
实战:OpenVINO+OpenCV 文本检测与识别
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|OpenCV学堂
模型介绍
文本检测模型
OpenVINO支持场景文字检测是基于MobileNet的PixelLink模型,该模型有两个输出,分别是分割输出与bounding Boxes输出,结构如下:
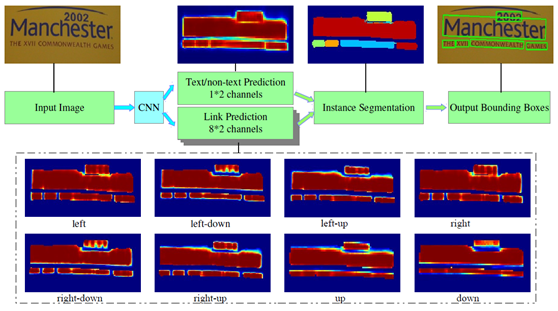
下面是基于VGG16作为backbone实现的PixelLink的模型结构:
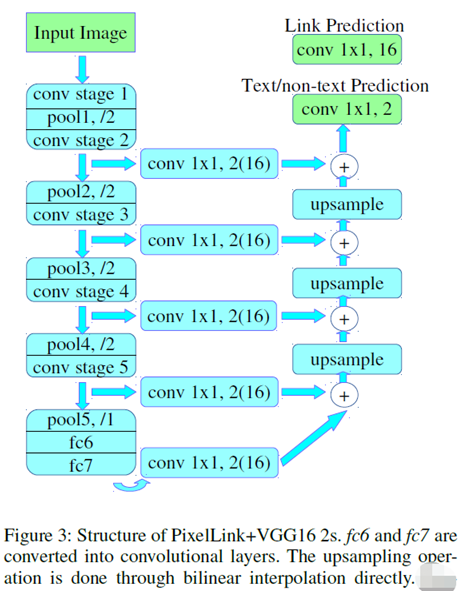
输入格式:1x3x768x1280 BGR彩色图像
输出格式:
name: "model/link_logits_/add", [1x16x192x320] – pixelLink的输出name: "model/segm_logits/add", [1x2x192x320] – 像素分类text/no text
文本识别模型
基于VGG16+双向LSTM,识别0~9与26个字符加空白,并且非大小写敏感!基于CNN+LSTM的文本识别网络结构如下:
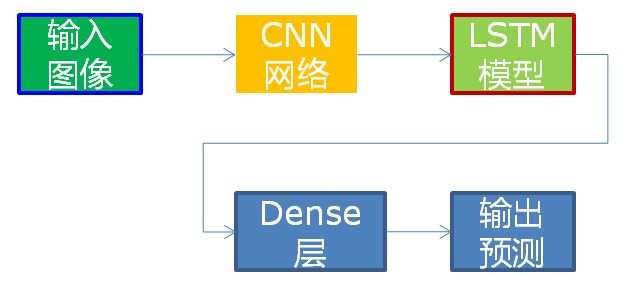
这里CNN使用类似VGG16结构提前特征,序列预测使用双向LSTM网络。
输入格式:1x1x32x120输出格式:30, 1, 37输出解释是基于CTC贪心解析方式。
代码演示
01
文本检测
基于PixelLink完成文本检测,其中加载模型与获取输入与输出层名称的代码实现如下:
1log.info("Creating Inference Engine")
2ie = IECore()
3dete_net = ie.read_network(model=dete_text_xml, weights=dete_text_bin)
4reco_net = ie.read_network(model=reco_text_xml, weights=reco_text_bin)
5
6# 文本检测网络, 输入与输出格式
7log.info("加载文本检测网络,解析输入与输出格式...")
