
如何应对消息堆积?
这篇文章,我们聊聊如何应对 RocketMQ 消息堆积。
 1 基础概念
1 基础概念 消费者在消费的过程中,消费的速度跟不上服务端的发送速度,未处理的消息会越来越多,消息出现堆积进而会造成消息消费延迟。
虽然笔者经常讲:RocketMQ 、Kafka 具备堆积的能力,但是以下场景需要重点关注消息堆积和延迟的问题:
-
业务系统上下游能力不匹配造成的持续堆积,且无法自行恢复。
-
业务系统对消息的消费实时性要求较高,即使是短暂的堆积造成的消息延迟也无法接受。
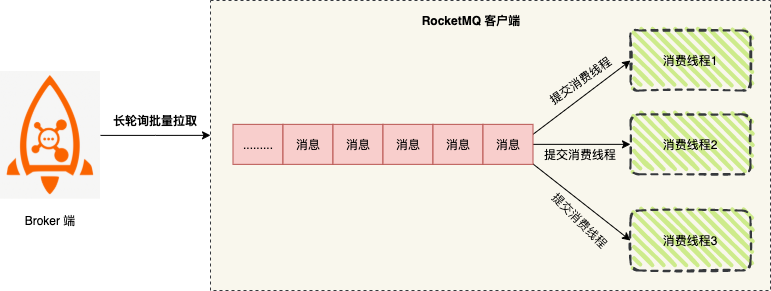
客户端使用 Push 模式 启动后,消费消息时,分为以下两个阶段:
-
阶段一:拉取消息
客户端通过长轮询批量拉取的方式从 Broker 服务端获取消息,将拉取到的消息缓存到本地缓冲队列中。
客户端批量拉取消息,常见内网环境下都会有很高的吞吐量,例如:1个单线程单分区的低规格机器(4C8GB)可以达到几万 TPS ,如果是多个分区可以达到几十万 TPS 。所以这一阶段一般不会成为消息堆积的瓶颈。
-
阶段二:消费消息
提交消费线程,客户端将本地缓存的消息提交到消费线程中,使用业务消费逻辑进行处理。
此时客户端的消费能力就完全依赖于业务逻辑的复杂度(消费耗时)和消费逻辑并发度了。如果业务处理逻辑复杂,处理单条消息耗时都较长,则整体的消息吞吐量肯定不会高,此时就会导致客户端本地缓冲队列达到上限,停止从服务端拉取消息。
通过以上客户端消费原理可以看出,消息堆积的主要瓶颈在于本地客户端的消费能力,即消费耗时和消费并发度。
想要避免和解决消息堆积问题,必须合理的控制消费耗时和消息并发度,其中消费耗时的优先级高于消费并发度,必须先保证消费耗时的合理性,再考虑消费并发度问题。
3 消费瓶颈
如果想学Java项目的,强烈推荐我的👉项目消息推送平台Austin(10K stars),可以用作毕业设计,可以用作校招,可以看看生产环境是怎么推送消息的。
仓库地址(可点击阅读原文跳转):https://gitee.com/zhongfucheng/austin
3.1 消费耗时
影响消费耗时的消费逻辑主要分为 CPU 内存计算和外部 I/O 操作,通常情况下代码中如果没有复杂的递归和循环的话,内部计算耗时相对外部 I/O 操作来说几乎可以忽略。
外部 I/O 操作通常包括如下业务逻辑:
- 读写外部数据库,例如 MySQL 数据库读写。
- 读写外部缓存等系统,例如 Redis 读写。
- 下游系统调用,例如 Dubbo 调用或者下游 HTTP 接口调用。
这类外部调用的逻辑和系统容量需要提前梳理,掌握每个调用操作预期的耗时,这样才能判断消费逻辑中I/O操作的耗时是否合理。
通常消费堆积都是由于这些下游系统出现了服务异常、容量限制导致的消费耗时增加。
例如:某业务消费逻辑中需要调用下游 Dubbo 接口 ,单次消费耗时为 20 ms,平时消息量小未出现异常。业务侧进行大促活动时,下游 Dubbo 服务未进行优化,消费单条消息的耗时增加到 200 ms,业务侧可以明显感受到消费速度大幅下跌。此时,通过提升消费并行度并不能解决问题,需要大幅提高下游 Dubbo 服务性能才行。
