
我用特征工程+LR超过了xDeepFM!
AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications

Motivation
交叉特征通过原始特征的cross乘积的向量化构建得到:
其中是二元特征向量(hash trick之后套one-hot), 向量化一个张量,一个交叉特征也是一个二元特征向量。如果一个交叉特征使用三个或者更多的原始特征,我们就用高阶的交叉特征来表示它。
基于search的生成方法使用明显的搜索策略来构建特征集合的有用特征,大量的此类方法专注于数值特征并且没有产出交叉特征。
一方面,基于搜索的特征生成方法采用显式搜索策略来构造有用的特征或特征集。许多这样的方法集中于数值特征,而不产出交叉特征。对于现有的特征交叉方法,它们没有被设计成执行高阶特征交叉,因此效率低下。

在这一块,我们详细地看一下AutoCross的算法。
问题定义
我们假设所有的原始特征都是类别的,数据被表示为Multi-field的类别形式,其中每个field是一个从encoding得到的二元向量,给定训练数据, 我们将其划分为子训练集以及一个验证集合,我们用特征集合表示,用学习算法学习一个模型, 我们使用相同的特征集合验证集并计算一个metric, 最终我们就尝试最优化:
我们定义特征交叉问题为:
其中
为原始特征集合; 为原始特征集合和从中产出的可能的交叉特征;
特征集合产出
所有可能特征集合的数目为:, 这个几乎是无法接受的。所以此处我们使用迭代构建局部最优特征子集的方式来贪心挖掘特征。
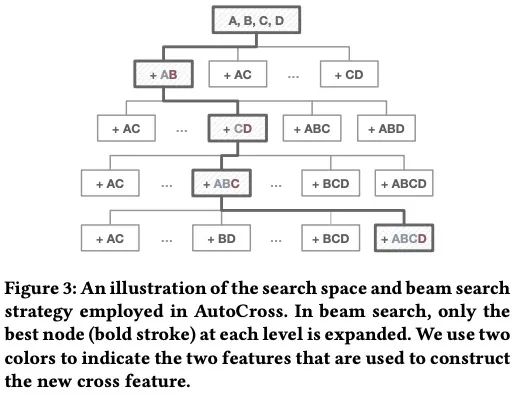
我们将两个特征和的交叉表示为, 成对特征的交叉就会产出更加高阶的特征。新的空间考虑中所有可能的特征交叉,同时忽略它的部分子集,搜索一个特征集合等价于从根节点到一个特定节点识别出一条路径。
这可以通过不断加入交叉特征到一个维护的特征集合中,但是,的大小是,其中是生成交叉特征的最大数。所以枚举出所有可能的解也是非常昂贵的。此处我们使用beam search的策略来解决该问题。
beam search的思想:在搜索过程中只扩展最有前途的节点。首先生成根节点的所有子节点,评估其对应的特征集,然后选择性能最好的节点进行下一次访问。在接下来的过程中,我们扩展当前节点并访问其最有希望的子节点。当过程终止时,我们在一个被认为是解决方案的节点处结束.
