
【西法带你学算法】一次搞定前缀和
点击蓝色“力扣加加”关注我哟
加个“星标”,带你揭开算法的神秘面纱!
❝这是力扣加加第「21」篇原创文章
❞
我花了几天时间,从力扣中精选了五道相同思想的题目,来帮助大家解套,如果觉得文章对你有用,记得点赞分享,让我看到你的认可,有动力继续做下去。
467. 环绕字符串中唯一的子字符串[1](中等) 795. 区间子数组个数[2](中等) 904. 水果成篮[3](中等) 992. K 个不同整数的子数组[4](困难) 1109. 航班预订统计[5](中等)

前四道题都是滑动窗口的子类型,我们知道滑动窗口适合在题目要求连续的情况下使用, 而前缀和[6]也是如此。二者在连续问题中,对于「优化时间复杂度」有着很重要的意义。因此如果一道题你可以用暴力解决出来,而且题目恰好有连续的限制, 那么滑动窗口和前缀和等技巧就应该被想到。
除了这几道题, 还有很多题目都是类似的套路, 大家可以在学习过程中进行体会。今天我们就来一起学习一下。
前菜
我们从一个简单的问题入手,识别一下这种题的基本形式和套路,为之后的四道题打基础。当你了解了这个套路之后, 之后做这种题就可以直接套。
需要注意的是这四道题的前置知识都是 滑动窗口, 不熟悉的同学可以先看下我之前写的 滑动窗口专题(思路 + 模板)[7]
母题 0
有 N 个的正整数放到数组 A 里,现在要求一个新的数组 B,新数组的第 i 个数 B[i]是原数组 A 第 0 到第 i 个数的和。
这道题可以使用前缀和来解决。前缀和是一种重要的预处理,能大大降低查询的时间复杂度。我们可以简单理解为“数列的前 n 项的和”。这个概念其实很容易理解,即一个数组中,第 n 位存储的是数组前 n 个数字的和。
对 [1,2,3,4,5,6] 来说,其前缀和可以是 pre=[1,3,6,10,15,21]。我们可以使用公式 pre[?]=pre[?−1]+nums[?]得到每一位前缀和的值,从而通过前缀和进行相应的计算和解题。其实前缀和的概念很简单,但困难的是如何在题目中使用前缀和以及如何使用前缀和的关系来进行解题。
母题 1
如果让你求一个数组的连续子数组总个数,你会如何求?其中连续指的是数组的索引连续。比如 [1,3,4],其连续子数组有:[1], [3], [4], [1,3], [3,4] , [1,3,4],你需要返回 6。
一种思路是总的连续子数组个数等于:「以索引为 0 结尾的子数组个数 + 以索引为 1 结尾的子数组个数 + ... + 以索引为 n - 1 结尾的子数组个数」,这无疑是完备的。
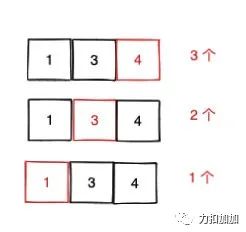
同时「利用母题 0 的前缀和思路, 边遍历边求和。」
参考代码(JS):
function countSubArray(nums) {
let ans = 0;
let pre = 0;
for (_ in nums) {
pre += 1;
ans += pre;
}
return ans;
}
「复杂度分析」
时间复杂度:,其中 N 为数组长度。 空间复杂度:
而由于以索引为 i 结尾的子数组个数就是 i + 1,因此这道题可以直接用等差数列求和公式 (1 + n) * n / 2,其中 n 数组长度。
母题 2
我继续修改下题目, 如果让你求一个数组相邻差为 1 连续子数组的总个数呢?其实就是「索引差 1 的同时,值也差 1。」
和上面思路类似,无非就是增加差值的判断。
参考代码(JS):
function countSubArray(nums) {
let ans = 1;
let pre = 1;
