
最后一天,继续卷!
大家好,我是小林。
正文
为什么 TCP 三次握手期间,为什么客户端和服务端的初始化序列号要求不一样的呢?
TCP 四次挥手中的 TIME_WAIT 状态不是会持续 2 MSL 时长,历史报文不是早就在网络中消失了吗?
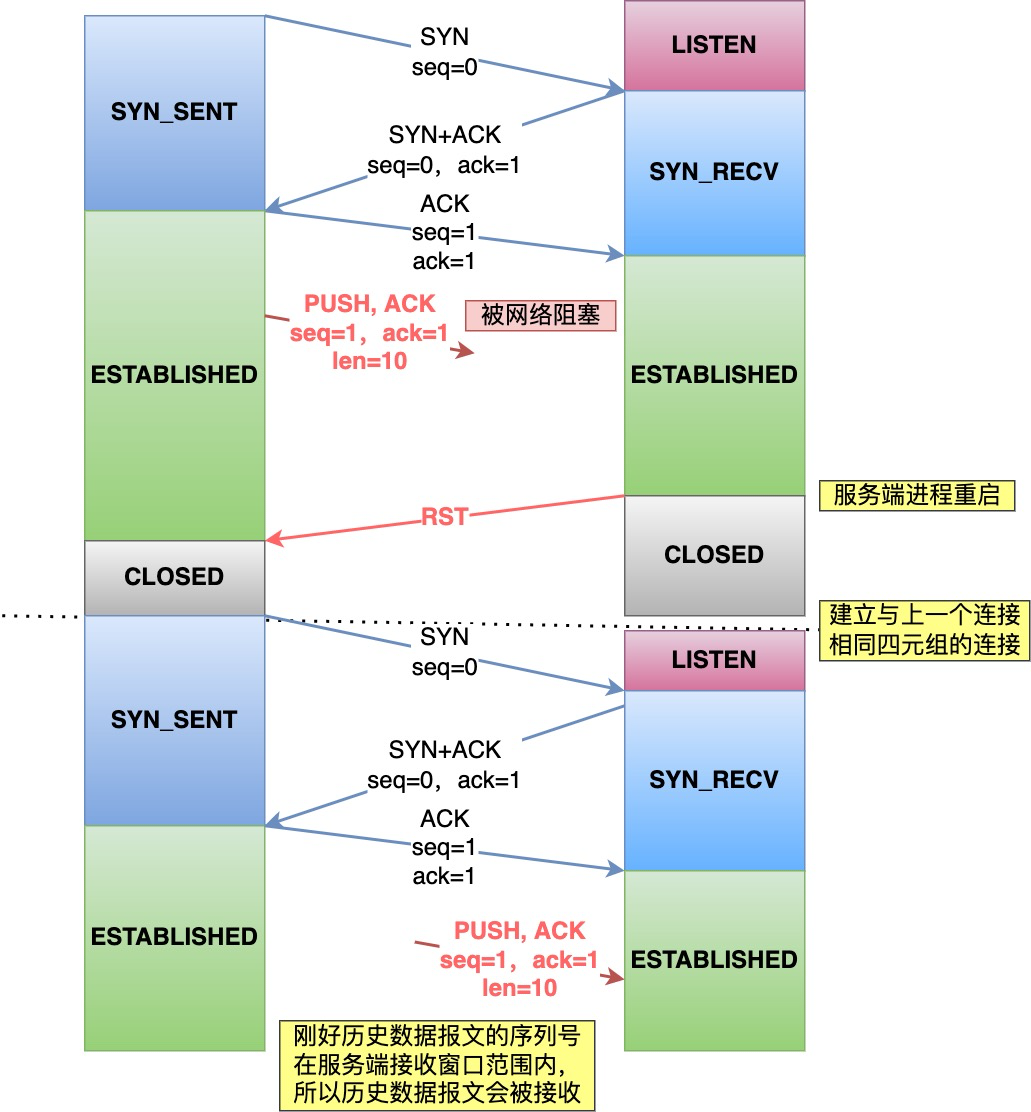
客户端和服务端建立一个 TCP 连接,在客户端发送数据包被网络阻塞了,而此时服务端的进程重启了,于是就会发送 RST 报文来断开连接。
紧接着,客户端又与服务端建立了与上一个连接相同四元组的连接;
在新连接建立完成后,上一个连接中被网络阻塞的数据包正好抵达了服务端,刚好该数据包的序列号正好是在服务端的接收窗口内,所以该数据包会被服务端正常接收,就会造成数据错乱。
客户端和服务端的初始化序列号不一样不是也会发生这样的事情吗?
