
卷积层和分类层,哪个更重要?
点击左上方蓝字关注我们

卷积层和分类层,哪个更重要?
在分类任务里,一个网络能达到比较好的效果,那么是其中提feature的卷积层效果比较好呢,还是分类器训练的比较好?哪个更重要一点呢?
因为我想直接拿预训练的网络提的feature做其他的事情,并不是要单纯完成分类任务,所以我不确定卷积层提的feature是不是就是我想要的,因此提出这个问题。
夕小瑶
机器学习 话题的优秀回答者
这个问题虽然问的很大,但是在细分领域内蛮有意思的(感谢题主你将讨论范围限定在分类,要不然真没法答了)
正好以前研究过这个问题,基于图像和文本这两个经典领域说一下吧。先说感性结论,强特征数量多但是容易提取的话分类层更重要,反之卷积层更重要。压榨分类性能的话依然是卷积层更重要。
图像分类场景
图像任务貌似没什么悬念,从LeNet,AlexNet到GoogLeNet, ResNet等,卷积层数的加深对模型性能的提升是大家有目共睹的事情,这其中一个很重要的原因就是图像数据中对于分类描述能力强的特征往往隐藏的很深,难以直接在原始像素数据中描述。以人脸检测为例,想象一下手写一个规则来映射像素值到高level特征“嘴”的难度。但是,想象一下,如果我们得到了一个样本的高level特征,比如特征向量的每个维度分别描述图片里有眼睛,鼻子,嘴的可能性,那么这时再做人脸检测的话是不是就容易多了?手写规则都感觉貌似可以做的不错(一条简单粗暴的规则:设置一个决策阈值将各个特征cast到bool型,然后眼睛+鼻子+嘴=人脸,else=无人脸)。
也就是说,在人脸检测任务中,强分类特征隐藏很深但是数量不多,一旦提取到了这些较为有效的特征,分类就变得异常容易(相对来说)。所以对于图像分类来说当然是要花大精力去提取这些特征啊,所以你看,大佬们把卷积层做的这么深,分类层却没太大的变化,懂了吧~(当然,这里说的眼睛,鼻子,嘴等强特征不一定能被深度卷积层学习到,但是毫无疑问的是顶层卷积层的神经元一定学到了其他类似的强特征[1])
文本分类场景
文本分类则恰好是对面的世界。试想一下,你要对文本进行情感分类时,文本里的有效特征容易get吗?简直一想一大把哇,比如“开心”,“好棒”,“难过”,“烦”,“伤心“都是对于分类来说非常实锤的强特征,基本上只要样本里出现了其中一个特征,就能以非常大的把握决定这个样本的情感极性。也就是说,文本分类里的强特征藏的非常浅,从原始数据里可以轻松描述。但是,这些强特征也非常之多,情感词有多少?情感短语呢?是不是觉得数不清哇?数不清就对啦~
但是,拿到一个样本的一组强特征后,好不好准确分类呢?对于大部分样本来说,直接学习每个特征的权重然后做个简单的加权就好咯,这确实可以取得非常好的效果,因此朴素贝叶斯这个异常简单的线性分类器以及2014Kim提出的这个简单的浅卷积文本分类器[5](俗称TextCNN)可以在文档分类任务中取得非常高的性能。如图1。
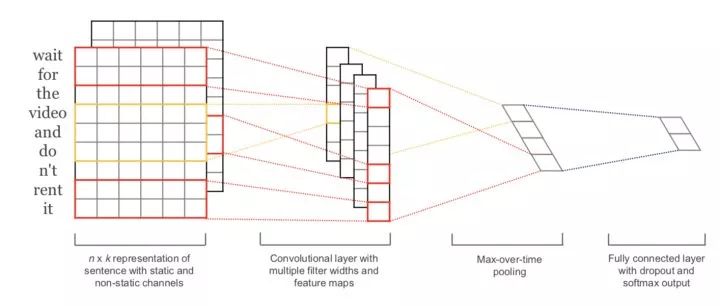
但是总有一些描述“隐晦”的样本,可能明褒暗贬,那这种线性分类器就无力了。怎么办呢?