for (let i = 1; i < nums.length; i++) {
if (nums[i] - nums[i - 1] == 1) {
pre += 1;
} else {
pre = 0;
}
ans += pre;
}
return ans;
}
「复杂度分析」
时间复杂度:,其中 N 为数组长度。 空间复杂度:
如果我值差只要大于 1 就行呢?其实改下符号就行了,这不就是求上升子序列个数么?这里不再继续赘述, 大家可以自己试试。
母题 3
我们继续扩展。
如果我让你求出不大于 k 的子数组的个数呢?不大于 k 指的是子数组的全部元素都不大于 k。比如 [1,3,4] 子数组有 [1], [3], [4], [1,3], [3,4] , [1,3,4],不大于 3 的子数组有 [1], [3], [1,3] ,那么 [1,3,4] 不大于 3 的子数组个数就是 3。实现函数 atMostK(k, nums)。
参考代码(JS):
function countSubArray(k, nums) {
let ans = 0;
let pre = 0;
for (let i = 0; i < nums.length; i++) {
if (nums[i] <= k) {
pre += 1;
} else {
pre = 0;
}
ans += pre;
}
return ans;
}
「复杂度分析」
时间复杂度:,其中 N 为数组长度。 空间复杂度:
母题 4
如果我让你求出子数组最大值刚好是 k 的子数组的个数呢?比如 [1,3,4] 子数组有 [1], [3], [4], [1,3], [3,4] , [1,3,4],子数组最大值刚好是 3 的子数组有 [3], [1,3] ,那么 [1,3,4] 子数组最大值刚好是 3 的子数组个数就是 2。实现函数 exactK(k, nums)。
实际上是 exactK 可以直接利用 atMostK,即 atMostK(k) - atMostK(k - 1),原因见下方母题 5 部分。
母题 5
如果我让你求出子数组最大值刚好是 介于 k1 和 k2 的子数组的个数呢?实现函数 betweenK(k1, k2, nums)。
实际上是 betweenK 可以直接利用 atMostK,即 atMostK(k1, nums) - atMostK(k2 - 1, nums),其中 k1 > k2。前提是值是离散的, 比如上面我出的题都是整数。因此我可以直接 减 1,因为 「1 是两个整数最小的间隔」。
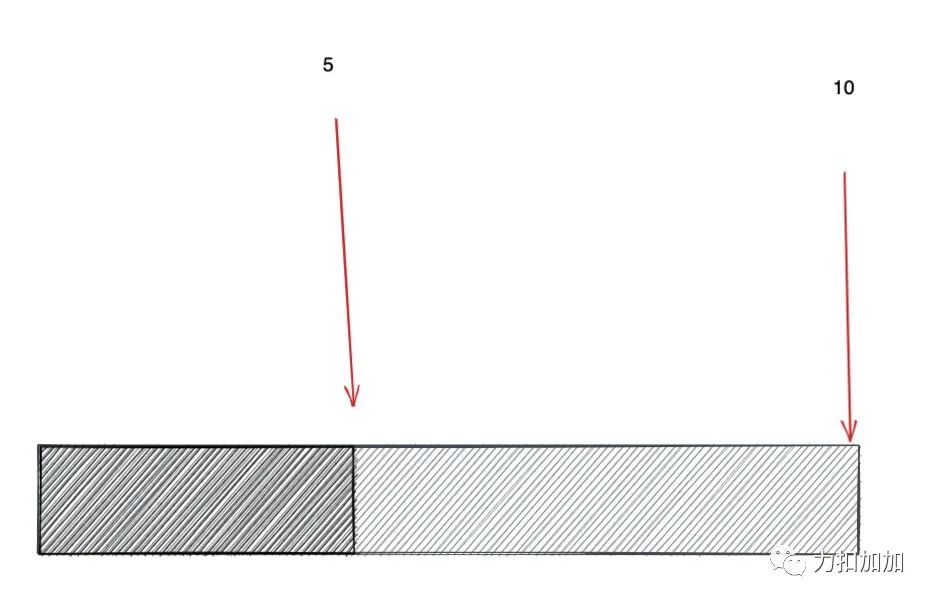
如上,小于等于 10 的区域减去 小于 5 的区域就是 大于等于 5 且小于等于 10 的区域。
注意我说的是小于 5, 不是小于等于 5。由于整数是离散的,最小间隔是 1。因此小于 5 在这里就等价于 小于等于 4。这就是 betweenK(k1, k2, nums) = atMostK(k1) - atMostK(k2 - 1) 的原因。
因此不难看出 exactK 其实就是 betweenK 的特殊形式。当 k1 == k2 的时候, betweenK 等价于 exactK。
因此 atMostK 就是灵魂方法,一定要掌握,不明白建议多看几遍。
有了上面的铺垫, 我们来看下第一道题。
467. 环绕字符串中唯一的子字符串(中等)
题目描述
把字符串 s 看作是“abcdefghijklmnopqrstuvwxyz”的无限环绕字符串,所以 s 看起来是这样的:"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd....".