8input_it = iter(dete_net.input_info)
9input_det_blob = next(input_it)
10print(input_det_blob)
11output_it = iter(dete_net.outputs)
12out_det_blob1 = next(output_it)
13out_det_blob2 = next(output_it)
14
15# Read and pre-process input images
16print(dete_net.input_info[input_det_blob].input_data.shape)
17dn, dc, dh, dw = dete_net.input_info[input_det_blob].input_data.shape
18
19# Loading model to the plugin
20det_exec_net = ie.load_network(network=dete_net, device_name="CPU")
21print("out_det_blob1: ", out_det_blob1, "out_det_blob2: ", out_det_blob2)执行推理与解析输出的代码如下:
1image = cv.imread("D:/images/openvino_ocr.jpg")
2# image = cv.imread("D:/facedb/tiaoma/1.png")
3h, w, c = image.shape
4cv.imshow("input", image)
5img_blob = cv.resize(image, (dw, dh))
6img_blob = img_blob.transpose(2, 0, 1)
7# Start sync inference
8log.info("Starting inference in synchronous mode")
9inf_start1 = time.time()
10res = det_exec_net.infer(inputs={input_det_blob: [img_blob]})
11inf_end1 = time.time() - inf_start1
12print("inference time(ms) : %.3f" % (inf_end1 * 1000))
13link_logits_ = res[out_det_blob1][0]
14segm_logits = res[out_det_blob2][0]
15link_logits_ = link_logits_.transpose(1, 2, 0)
16segm_logits = segm_logits.transpose(1, 2, 0)
17pixel_mask = np.zeros((192, 320), dtype=np.uint8)
18print(link_logits_.shape, segm_logits.shape)
19# 192, 320
20for row in range(192):
21 for col in range(320):
22 pv1 = segm_logits[row, col, 0]
23 pv2 = segm_logits[row, col, 1]
24 if pv2 > 1.0:
25 pixel_mask[row, col] = 255
26
27mask = cv.resize(pixel_mask, (w, h))
28cv.imshow("mask", mask)运行结果如下:运行结果:
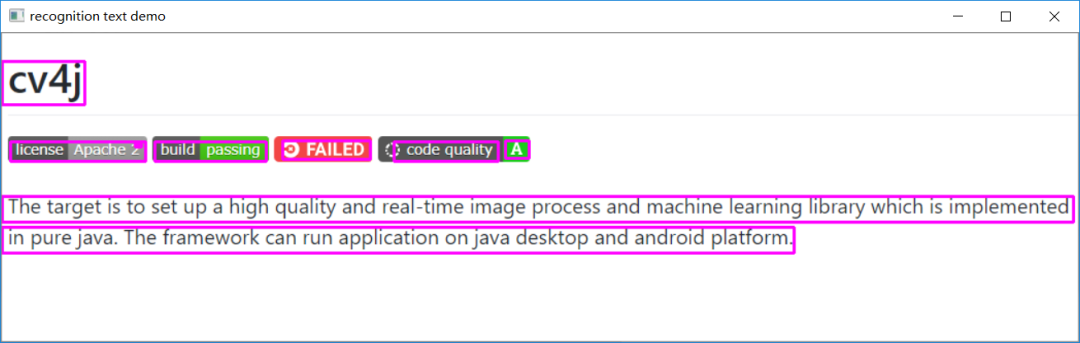
02
文本识别
文本识别跟文本检测的代码流程类似,首先需要加载模型,获取输入与输出层格式与属性,代码实现如下:
1ie = IECore()
2reco_net = ie.read_network(model=reco_text_xml, weights=reco_text_bin)
3
4# 文本识别网络
5log.info("加载文本识别网络,解析输入与输出格式...")
6input_rec_it = iter(reco_net.input_info)
7input_rec_blob = next(input_rec_it)
8print(input_rec_blob)
9output_rec_it = iter(reco_net.outputs)
10out_rec_blob = next(output_rec_it)
11
12# Read and pre-process input images
13print(reco_net.input_info[input_rec_blob].input_data.shape)
14rn, rc, rh, rw = reco_net.input_info[input_rec_blob].input_data.shape
