点击上方“Jack Cui”,选择“设为星标”
大家好,我是 Jack 。
最近又有一个算法火了,不知道你们看到没?直接看效果!
效果这么稳定的人像 Image Matting 算法真的不多,并且还能进行实时处理!
处理视频、图像,不在话下。人在家中坐,录段视频,你就可以把自己放到世界各地的美景中。
这类的抠图 AI 算法,已经出现过不少,但这一款确实让人觉得很惊艳。
打工人的周游世界梦,还能靠 AI 算法实现,泪目!
当前对人像 Matting 的研究主要围绕这两点:不使用 trimap 情况下提高精度
实时与准确性兼顾
MODNet 都做到了,作者充分利用 Ground Truth 的信息,将模型学习分为三个部分:语义估计、细节预测和语义细节融合。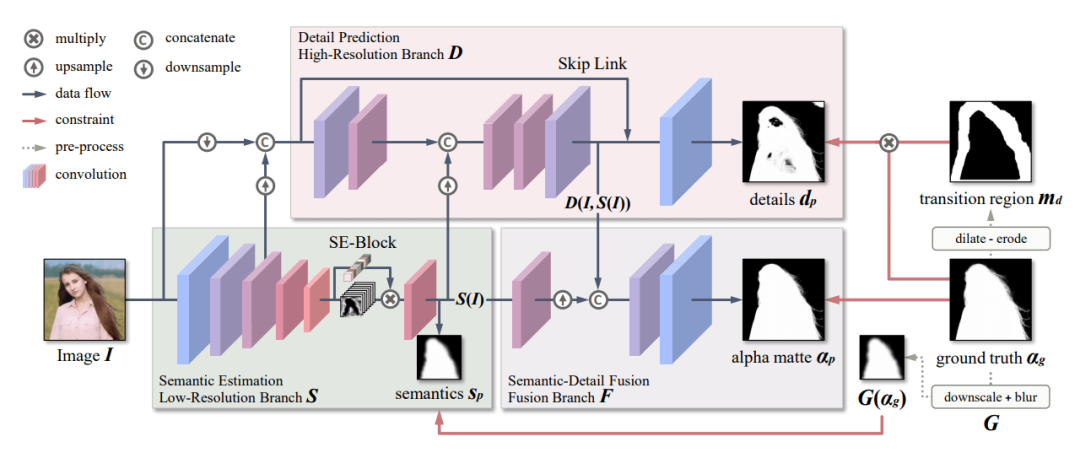
语义估计(Semantic Estimation):采用 MobileNetV2 架构,通过编码器(即 MODNet 的低分辨率分支)来提取高层语义。对 high-level 的特征结果进行监督学习,标签使用的是下采样及高斯模糊后的GT,损失函数用的 L2-Loss。细节预测(Detail Prediction):结合了输入图像的信息和语义部分的输出特征,通过 encoder-decoder 对人像边缘进行单独地约束学习,用的是交叉熵损失函数。为了减小计算量,encoder-decoder 结构较为 shallow ,同时处理的是原图下采样后的尺度。语义细节融合(Semantic-Detail Fusion):把语义输出和细节输出结果拼起来后得到最终的 alpha 结果,这部分约束用的是 L1-Loss。另外,基于以上底层框架,该研究还提出了一种自监督学习方法 SOC(Sub-Objectives Consistency)和帧延迟处理方法 OFD(One-Frame Delay )。其中,SOC 策略可以保证 MODNet 架构在处理未标注数据时,让输出的子目标之间具有一致性;OFD 方法在执行人像抠像视频任务时,可以在平滑视频序列中预测 alpha 遮罩。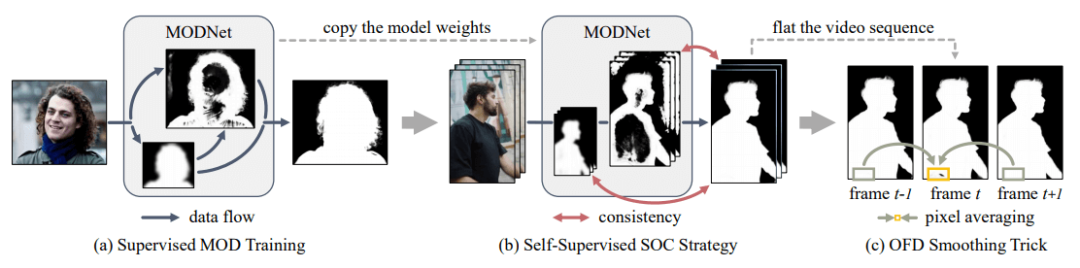