现在我们有了另一个字符串 p 。你需要的是找出 s 中有多少个唯一的 p 的非空子串,尤其是当你的输入是字符串 p ,你需要输出字符串 s 中 p 的不同的非空子串的数目。
注意: p 仅由小写的英文字母组成,p 的大小可能超过 10000。
示例 1:
输入: "a"
输出: 1
解释: 字符串 S 中只有一个"a"子字符。
示例 2:
输入: "cac"
输出: 2
解释: 字符串 S 中的字符串“cac”只有两个子串“a”、“c”。.
示例 3:
输入: "zab"
输出: 6
解释: 在字符串 S 中有六个子串“z”、“a”、“b”、“za”、“ab”、“zab”。.
前置知识
滑动窗口
思路
题目是让我们找 p 在 s 中出现的非空子串数目,而 s 是固定的一个无限循环字符串。由于 p 的数据范围是 10^5 ,因此暴力找出所有子串就需要 10^10 次操作了,应该会超时。而且题目很多信息都没用到,肯定不对。
仔细看下题目发现,这不就是母题 2 的变种么?话不多说, 直接上代码,看看有多像。
❝为了减少判断, 我这里用了一个黑科技, p 前面加了个
❞^。
class Solution:
def findSubstringInWraproundString(self, p: str) -> int:
p = '^' + p
w = 1
ans = 0
for i in range(1,len(p)):
if ord(p[i])-ord(p[i-1]) == 1 or ord(p[i])-ord(p[i-1]) == -25:
w += 1
else:
w = 1
ans += w
return ans
如上代码是有问题。比如 cac会被计算为 3,实际上应该是 2。根本原因在于 c 被错误地计算了两次。因此一个简单的思路就是用 set 记录一下访问过的子字符串即可。比如:
{
c,
abc,
ab,
abcd
}
而由于 set 中的元素一定是连续的,因此上面的数据也可以用 hashmap 存:
{
c: 3
d: 4
b: 1
}
含义是:
以 b 结尾的子串最大长度为 1,也就是 b。 以 c 结尾的子串最大长度为 3,也就是 abc。 以 d 结尾的子串最大长度为 4,也就是 abcd。
至于 c ,是没有必要存的。我们可以通过母题 2 的方式算出来。
具体算法:
定义一个 len_mapper。key 是 字母, value 是 长度。含义是以 key 结尾的最长连续子串的长度。
❝关键字是:最长
❞
用一个变量 w 记录连续子串的长度,遍历过程根据 w 的值更新 len_mapper 返回 len_mapper 中所有 value 的和。
比如: abc,此时的 len_mapper 为:
{
c: 3
b: 2
a: 1
}
再比如:abcab,此时的 len_mapper 依旧。
再比如: abcazabc,此时的 len_mapper:
{
c: 4
b: 3
a: 2
z: 1
}
这就得到了去重的目的。这种算法是不重不漏的,因为最长的连续子串一定是包含了比它短的连续子串,这个思想和 1297. 子串的最大出现次数[8] 剪枝的方法有异曲同工之妙。
代码(Python)
class Solution:
def findSubstringInWraproundString(self, p: str) -> int:
p = '^' + p
len_mapper = collections.defaultdict(lambda: 0)
w = 1
for i in range(1,len(p)):
if ord(p[i])-ord(p[i-1]) == 1 or ord(p[i])-ord(p[i-1]) == -25:
w += 1
else:
w = 1
len_mapper[p[i]] = max(len_mapper[p[i]], w)
return sum(len_mapper.values())
「复杂度分析」
时间复杂度:,其中 为字符串 p 的长度。 空间复杂度:由于最多存储 26 个字母, 因此空间实际上是常数,故空间复杂度为 。
795. 区间子数组个数(中等)
题目描述
给定一个元素都是正整数的数组 A ,正整数 L 以及 R (L <= R)。
求连续、非空且其中最大元素满足大于等于 L 小于等于 R 的子数组个数。
例如 :
输入:
A = [2, 1, 4, 3]
L = 2
R = 3
输出: 3
解释: 满足条件的子数组: [2], [2, 1], [3].
