
Dockerd 资源泄露应该如何应对?
点击上方 蓝字 关注我们!
Java,Python,C/C++,Linux,PHP,Go,C#,QT,大数据,算法,软件教程,前端,简历,毕业设计等分类,资源在不断更新中... 点击领取!


1. 现象
线上 k8s 集群报警,宿主 fd 利用率超过 80%,登陆查看 dockerd 内存使用 26G
2. 排查思路
由于之前已经遇到过多次 dockerd 资源泄露的问题,先看是否是已知原因导致的,参考前面两篇
3. fd 的对端是谁?
执行 ss -anp | grep dockerd,结果如下图,可以看到和之前遇到的问题不同,第 8 列显示为 0,与之前遇到的的情况不符,无法找到对端。

4. 内存为什么泄露?
为了可以使用 pprof 分析内存泄露位置,首先为 dockerd 打开 debug 模式,需要修改 service 文件,添加如下两句
ExecReload=/bin/kill -s HUP $MAINPID
KillMode=process
同时在 /etc/docker/daemon.json 文件中添加 “debug”: true 的配置,修改完之后执行 systemctl daemon-reload 重新加载 docker 服务配置,然后执行 systemctl reload docker,重进加载 docker 配置,开启 debug 模式
dockerd 默认使用 uds 对未提供服务,为了方便我们调试,可以使用 socat 对 docker 进行端口转发,如下 sudo socat -d -d TCP-LISTEN:8080,fork,bind=0.0.0.0 UNIX:/var/run/docker.sock,意思是外部可以通过访问宿主机的 8080 端口来调用 docker api,至此一切就绪
在本地执行 go tool pprof http://ip:8080/debug/pprof/heap 查看内存使用情况,如下图
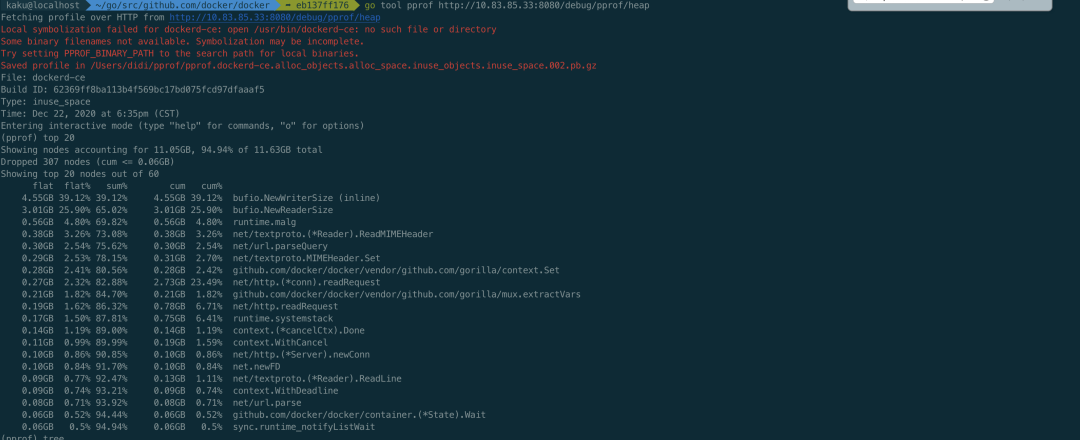
可以看到占用多的地方在 golang 自带的 bufio NewWriterSize 和 NewReaderSize 处,每次 http 调用都会都这里,也看出来有什么问题。
5. Goroutine 也泄露?
泄露位置
通过内存还是无法知道具体出问题的位置,问题不大,再看看 goroutine 的情况,直接在浏览器访问 http://ip:8080/debug/pprof/goroutine?debug=1,如下图

一共 1572822 个 goroutine,两个大头各占一半,各有 786212 个。看到这里基本就可以沿着文件行数去源码中查看了,这里我们用的 docker 18.09.2 版本,把源码切换到对应版本下,通过查看源码可以知道这两大类的 goroutine 泄露的原因,dockerd 与 containerd 相关处理流程如下图

