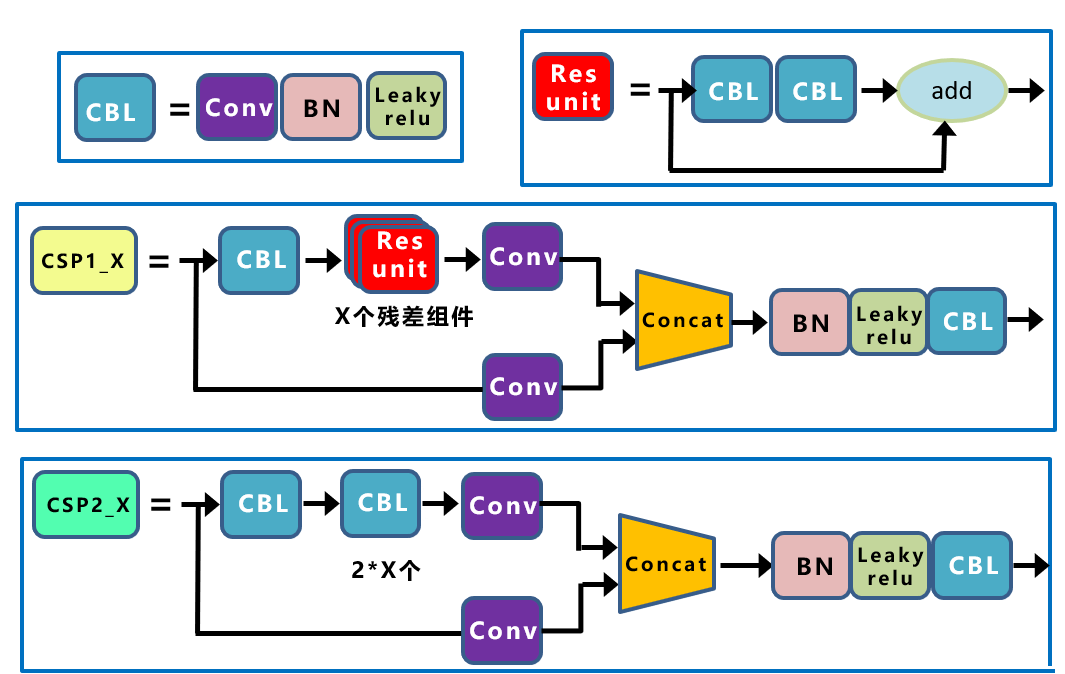
Focus结构
Focus结构,在Yolov3&Yolov4中并没有这个结构,其中比较关键是切片操作。
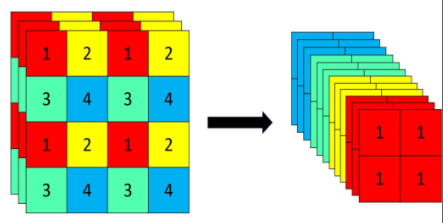
比如上图的切片示意图,的图像切片后变成的特征图。

以Yolov5s的结构为例,原始的图像输入Focus结构,采用切片操作,先变成的特征图,再经过一次32个卷积核的卷积操作,最终变成的特征图。
需要注意的是:Yolov5s的Focus结构最后使用了32个卷积核,而其他三种结构,使用的卷积核数量有所增加。
作者原话:Focus() module is designed for FLOPS reduction and speed increase, not mAP increase.
作用:减少FLOPs,提高速度,对于模型的精度mAP没有提升。
Neck
Yolov5现在的Neck和Yolov4中一样,都采用FPN+PAN的结构,但在Yolov5刚出来时,只使用了FPN结构,后面才增加了PAN结构,此外网络中其他部分也进行了调整。

但如上面CSPNet结构中讲到,Yolov5和Yolov4的不同点在于,
Yolov4的Neck结构中,采用的都是普通的卷积操作。而Yolov5的Neck结构中,采用借鉴CSPnet设计的CSP2_X结构,加强网络特征融合的能力。

Bounding Box的损失函数
Yolov5中采用其中的GIOU_Loss做Bounding box的损失函数。而Yolov4中采用CIOU_Loss作为目标Bounding box的损失。
nms非极大值抑制
在目标检测的后处理过程中,针对很多目标框的筛选,通常需要nms操作。
因为CIOU_Loss中包含影响因子v,涉及groudtruth的信息,而测试推理时,是没有groundtruth的。
所以Yolov4在DIOU_Loss的基础上采用DIOU_nms的方式,而Yolov5中采用加权nms的方式。
采用DIOU_nms,对于遮挡问题,检出效果有所提升。
在回归框的损失函数和使用NMS删除冗余预选框上,YOLOv4使用的方法要比v5的方法更有优势。
参考链接
https://www.yuque.com/darrenzhang/cv/tg215h http://arxiv.org/abs/2004.10934 https://blog.csdn.net/nan355655600/article/details/106246625 https://zhuanlan.zhihu.com/p/172121380 https://www.zhihu.com/question/399884529
百面计算机视觉汇总
点击文末阅读原文,跳转到《百面第三版》Github地址,欢迎STAR!
往期干货文章

面试必问!| 1. ResNet手推及其相关变形~

一文深入浅出cv中的Attention机制
没文章,没背景,想做CV?那就按这个干!
我丢!算法岗必问!建议收藏!

面试真题:Backbone不变,显存有限,如何增大训练时的batchsize?