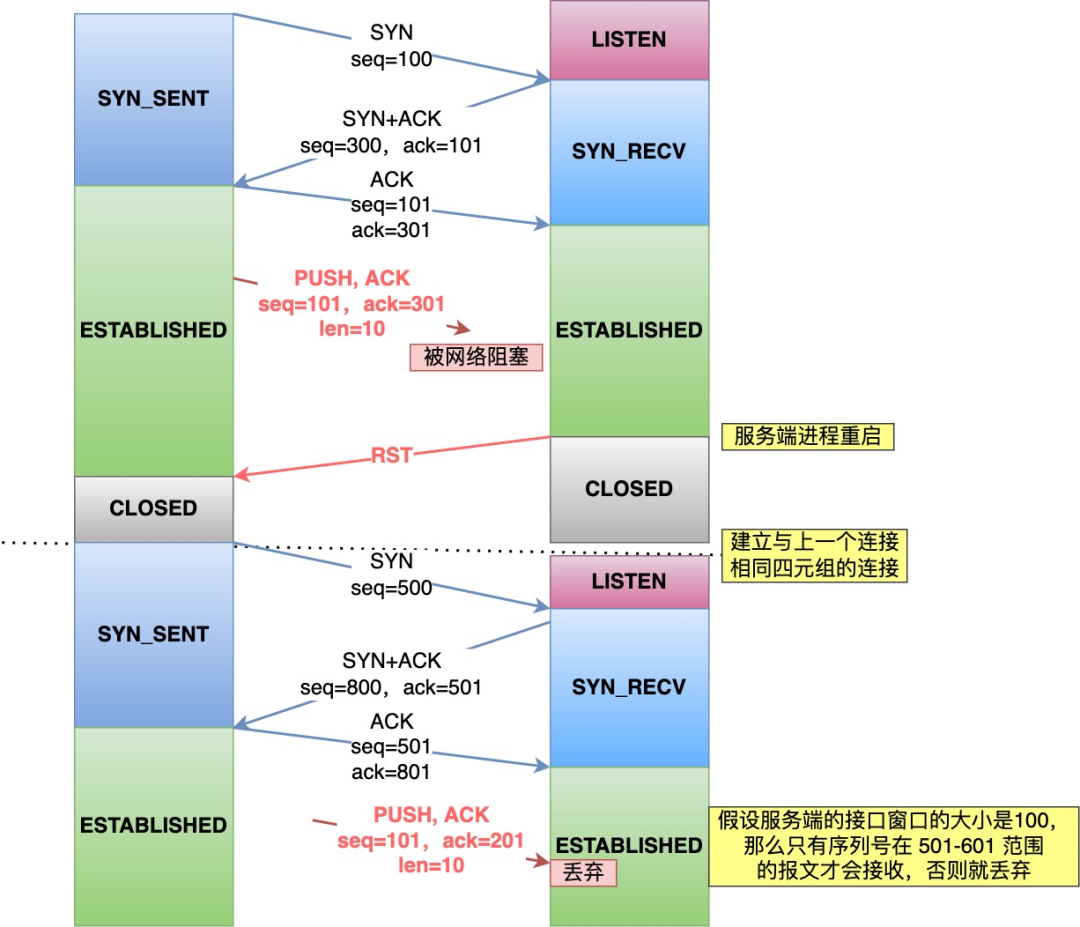
那客户端和服务端的初始化序列号都是随机的,那还是有可能随机成一样的呀?
M是一个计时器,这个计时器每隔4毫秒加1。
F 是一个 Hash 算法,根据源IP、目的IP、源端口、目的端口生成一个随机数值,要保证 hash 算法不能被外部轻易推算得出。
懂了,客户端和服务端初始化序列号都是随机生成的话,就能避免连接接收历史报文了。
序列号,是 TCP 一个头部字段,标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,因为 TCP 是面向字节流的可靠协议,为了保证消息的顺序性和可靠性,TCP 为每个传输方向上的每个字节都赋予了一个编号,以便于传输成功后确认、丢失后重传以及在接收端保证不会乱序。序列号是一个 32 位的无符号数,因此在到达 4G 之后再循环回到 0。
初始序列号,在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。


懂了,客户端和服务端的初始化序列号都是随机生成,能很大程度上避免历史报文被下一个相同四元组的连接接收,然后又引入时间戳的机制,从而完全避免了历史报文被接收的问题。
收到读者的打赏,不管多少钱都是对小林的最好的认可;
收到读者的感谢,帮助他们面试中击破了网络和系统的八股文面试,我把读者们的故事,都收录到了这里:读者牛逼
评论