15
16# Loading model to the plugin
17rec_exec_net = ie.load_network(network=reco_net, device_name="CPU")
18print("out_rec_blob1: ", out_rec_blob)
19
20# 文字识别
21image = cv.imread("D:/images/zsxq/ocr3.png")
22gray = cv.cvtColor(image, cv.COLOR_BGR2GRAY)
23ret, binary = cv.threshold(gray, 0, 255, cv.THRESH_BINARY_INV | cv.THRESH_OTSU)
24se = cv.getStructuringElement(cv.MORPH_RECT, (5, 1))
25binary = cv.dilate(binary, se)
26cv.imshow("binary", binary)
27cv.waitKey(0)
28contours, hireachy = cv.findContours(binary, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
29for cnt in range(len(contours)):
30 x, y, iw, ih = cv.boundingRect(contours[cnt])
31 roi = gray[y:y + ih, x:x + iw]
32 rec_roi = cv.resize(roi, (rw, rh))
33 rec_roi_blob = np.expand_dims(rec_roi, 0)
34
35 # Start sync inference
36 log.info("Starting inference in synchronous mode")
37 inf_start1 = time.time()
38 res = rec_exec_net.infer(inputs={input_rec_blob: [rec_roi_blob]})
39 inf_end1 = time.time() - inf_start1
40 print("inference time(ms) : %.3f" % (inf_end1 * 1000))
41 res = res[out_rec_blob]
42 txt = greedy_prase_text(res)
43 cv.putText(image, txt, (x, y), cv.FONT_HERSHEY_PLAIN, 1.0, (0, 0, 255), 1, 8)
44cv.imshow("recognition text demo", image)
45cv.waitKey(0)
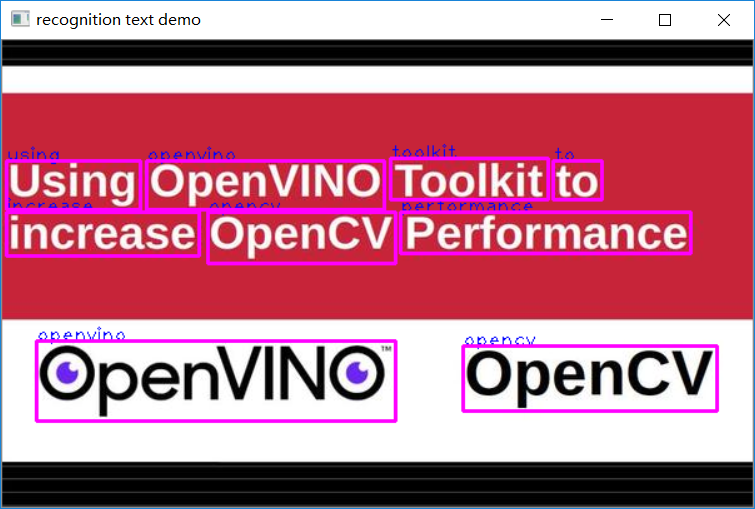
46cv.destroyAllWindows()运行结果如下:
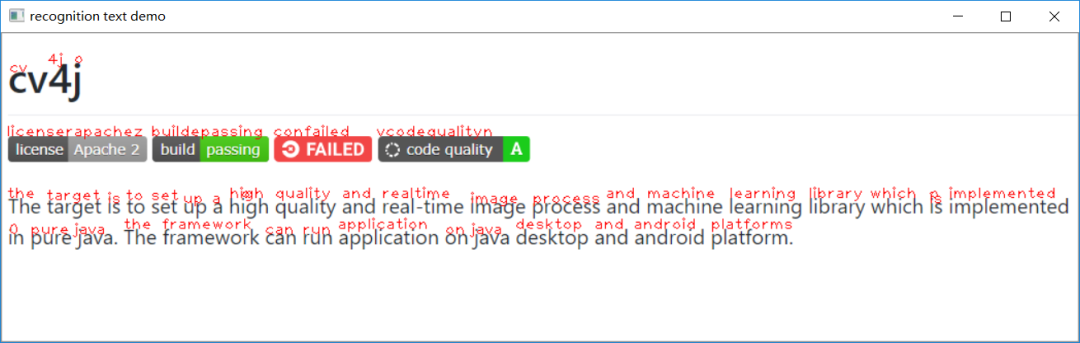
检测+识别一起,运行结果如下:
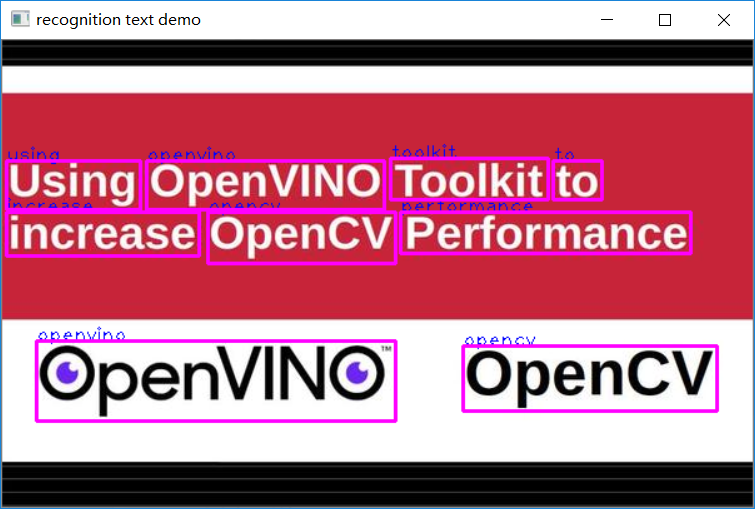
CTC贪心解析
重新整理了一下,CTC贪心解析部分的代码函数。不用看公式,看完你会晕倒而且写不出代码!实现如下:
def ctc_soft_max(data):sum = 0;max_val = max(data)index = np.argmax(data)for i in range(len(data)):sum += np.exp(data[i]- max_val)prob = 1.0 / sumreturn index, probdef greedy_prase_text(res):# CTC greedy decode from hereprint(res.shape)# 解析输出textocrstr = ""prev_pad = False;for i in range(res.shape[0]):ctc = res[i] # 1x13ctc = np.squeeze(ctc, 0)index, prob = ctc_soft_max(ctc)if digit_nums[index] == '#':prev_pad = Trueelse:if len(ocrstr) == 0 or prev_pad or (len(ocrstr) > 0 and digit_nums[index] != ocrstr[-1]):prev_pad = Falseocrstr += digit_nums[index]print(ocrstr)return ocrstr
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论