为了让输入图像的 alpha 输出与语义、细节输出相一致,分别用 L2 和 L1 损失进行约束。其中 Loss 第一项 L2 约束语义部分,第二项 L1 约束边缘细节部分。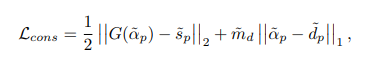
另一方面,为了保持原有的细节信息不被丢失,又将自监督的细节输出和原本全监督训练下的细节输出进行 L1 约束。
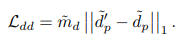
SOC 这一步不需要标注数据,只是网络模型的自监督学习。这部分主要解决视频分割结果的闪烁等问题,提高时序稳定性。后处理操作需要满足一定条件: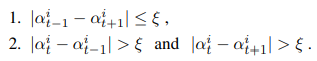
即连续三帧中,首尾两帧差异小且中间帧与首尾两帧差异大。
如上图所示,只有红框像素满足处理条件。后处理方式也简单,中间帧结果取首尾两帧平均。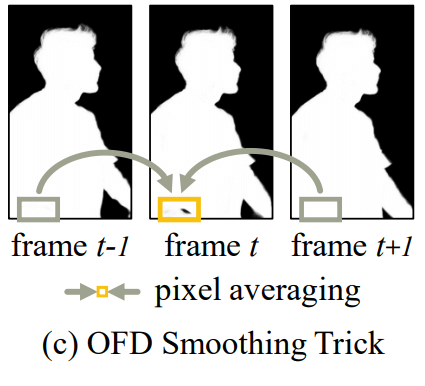
研究人员创建了一个摄影人像基准数据集 PPM-100(Photographic Portrait Matting)。
它包含了 100 幅不同背景的已精细注释的肖像图像。
为了保证样本的多样性,PPM-100 还被定义了几个分类规则,来平衡样本类型。
比如是否包括整个人体;图像背景是否模糊;是否持有其他物体。

PPM-100 中的样图具有丰富的背景和人物姿势,可以被看做一个较为全面的基准。
采用 PPM-100 评估集,看下 MODNet 的效果: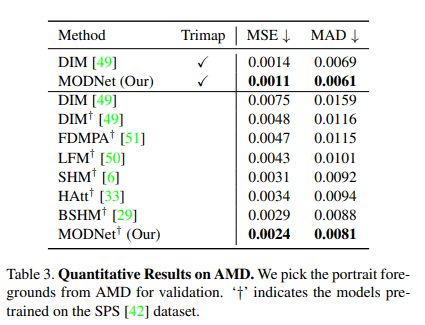