当然是加强分类层呀~让分类层给每个情感词的重要性打分!让分类层去描述中性词与情感词的作用关系,让分类层找出情感词共现的分类规律,反正我提取特征的层已经给你把特征提取出来了哼。
好了口说无凭,近年来已经有不止一篇paper专门研究文本分类里的卷积层深浅的有效性问题,[2]使用[4]这个简单的一层卷积+线性分类就已经足以让文本分类取得非常好的效果了,而作者将DenseNet直接拿来用发现效果很差劲,性能如下表。
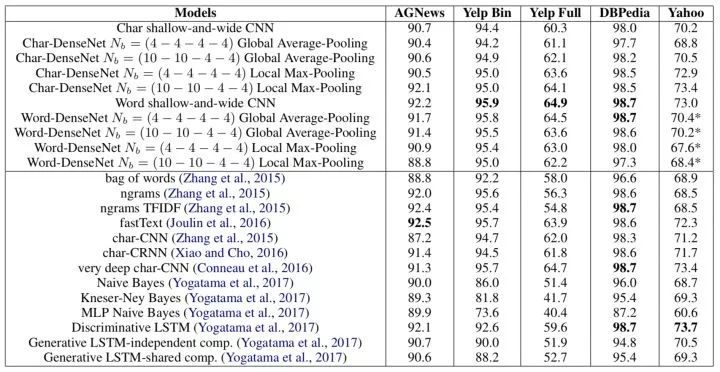
[3]类似。同时[4]提出的DAN(Deep Averaging Nets)恰好是指出特征随便提取一下(仅使用神经词袋模型),然后分类层疯狂加深,则发现可以大幅提升文本语义的描述能力,如图2。
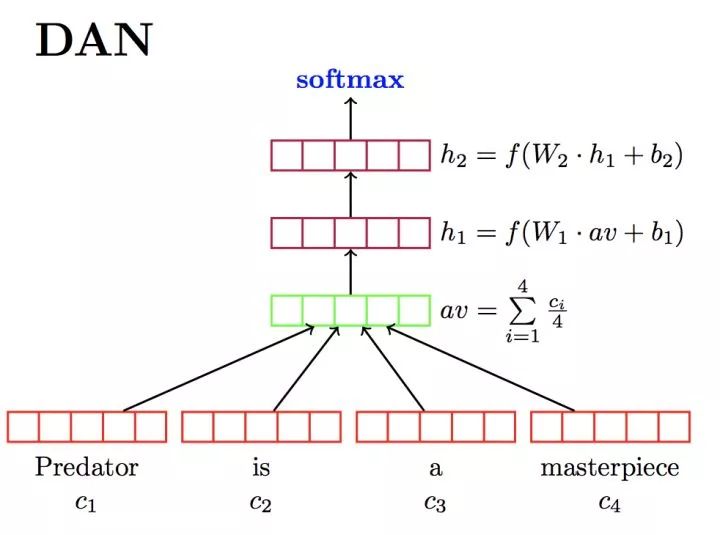
同时我自己也做了一下相关研究,发现仅使用1层CNN+3层全连接即在大多数文本分类数据集上超过了当时的state-of-art,当时做实验时首先用的是1层CNN1层全连接,也就是2014Kim[5]的这个经典结构,然后加深CNN却发现模型性能不升反降,但是加深全连接却明显提升,加到3层时提升的效果很显著,4层又能得到小幅提升,5层出现下降,6层下降明显。所以在出现提取了大量强特征的情况时,考虑加深一下分类层还是比较有意义的尝试。
“职责转移”问题
直到2017ACL上有篇文章提出的Deep Pyramid CNN (DPCNN)[6],才让人觉得貌似word-level的文本分类模型也是可以做的很深嘛,只不过确实要设计的非常谨慎。DPCNN结构如图3。

诶?刚不说了强特征数量多但是容易提取时,CNN没必要太深,分类层值得加深嘛?
其实这里是存在一个“职责转移”的通道的。众所周知,把分类层做深是计算代价很高、学习效率很低的操作,而卷积层则高效的多。既然加深分类层获得性能增益的原理是学习特征之间的关联与权重,也就是类似于将特征进行加权以及合并。那么其实这个过程可以提到卷积层进行。
想一想,如果特征“不要”和“太好”在文本里先后邻接出现的话,那显然这两个强特征可以合并为“不要太好”这个强特征,类似于“很好”的语义。同样,特征之间还可以通过句法关系来进一步合并,只不过这种句法关系可能空间上相隔较远,需要多叠几层卷积层才方便捕捉。通过卷积层来进行特征合并更加接近样本里本来的特征作用关系,因此这种操作在这一层面上反而是比加深分类层更加高效明智的。
也正因为如此,随便一加深卷积层是容易起反效果的,这时既难以很准确的合并特征,还可能产生了一堆干扰分类的噪声特征,正如[2]中展现的DenseNet直接从图像领域拿到文本领域是非常不work的,而经过精心设计的DPCNN[6]就能取得显著的分类性能提升。我猜这也是为什么时隔这么久才在文本分类领域出现一个word-level “ResNet”的原因吧。
参考文献
[1] http://www-cs.stanford.edu/people/ang/papers/icml09-ConvolutionalDeepBeliefNetworks.pdf
[2] Le H T, Cerisara C, Denis A. Do Convolutional Networks need to be Deep for Text Classification?[J]. arXiv preprint arXiv:1707.04108, 2017.
[3] Rie Johnson and Tong Zhang. 2016. Convolutional neural networks for text categorization: Shallow word-level vs. deep character-level.arXiv:1609.00718 .
[4] Iyyer M, Manjunatha V, Boyd-Graber J, et al. Deep unordered composition rivals syntactic methods for text classification[C]//Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2015, 1: 1681-1691.
[5] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.
[6] Johnson R, Zhang T. Deep pyramid convolutional neural networks for text categorization[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017, 1: 562-570.
END