
实战 | 异常检测与多场景应用
异常检测概述:
异常检测(anomaly detection),也叫异常分析(outlier analysis或者outlier detection)或者离群值检测,在工业上有非常广泛的应用场景:
金融业:从海量数据中找到“欺诈案例”,如信用卡反诈骗,识别虚假信贷
网络安全:从流量数据中找到“侵入者”,识别新的网络入侵模式
在线零售:从交易数据中发现“恶意买家”,比如恶意刷评等
生物基因:从生物数据中检测“病变”或“突变”
同时它可以被用于机器学习任务中的预处理(preprocessing),防止因为少量异常点存在而导致的训练或预测失败。换句话来说,异常检测就是从茫茫数据中找到那些“长得不一样”的数据。
但检测异常过程一般都比较复杂,而且实际情况下数据一般都没有标签(label),我们并不知道哪些数据是异常点,所以一般很难直接用简单的监督学习。异常值检测还有很多困难,如极端的类别不平衡、多样的异常表达形式、复杂的异常原因分析等。
异常值不一定是坏事。例如,如果在生物学中实验,一只老鼠没有死,而其他一切都死,那么理解为什么会非常有趣,这可能会带来新的科学发现。因此,检测异常值非常重要。
Python Outlier Detection(PyOD)是一个Python异常检测工具库,除了支持Sklearn上支持的四种模型外,还额外提供了很多模型如:
传统异常检测方法:HBOS、PCA、ABOD和Feature Bagging等,基于深度学习与神经网络的异常检测:自编码器(keras实现) ,其主要亮点包括:
1.包括近20种常见的异常检测算法,比如经典的LOF/LOCI/ABOD以及最新的深度学习如对抗生成模型(GAN)和集成异常检测(outlier ensemble)
2.所有算法共享通用的API,方便快速调包,同时支持Python2和3,支持多种操作系统:windows,macOS和Linux
3.代码经过了重重优化,大部分模型通过了并行与即时编译。使用JIT和并行化(parallelization)进行优化,加速算法运行及扩展性(scalability),可以处理大量数据
4.提供了详细的文档以及大量例子,方便快速上手
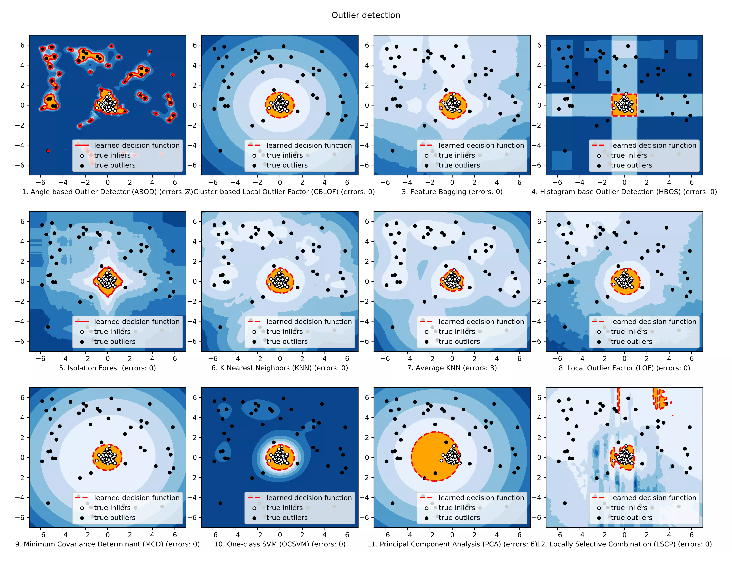
典型算法介绍:
Angle-Based Outlier Detection(ABOD)
它考虑每个点与其邻居之间的关系,它没有考虑这些邻居之间的关系,其加权余弦分数与所有邻居的方差可视为偏离分数
ABOD在多维数据上表现良好
PyOD提供两种不同版本的ABOD:
最大:使用第k个邻居的距离作为离群值
均值:使用所有k个邻居的平均值作为离群值得分
中位数:使用与邻居的距离的中位数作为离群值得分