注意:
L, R 和 A[i] 都是整数,范围在 [0, 10^9]。
数组 A 的长度范围在[1, 50000]。
前置知识
滑动窗口
思路
由母题 5,我们知道 「betweenK 可以直接利用 atMostK,即 atMostK(k1) - atMostK(k2 - 1),其中 k1 > k2」。
由母题 2,我们知道如何求满足一定条件(这里是元素都小于等于 R)子数组的个数。
这两个结合一下, 就可以解决。
代码(Python)
❝代码是不是很像
❞
class Solution:
def numSubarrayBoundedMax(self, A: List[int], L: int, R: int) -> int:
def notGreater(R):
ans = cnt = 0
for a in A:
if a <= R: cnt += 1
else: cnt = 0
ans += cnt
return ans
return notGreater(R) - notGreater(L - 1)
「复杂度分析」
时间复杂度:,其中 为数组长度。 空间复杂度:。
904. 水果成篮(中等)
题目描述
在一排树中,第 i 棵树产生 tree[i] 型的水果。
你可以从你选择的任何树开始,然后重复执行以下步骤:
把这棵树上的水果放进你的篮子里。如果你做不到,就停下来。
移动到当前树右侧的下一棵树。如果右边没有树,就停下来。
请注意,在选择一颗树后,你没有任何选择:你必须执行步骤 1,然后执行步骤 2,然后返回步骤 1,然后执行步骤 2,依此类推,直至停止。
你有两个篮子,每个篮子可以携带任何数量的水果,但你希望每个篮子只携带一种类型的水果。
用这个程序你能收集的水果树的最大总量是多少?
示例 1:
输入:[1,2,1]
输出:3
解释:我们可以收集 [1,2,1]。
示例 2:
输入:[0,1,2,2]
输出:3
解释:我们可以收集 [1,2,2]
如果我们从第一棵树开始,我们将只能收集到 [0, 1]。
示例 3:
输入:[1,2,3,2,2]
输出:4
解释:我们可以收集 [2,3,2,2]
如果我们从第一棵树开始,我们将只能收集到 [1, 2]。
示例 4:
输入:[3,3,3,1,2,1,1,2,3,3,4]
输出:5
解释:我们可以收集 [1,2,1,1,2]
如果我们从第一棵树或第八棵树开始,我们将只能收集到 4 棵水果树。
提示:
1 <= tree.length <= 40000
0 <= tree[i] < tree.length
前置知识
滑动窗口
思路
题目花里胡哨的。我们来抽象一下,就是给你一个数组, 让你「选定一个子数组, 这个子数组最多只有两种数字」,这个选定的子数组最大可以是多少。
这不就和母题 3 一样么?只不过 k 变成了固定值 2。另外由于题目要求整个窗口最多两种数字,我们用哈希表存一下不就好了吗?
❝set 是不行了的。因此我们不但需要知道几个数字在窗口, 我们还要知道每个数字出现的次数,这样才可以使用滑动窗口优化时间复杂度。
❞
代码(Python)
class Solution:
def totalFruit(self, tree: List[int]) -> int:
def atMostK(k, nums):
i = ans = 0
win = defaultdict(lambda: 0)
for j in range(len(nums)):
if win[nums[j]] == 0: k -= 1
win[nums[j]] += 1
while k < 0:
win[nums[i]] -= 1
if win[nums[i]] == 0: k += 1
i += 1
ans = max(ans, j - i + 1)
return ans
return atMostK(2, tree)
「复杂度分析」
时间复杂度:,其中 为数组长度。 空间复杂度:。
992. K 个不同整数的子数组(困难)
题目描述
给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定独立的子数组为好子数组。
(例如,[1,2,3,1,2] 中有 3 个不同的整数:1,2,以及 3。)
返回 A 中好子数组的数目。
示例 1:
输入:A = [1,2,1,2,3], K = 2
输出:7
解释:恰好由 2 个不同整数组成的子数组:[1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2].