通过beam search,我们只性需要考虑的节点。
特征集的评估
为了提升模型的评估效率,本文提出了field-wise LR以及连续的mini-batch GD档案。
1. field-wise LR
此处有两种假设:
我们做了两个近似值。首先,我们使用经过小批量梯度下降训练的logistic回归(LR)来评估候选特征集,并用相应的性能来近似实际跟踪的学习算法L的性能。我们选择logistic回归作为一种广义线性模型,是大规模机器学习中应用最广泛的模型。它具有简单、可扩展、推理速度快、可解释性强等特点; 在模型训练的时候,我们仅仅学习新增加的交叉特征的权重,其他的权重则被固定。所以训练时“filed-wise”的。举例来说,我们有一个特征集合, 我们希望对候选集进行评估,在训练的时候只有AB的权重会被更新,我们用进行表示,表示之前所有特征,是新增加的交叉特征;他们对应的权重为:, LR会做下面的预测:
其中为sigmoid函数。更新的框架如下:
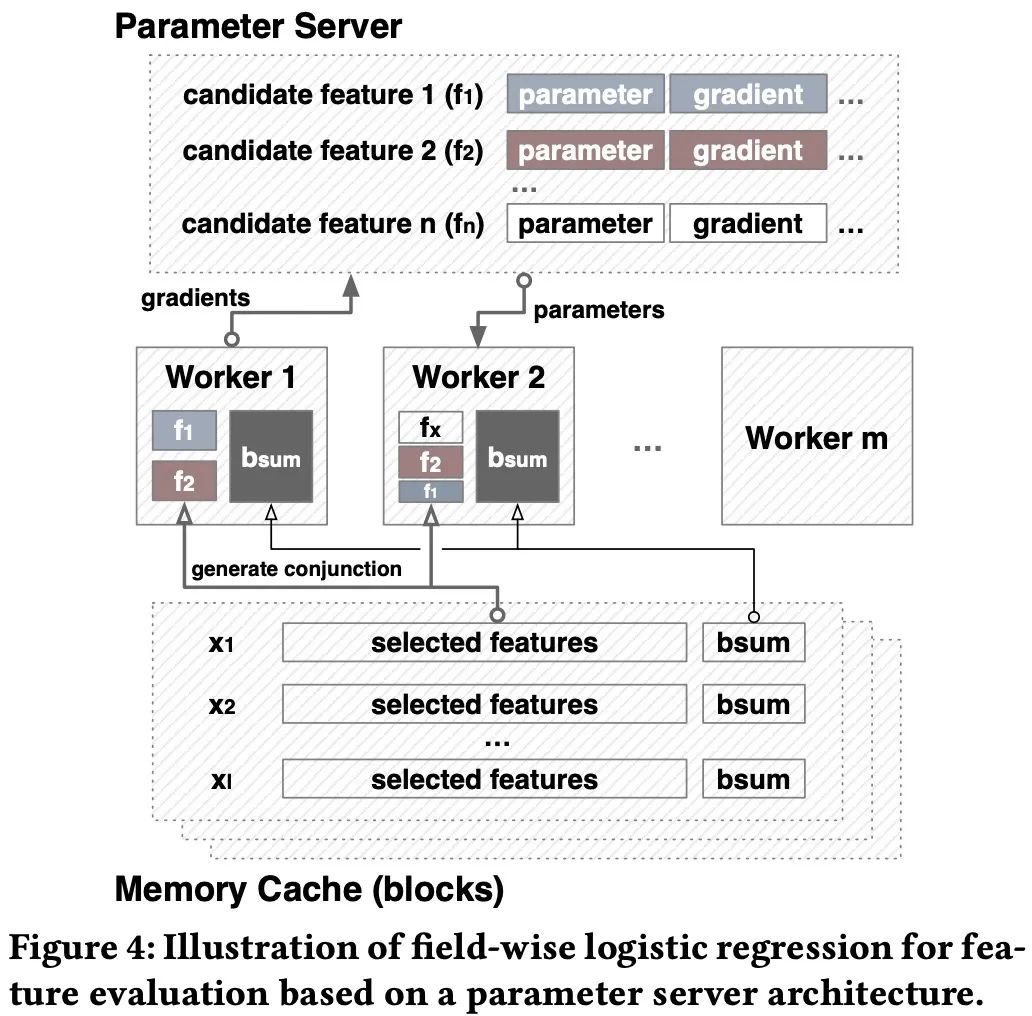
它的优势如下:
存储,workers只需要存储和; 计算速度:快速,因为我们只需要更新;
2. Successive Mini-batch Gradient Descent

预处理
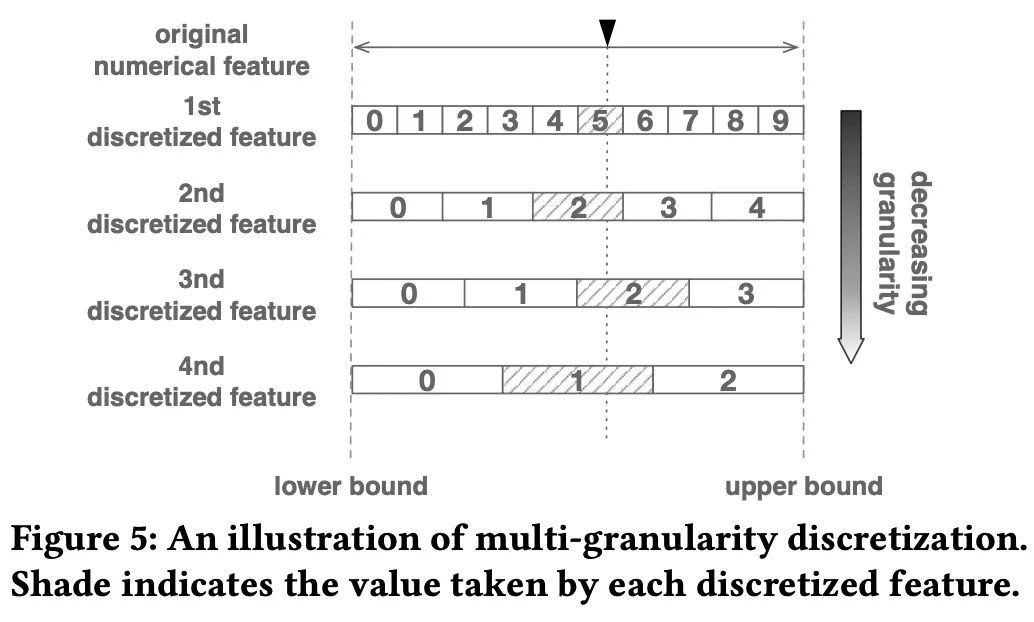
在数据预处理处,我们使用离散化的策略对数据进行预处理方便后续的特征交叉。为了使离散化过程自动化,避免对专家的依赖,提出了一种多粒度离散化方法,详细地可以参考下图:
终止
AutoCross使用了三种终止条件:
运行时条件:用户可以设置AutoCross的最大运行时间。当时间流逝时,AutoCross终止输出当前解决方案。另外,用户可以随时中断该过程并得到时间的结果; 性能条件:在生成新的特征集后,用LR模型的所有特征进行训练。