点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

选自towardsdatascience
树模型和神经网络,像一枚硬币的两面。在某些情况下,树模型的性能甚至优于神经网络。
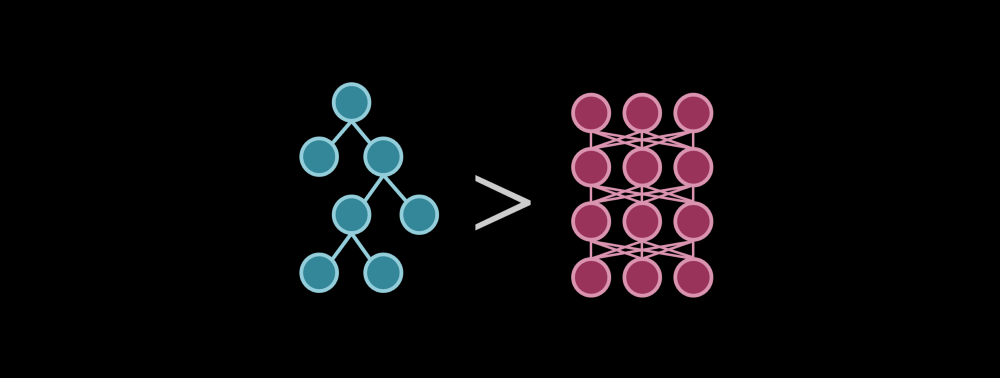
由于神经网络的复杂性,它们常常被认为是解决所有机器学习问题的「圣杯」。而另一方面,基于树的方法并未得到同等重视,主要原因在于这类算法看起来很简单。然而,这两种算法看似不同,却像一枚硬币的正反面,都很重要。基于树的方法通常优于神经网络。本质上,将基于树的方法和基于神经网络的方法放在同一个类别中是因为,它们都通过逐步解构来处理问题,而不是像支持向量机或 Logistic 回归那样通过复杂边界来分割整个数据集。很明显,基于树的方法沿着不同的特征逐步分割特征空间,以优化信息增益。不那么明显的是,神经网络也以类似的方式处理任务。每个神经元监视特征空间的一个特定部分(存在多种重叠)。当输入进入该空间时,某些神经元就会被激活。神经网络以概率的视角看待这种逐段模型拟合 (piece-by-piece model fitting),而基于树的方法则采用确定性的视角。不管怎样,这两者的性能都依赖于模型的深度,因为它们的组件与特征空间的各个部分存在关联。包含太多组件的模型(对于树模型而言是节点,对于神经网络则是神经元)会过拟合,而组件太少的模型根本无法给出有意义的预测。(二者最开始都是记忆数据点,而不是学习泛化。)要想更直观地了解神经网络是如何分割特征空间的,可阅读这篇介绍通用近似定理的文章:https://medium.com/analytics-vidhya/you-dont-understand-neural-networks-until-you-understand-the-universal-approximation-theory-85b3e7677126。虽然决策树有许多强大的变体,如随机森林、梯度提升、AdaBoost 和深度森林,但一般来说,基于树的方法本质上是神经网络的简化版本。基于树的方法通过垂直线和水平线逐段解决问题,以最小化熵(优化器和损失)。神经网络通过激活函数来逐段解决问题。
基于树的方法是确定性的,而不是概率性的。这带来了一些不错的简化,如自动特征选择。
决策树中被激活的条件节点类似于神经网络中被激活的神经元(信息流)。
神经网络通过拟合参数对输入进行变换,间接指导后续神经元的激活。决策树则显式地拟合参数来指导信息流。(这是确定性与概率性相对应的结果。)
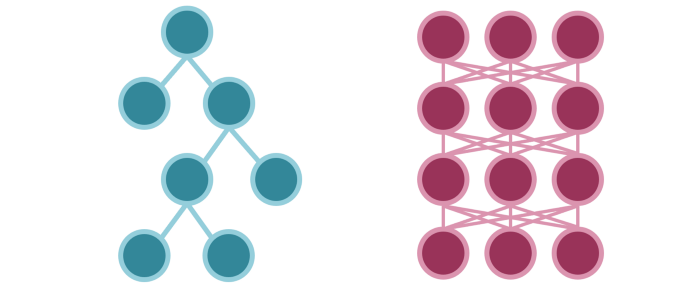
信息在两个模型中的流动相似,只是在树模型中的流动方式更简单。
树模型的 1 和 0 选择 VS 神经网络的概率选择当然,这是一个抽象的结论,甚至可能是有争议的。诚然,建立这种联系有许多障碍。不管怎样,这是理解基于树的方法何时以及为什么优于神经网络的重要部分。对于决策树而言,处理表格或表格形式的结构化数据是很自然的。大多数人都同意用神经网络执行表格数据的回归和预测属于大材小用,所以这里做了一些简化。选择 1 和 0,而不是概率,是这两种算法之间差异的主要根源。因此,基于树的方法可成功应用于不需要概率的情况,如结构化数据。例如,基于树的方法在 MNIST 数据集上表现出很好的性能,因为每个数字都有几个基本特征。不需要计算概率,这个问题也不是很复杂,这就是为什么设计良好的树集成模型性能可以媲美现代卷积神经网络,甚至更好。通常,人们倾向于说「基于树的方法只是记住了规则」,这种说法是对的。神经网络也是一样,只不过它能记住更复杂的、基于概率的规则。神经网络并非显式地对 x>3 这样的条件给出真 / 假的预测,而是将输入放大到一个很高的值,从而得到 sigmoid 值 1 或生成连续表达式。另一方面,由于神经网络非常复杂,因此使用它们可以做很多事情。卷积层和循环层都是神经网络的杰出变体,因为它们处理的数据往往需要概率计算的细微差别。很少有图像可以用 1 和 0 建模。决策树值不能处理具有许多中间值(例如 0.5)的数据集,这就是它在 MNIST 数据集上表现很好的原因,在 MNIST 中,像素值几乎都是黑色或白色,但其他数据集的像素值不是(例如 ImageNet)。类似地,文本有太多的信息和太多的异常,无法用确定性的术语来表达。这也是神经网络主要用于这些领域的原因,也是神经网络研究在早期(21 世纪初之前)停滞不前的原因,当时无法获得大量图像和文本数据。神经网络的其他常见用途仅限于大规模预测,比如 YouTube 视频推荐算法,其规模非常大,必须用到概率。任何公司的数据科学团队可能都会使用基于树的模型,而不是神经网络,除非他们正在建造一个重型应用,比如模糊 Zoom 视频的背景。但在日常业务分类任务上,基于树的方法因其确定性特质,使这些任务变得轻量级,其方法与神经网络相同。在许多实际情况下,确定性建模比概率建模更自然。例如,预测用户是否从某电商网站购买一样商品,这时树模型是很好的选择,因为用户天然地遵循基于规则的决策过程。用户的决策过程可能看起来像这样:我以前在这个平台上有过愉快的购物经历吗?如果有,继续。
我现在需要这件商品吗?(例如,冬天我应该买太阳镜和泳裤吗?)如果是,继续。
根据我的用户统计信息,这是我有兴趣购买的产品吗?如果是,继续。
这个东西太贵吗?如果没有,继续。
其他顾客对这个产品的评价是否足够高,让我可以放心地购买它?如果是,继续。
一般来说,人类遵循基于规则和结构化的决策过程。在这些情况下,概率建模是不必要的。参考链接:https://towardsdatascience.com/when-and-why-tree-based-models-often-outperform-neural-networks-ceba9ecd0fd8
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