示例 2:
输入:A = [1,2,1,3,4], K = 3
输出:3
解释:恰好由 3 个不同整数组成的子数组:[1,2,1,3], [2,1,3], [1,3,4].
提示:
1 <= A.length <= 20000
1 <= A[i] <= A.length
1 <= K <= A.length
前置知识
滑动窗口
思路
由母题 5,知:exactK = atMostK(k) - atMostK(k - 1), 因此答案便呼之欲出了。其他部分和上面的题目 904. 水果成篮 一样。
❝实际上和所有的滑动窗口题目都差不多。
❞
代码(Python)
class Solution:
def subarraysWithKDistinct(self, A, K):
return self.atMostK(A, K) - self.atMostK(A, K - 1)
def atMostK(self, A, K):
counter = collections.Counter()
res = i = 0
for j in range(len(A)):
if counter[A[j]] == 0:
K -= 1
counter[A[j]] += 1
while K < 0:
counter[A[i]] -= 1
if counter[A[i]] == 0:
K += 1
i += 1
res += j - i + 1
return res
「复杂度分析」
时间复杂度:,中 为数组长度。 空间复杂度:。
1109. 航班预订统计(中等)
题目描述
这里有 n 个航班,它们分别从 1 到 n 进行编号。
我们这儿有一份航班预订表,表中第 i 条预订记录 bookings[i] = [i, j, k] 意味着我们在从 i 到 j 的每个航班上预订了 k 个座位。
请你返回一个长度为 n 的数组 answer,按航班编号顺序返回每个航班上预订的座位数。
示例:
输入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5
输出:[10,55,45,25,25]
提示:
1 <= bookings.length <= 20000
1 <= bookings[i][0] <= bookings[i][1] <= n <= 20000
1 <= bookings[i][2] <= 10000
前置知识
前缀和
思路
这道题的题目描述不是很清楚。我简单分析一下题目:
[i, j, k] 其实代表的是 第 i 站上来了 k 个人, 一直到 第 j 站都在飞机上,到第 j + 1 就不在飞机上了。所以第 i 站到第 j 站的「每一站」都会因此多 k 个人。
理解了题目只会不难写出下面的代码。
class Solution:
def corpFlightBookings(self, bookings: List[List[int]], n: int) -> List[int]:
counter = [0] * n
for i, j, k in bookings:
while i <= j:
counter[i - 1] += k
i += 1
return counter
如上的代码复杂度太高,无法通过全部的测试用例。
「注意到里层的 while 循环是连续的数组全部加上一个数字,不难想到可以利用母题 0 的前缀和思路优化。」
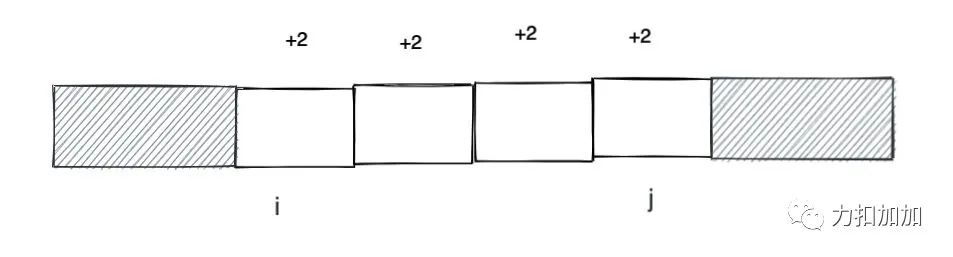
一种思路就是在 i 的位置 + k, 然后利用前缀和的技巧给 i 到 n 的元素都加上 k。但是题目需要加的是一个区间, j + 1 及其之后的元素会被多加一个 k。一个简单的技巧就是给 j + 1 的元素减去 k,这样正负就可以抵消。
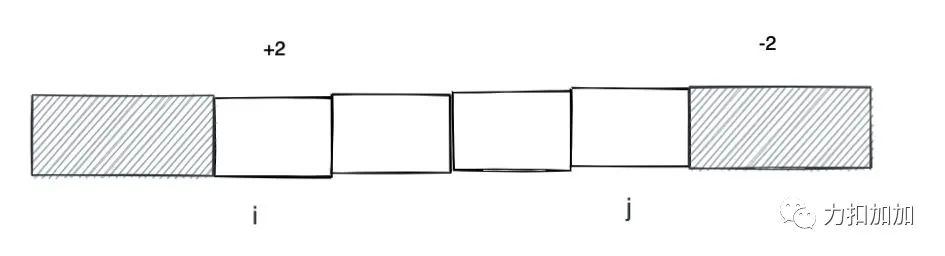
代码(Python)
class Solution:
def corpFlightBookings(self, bookings: List[List[int]], n: int) -> List[int]:
counter = [0] * (n + 1)
for i, j, k in bookings:
counter[i - 1] += k
if j < n: counter[j] -= k
for i in range(n + 1):
counter[i] += counter[i - 1]
return counter[:-1]
「复杂度分析」
时间复杂度:,中 为数组长度。 空间复杂度:。
总结
这几道题都是滑动窗口和前缀和的思路。力扣类似的题目还真不少,大家只有多留心,就会发现这个套路。
前缀和的技巧以及滑动窗口的技巧都比较固定,且有模板可套。难点就在于我怎么才能想到可以用这个技巧呢?
我这里总结了两点:
找关键字。比如题目中有连续,就应该条件反射想到滑动窗口和前缀和。比如题目求最大最小就想到动态规划和贪心等等。想到之后,就可以和题目信息对比快速排除错误的算法,找到可行解。这个思考的时间会随着你的题感增加而降低。 先写出暴力解,然后找暴力解的瓶颈, 根据瓶颈就很容易知道应该用什么数据结构和算法去优化。
最后推荐几道类似的题目, 供大家练习,一定要自己写出来才行哦。
303. 区域和检索 - 数组不可变[9] 1186.删除一次得到子数组最大和[10] 1310. 子数组异或查询[11] 1371. 每个元音包含偶数次的最长子字符串[12]
更多算法套路可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。目前已经 36K star 啦。
Reference
467. 环绕字符串中唯一的子字符串: https://leetcode-cn.com/problems/unique-substrings-in-wraparound-string/
[2]795. 区间子数组个数: https://leetcode-cn.com/problems/number-of-subarrays-with-bounded-maximum/
[3]904. 水果成篮: https://leetcode-cn.com/problems/fruit-into-baskets/
[4]992. K 个不同整数的子数组: https://leetcode-cn.com/problems/subarrays-with-k-different-integers/
[5]1109. 航班预订统计: https://leetcode-cn.com/problems/corporate-flight-bookings/
[6]前缀和: https://oi-wiki.org/basic/prefix-sum/
[7]滑动窗口专题(思路 + 模板): https://github.com/azl397985856/leetcode/blob/master/thinkings/slide-window.md
[8]1297. 子串的最大出现次数: https://github.com/azl397985856/leetcode/issues/266
[9]303. 区域和检索 - 数组不可变: https://leetcode-cn.com/problems/range-sum-query-immutable/description/
[10]1186.删除一次得到子数组最大和: https://lucifer.ren/blog/2019/12/11/leetcode-1186/
[11]1310. 子数组异或查询: https://lucifer.ren/blog/2020/01/09/1310.xor-queries-of-a-subarray/
[12]1371. 每个元音包含偶数次的最长子字符串: https://github.com/azl397985856/leetcode/blob/master/problems/1371.find-the-longest-substring-containing-vowels-in-even-counts.md
推荐阅读
?下面这个是我的新号, 专门啃算法的,需要的小伙伴记得关注一下。
如果觉得文章不错,帮忙点个在看呗