如果与前一组相比,验证性能下降,则终止验证过程; 最大特征数:用户可以给出一个最大交叉特征数,当达到该数目时自动交叉停止;
1. 效果比较
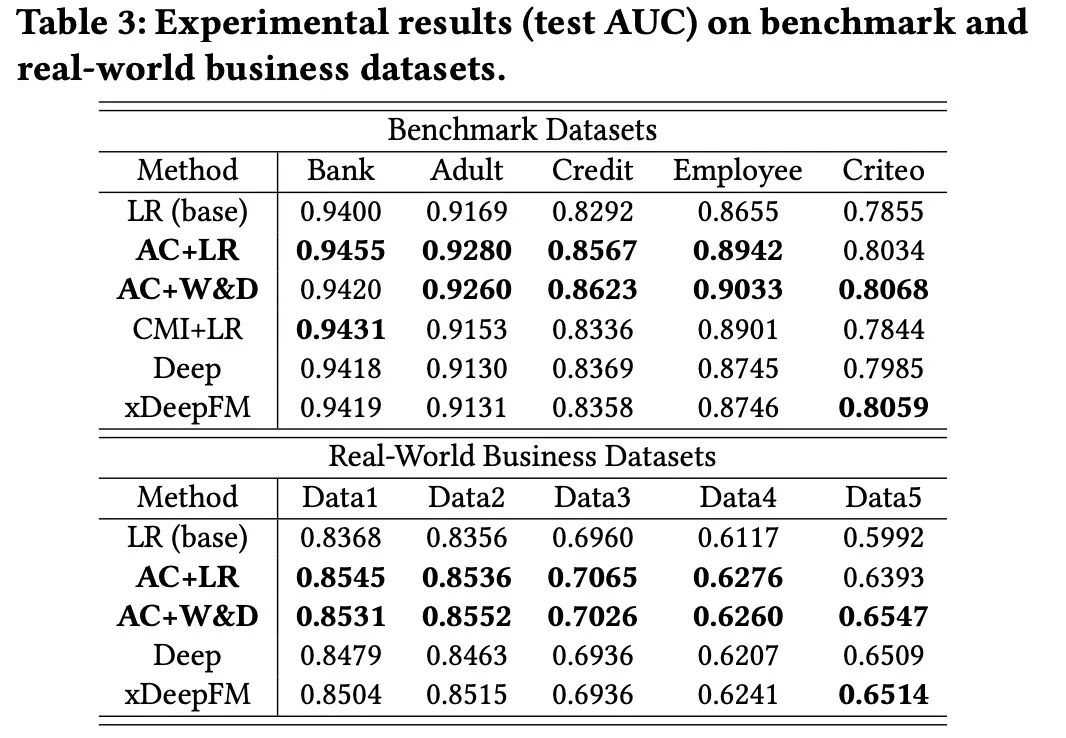
AC+LR和AC+W&D都比LR(base)有显著的改善,AC+W&D也显著提高了deep模型的性能。 这些结果表明,通过生成交叉特征,AutoCross可以使数据更具信息性和区分性,并提高学习性能。AutoCross取得的有希望的结果也证明了filed-wise LR识别有用交叉特征的能力
2. 高阶特征的影响
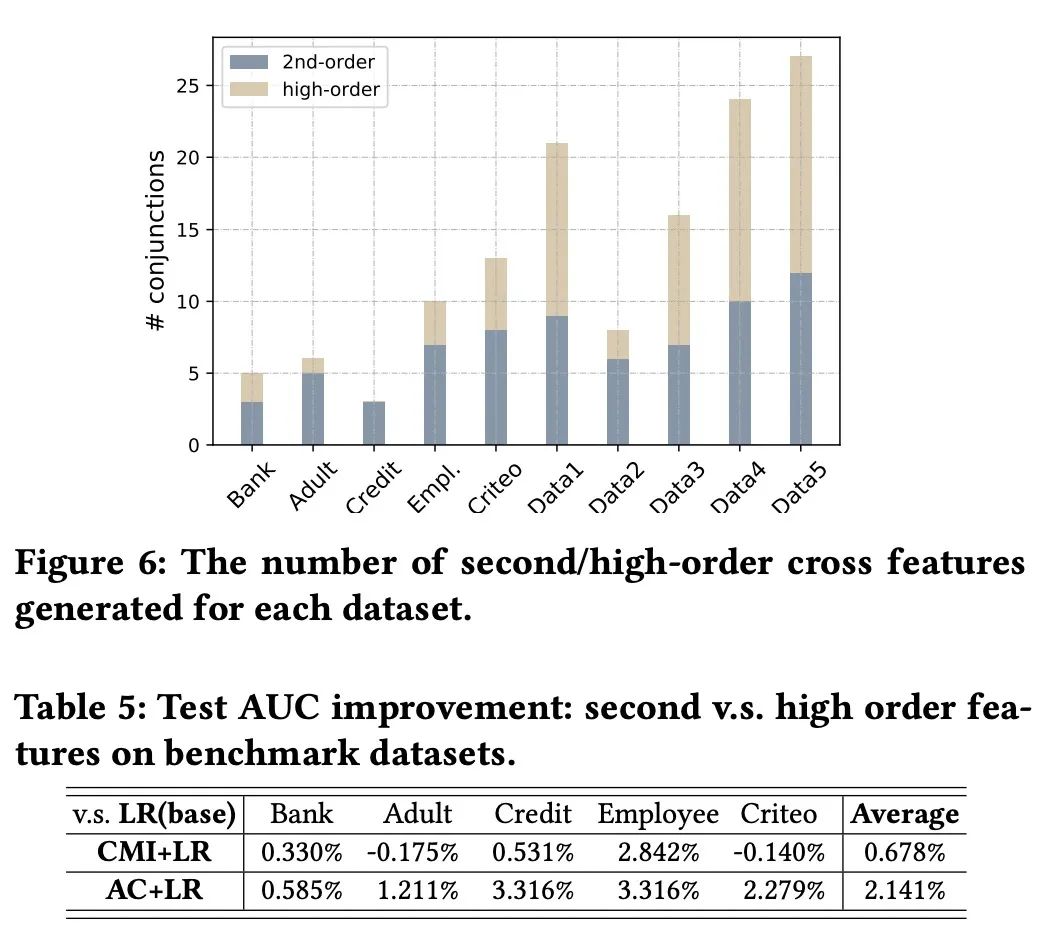
高阶特征能为模型带来非常不错的提升。
3. 模型的速度和预测时间
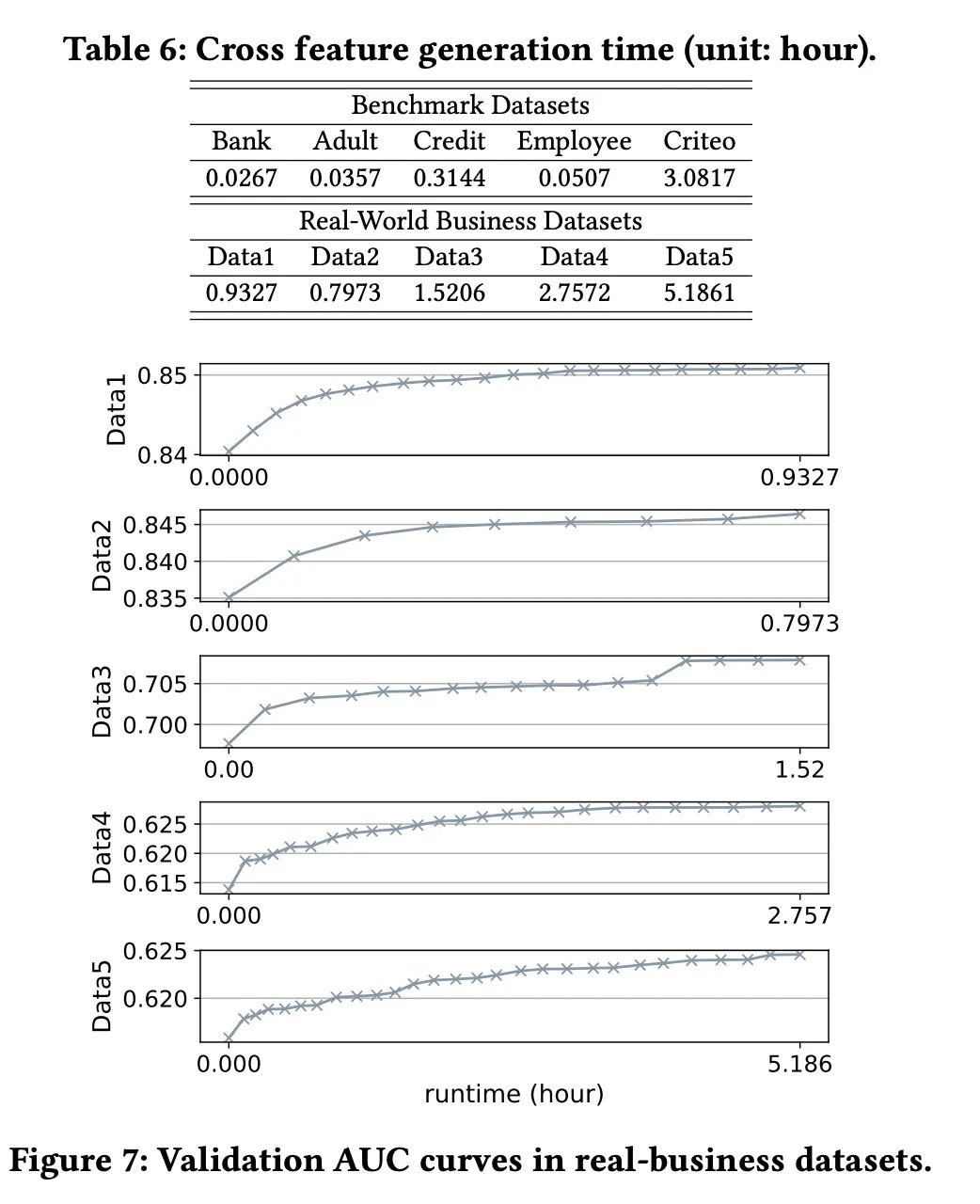
模型的特征交叉速度很快; 模型的预测速度相较于神经网络也快了很多;
本文介绍了AutoCross,一种在实际应用中用于表格数据的自动特征交叉方法。它捕捉分类特征之间的有用交互作用,并提高学习算法的预测能力。它利用beam-search来高效地构造交叉特征,从而可以考虑到高阶特征交叉,而这是现有研究中尚未涉及到的。此外,本文提出了连续的小批量梯度下降和多粒度离散化方法,在保持高度简单性的前提下,进一步提高了效率和效率。所有的算法都是为分布式计算而设计的,用于处理现实世界中的大数据。实验结果表明,AutoCross可以显著增强表格数据的学习能力,优于其他基于搜索和基于深度学习的针对同一主题的特征生成方法。
AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications:https://arxiv.org/pdf/1904.12857.pdf