对应上图的话,goroutine 泄露是由上面最后 docker kill 时的 wait chan close 导致的,wait 的时候会启动另一个 goroutine,每次 docker kill 都会造成这两个 goroutine 的泄露。对应代码如下
// Kill forcefully terminates a container.
func (daemon *Daemon) Kill(container *containerpkg.Container) error {
if !container.IsRunning() {
return errNotRunning(container.ID)
}
// 1. Send SIGKILL
if err := daemon.killPossiblyDeadProcess(container, int(syscall.SIGKILL)); err != nil {
// While normally we might "return err" here we're not going to
// because if we can't stop the container by this point then
// it's probably because it's already stopped. Meaning, between
// the time of the IsRunning() call above and now it stopped.
// Also, since the err return will be environment specific we can't
// look for any particular (common) error that would indicate
// that the process is already dead vs something else going wrong.
// So, instead we'll give it up to 2 more seconds to complete and if
// by that time the container is still running, then the error
// we got is probably valid and so we return it to the caller.
if isErrNoSuchProcess(err) {
return nil
}
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel()
if status := <-container.Wait(ctx, containerpkg.WaitConditionNotRunning); status.Err() != nil {
return err
}
}
// 2. Wait for the process to die, in last resort, try to kill the process directly
if err := killProcessDirectly(container); err != nil {
if isErrNoSuchProcess(err) {
return nil
}
return err
}
// Wait for exit with no timeout.
// Ignore returned status.
<-container.Wait(context.Background(), containerpkg.WaitConditionNotRunning)
return nil
}
// Wait waits until the container is in a certain state indicated by the given
// condition. A context must be used for cancelling the request, controlling
// timeouts, and avoiding goroutine leaks. Wait must be called without holding
// the state lock. Returns a channel from which the caller will receive the
// result. If the container exited on its own, the result's Err() method will
// be nil and its ExitCode() method will return the container's exit code,
// otherwise, the results Err() method will return an error indicating why the
// wait operation failed.
func (s *State) Wait(ctx context.Context, condition WaitCondition) <-chan StateStatus {
s.Lock()
defer s.Unlock()
if condition == WaitConditionNotRunning && !s.Running {
// Buffer so we can put it in the channel now.
resultC := make(chan StateStatus, 1)
// Send the current status.
resultC <- StateStatus{
exitCode: s.ExitCode(),
err: s.Err(),
}
return resultC
}
// If we are waiting only for removal, the waitStop channel should
// remain nil and block forever.
var waitStop chan struct{}
if condition < WaitConditionRemoved {
waitStop = s.waitStop
}
// Always wait for removal, just in case the container gets removed
// while it is still in a "created" state, in which case it is never
// actually stopped.
waitRemove := s.waitRemove
resultC := make(chan StateStatus)
go func() {
select {
case <-ctx.Done():
// Context timeout or cancellation.
resultC <- StateStatus{
exitCode: -1,
err: ctx.Err(),
}
return
case <-waitStop:
case <-waitRemove:
}
s.Lock()
result := StateStatus{
exitCode: s.ExitCode(),
err: s.Err(),
}
s.Unlock()
resultC <- result
}()
return resultC
}
对照 goroutine 的图片,两个 goroutine 分别走到了 Kill 最后一次的 container.Wait 处、Wait 的 select 处,正因为 Wait 方法的 select 一直不返回,导致 resultC 无数据,外面也就无法从 container.Wait 返回的 chan 中读到数据,从而导致每次 docker stop 调用阻塞两个 goroutine。
为什么泄露?
为什么 select 一直不返回呢?可以看到 select 在等三个 chan,任意一个有数据或者关闭都会返回
ctx.Done():不返回是因为最后一次调用 Wait 的时候传入的是 context.Background()。这里其实也是 dockerd 对请求的处理方式,既然客户端要删除容器,那我就等着容器删除,什么时间删除什么时间退出,只要容器没删,就一直有个 goroutine 在等待。waitStop和waitRemove:不返回是因为没收到 containerd 发来的 task exit 的信号,可以对照上图看下,在收到 task exit 后才会关闭 chan。
为什么没收到 task exit 事件?
问题逐渐明确,但还需要进一步排查为什么没有收到 task exit 的事件,两种可能
发出但没收收到:这里首先想到的是之前腾讯遇到的一个问题,也是在 18 版本的 docker 上, processEvent的 goroutine 异常退出了,导致无法接收到 containerd 发来的信号,参考这里[1]没有发出
首先看有没有收到,还是看 goroutine 的内容,如下图,可以看到处理事件的 goroutine:processEventStream 和接收事件的 goroutine:Subscribe 都存在,可以排除第一种可能