MODNet 在 MSE(均方误差)和 MAD(平均值)上都优于其他无 Trimap 的方法。虽然它的性能不如采用 Trimap 的 DIM ,但如果将 MODNet 修改为基于 Trimap 的方法。即以 Trimap 作为输入,它的性能会优于基于 Trimap 的 DIM,这也再次表明显示 MODNet 算法的优越性。此外,研究人员还进一步证明了 MODNet 在模型大小和执行效率方面的优势。其中,模型大小通过参数总数来衡量,执行效率采用 NVIDIA GTX1080 Ti GPU 测试。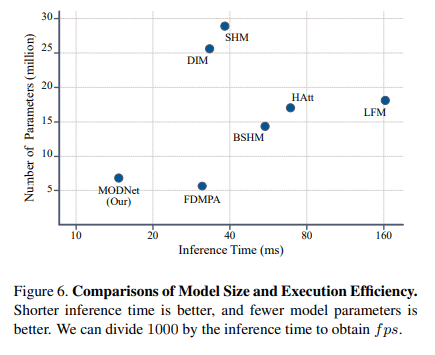
MODNet 的推理时间为 15.8ms(63fps),比 FDMPA(31fps)快两倍。总之,MODNet 提出了一个简单、快速稳定的实时人像抠图处理算法。https://arxiv.org/pdf/2011.11961.pdf
我猜,有些读者,早已迫不及待地跳过算法原理说明,直接来找代码了。https://github.com/ZHKKKe/MODNet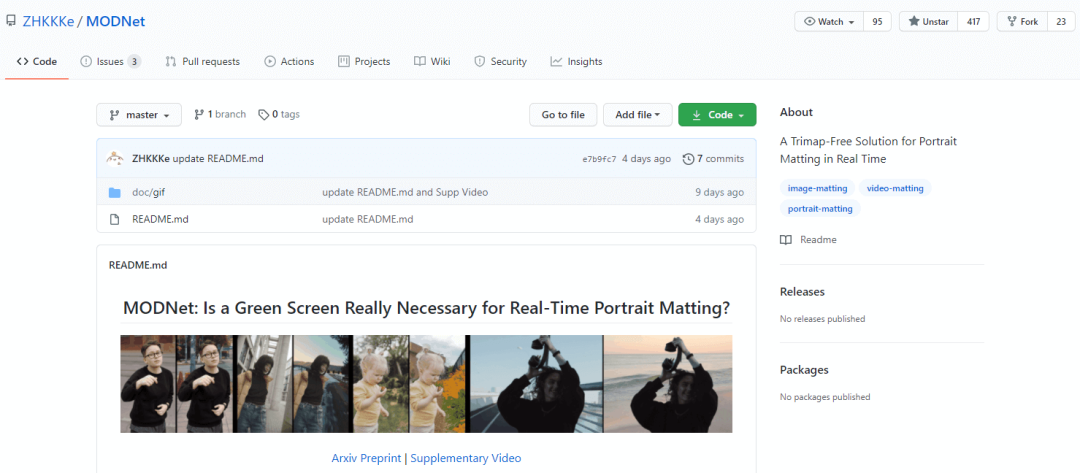
写稿截图的时候,项目只有一个 README,但是 Star 都快 500 了,足以看出人们对算法效果的认可,以及对算法代码实现的关注。作者在 issues 中提到,两周后放代码和模型!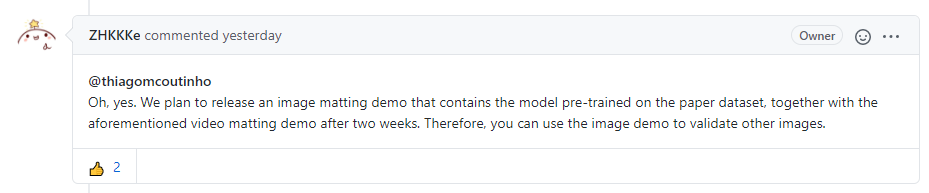
MODNet 没开源,周末没得玩了?
我早已想到,当然不会让你们空手而归!
navigan 也是一个新鲜出炉的算法。能变脸,改变人的鼻子大小、眼睛大小、眼睛朝向、嘴巴的位置、眉毛高低、甚至让人吸血鬼化。


也可以改变汽车轮子的大小,马的胖瘦。一个挺好玩的 GAN,感兴趣可以周末玩一玩。
项目地址:
https://github.com/yandex-research/navigan
官方权重文件放在了 Dropbox ,下载费事,所以我将代码和权重文件打包放到了百度网盘,有的需要自取(提取码:jack ):
https://pan.baidu.com/s/1U2SrSguDaPwncMw0TgPXtA
明天就周末了,提前说声周末愉快~
我是 Jack ,我们下期见。
·················END·················