接着看第二种可能,根本没发出 task exit 事件。经过上面分析,已知存在 goroutine 泄露,且是通过 docker stop 引起的,所以可以肯定 kubelet 发起了删除容器的请求,并且是在一直尝试,要不然也不会一直泄露。那剩下唯一的问题就是找出来是在不断的删除哪个容器,又为什么删不掉。其实这个时候,聪明的你们可能已经想到容器里大概率是有 D 进程了,所有即使发送 Kill 信号容器进程无法正常退出。接下来就是去验证一下这个猜想,首先去找一下哪个容器出的问题,先看 Kubelet 日志和 docker 日志,如下
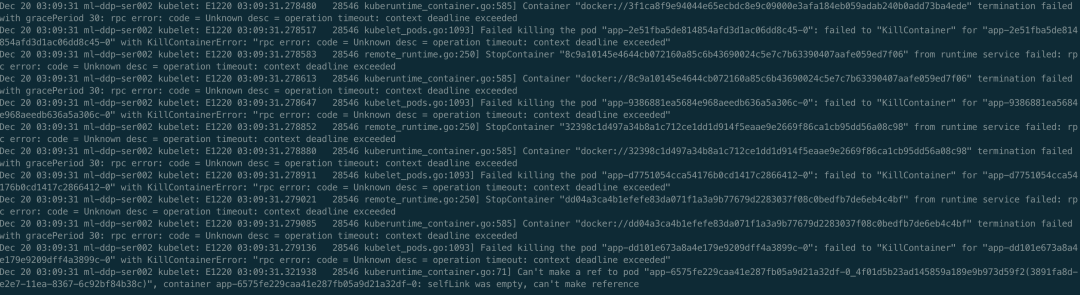
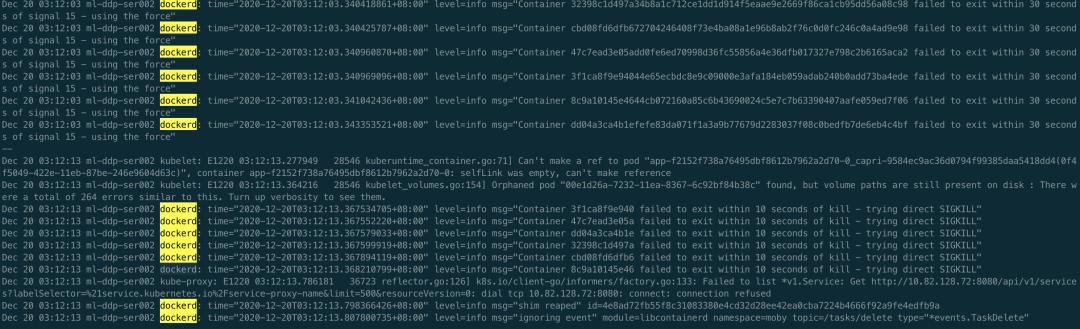
好家伙,不止一个容器删不掉。验证了确实在不断删除容器,但是删不掉,接下来看下是不是有 D 进程,如下
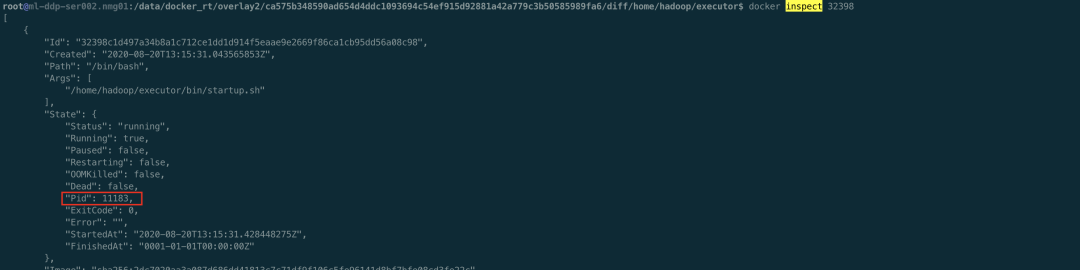


确实容器内有 D 进程了,可以去宿主上看下,ps aux | awk ‘$8=“D”',特别多的 D 进程。
总结
Kubelet 为了保证最终一致性,发现宿主上还有不应该存在的容器就会一直不断的去尝试删除,每次删除都会调用 docker stop 的 api,与 dockerd 建立一个 uds 连接,dockerd 删除容器的时候会启动一个 goroutine 通过 rpc 形式调用 containerd 来删除容器并等待最终删除完毕才返回,等待的过程中会另起一个 goroutine 来获取结果,然而 containerd 在调用 runc 去真正执行删除的时候因为容器内 D 进程,无法删除容器,导致没有发出 task exit 信号,dockerd 的两个相关的 goroutine 也就不会退出。整个过程不断重复,最终就导致 fd、内存、goroutine 一步步的泄露,系统逐渐走向不可用。
回过头来想想,其实 kubelet 本身的处理都没有问题,kubelet 是为了确保一致性,要去删除不应该存在的容器,直到容器被彻底删除,每次调用 docker api 都设置了 timeout。dockerd 的逻辑有待商榷,至少可以做一些改进,因为客户端请求时带了 timeout,且 dockerd 后端在接收到 task exit 事件后是会去做 container remove 操作的,即使当前没有 docker stop 请求。所以可以考虑把最后传入 context.Background() 的 Wait 函数调用去掉,当前面带超时的 Wait 返回后直接退出就可以,这样就不会造成资源泄露了。
往期推荐
END
若觉得文章对你有帮助,随手转发分享,也是我们继续更新的动力。
长按二维码,扫扫关注哦
✬「C语言中文网」官方公众号,关注手机阅读教程 ✬

目前收集的资料包括: Java,Python,C/C++,Linux,PHP,go,C#,QT,git/svn,人工智能,大数据,单片机,算法,小程序,易语言,安卓,ios,PPT,软件教程,前端,软件测试,简历,毕业设计,公开课 等分类,资源在不断更新中...