3.2 消费并发度
绝大部分消息消费行为都属于 IO 密集型,即可能是操作数据库,或者调用 RPC,这类消费行为的消费速度在于后端数据库或者外系统的吞吐量,通过增加消费并行度,可以提高总的消费吞吐量,但是并行度增加到一定程度,反而会下降。
所以,应用必须要设置合理的并行度。如下有几种修改消费并行度的方法:
- 同一个 ConsumerGroup 下,通过增加 Consumer 实例数量来提高并行度(需要注意的是超过订阅队列数的 Consumer 实例无效)。可以通过加机器,或者在已有机器启动多个进程的方式。
- 提高单个 Consumer 实例的消费并行线程,通过修改参数 consumeThreadMin、consumeThreadMax 实现。
当面对消息堆积问题时,我们需要明确到底哪个环节出现问题了,不要慌张,也不要贸然动手。
4.1 确认消息的消费耗时是否合理
首先,我们需要查看消费耗时,确认消息的消费耗时是否合理。查看消费耗时一般来讲有两种方式:
1、打印日志
public ConsumeConcurrentlyStatus consumeMessage(List<MessageExt> msgs, ConsumeConcurrentlyContext context) {
try {
for (MessageExt messageExt : msgs) {
long start = System.currentTimeMillis();
// TODO 业务逻辑
logger.info("MessageId:" + messageExt.getMsgId() + " costTime:" + (System.currentTimeMillis() - start));
}
return ConsumeConcurrentlyStatus.CONSUME_SUCCESS;
} catch (Exception e) {
logger.error("consumeMessage error:", e);
return ConsumeConcurrentlyStatus.RECONSUME_LATER;
}
}
2、查看消息轨迹
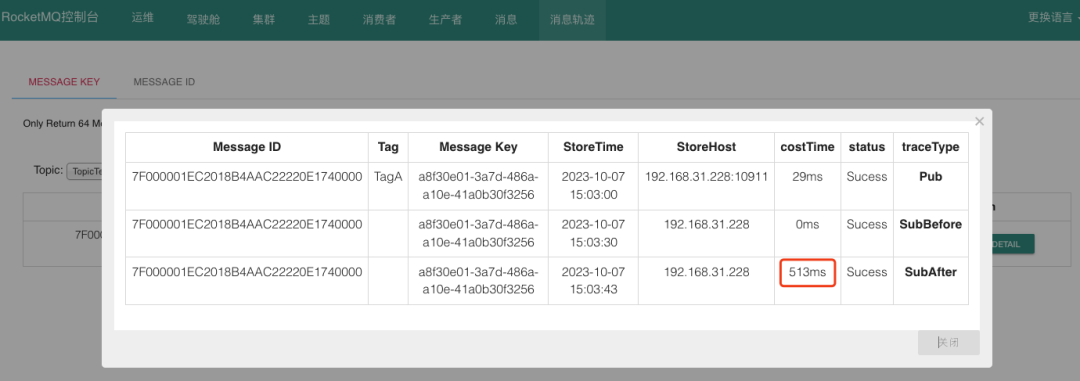
当确定好消费耗时后,可以根据耗时大小,采取不同的措施。
- 若查看到消费耗时较长,则需要查看客户端 JVM 堆栈信息排查具体业务逻辑,并优化消费逻辑。
- 若查看到消费耗时正常,则有可能是因为消费并发度不够导致消息堆积,需要逐步调大消费线程或扩容节点来解决。
4.2 查看客户端 JVM 的堆栈
假如消费耗时非常高,需要查看 Consumer 实例 JVM 的堆栈 。
-
通过
jps -m或者ps -ef | grep java命令获取当前正在运行的 Java 程序,通过启动主类即可获得应用的进程 pid ; -
通过
jstack pid > stack.log命令获取线程的堆栈。 -
执行以下命令,查看
ConsumeMessageThread的信息 。
cat stack.log | grep ConsumeMessageThread -A 10 --color
常见的异常堆栈信息如下:
-
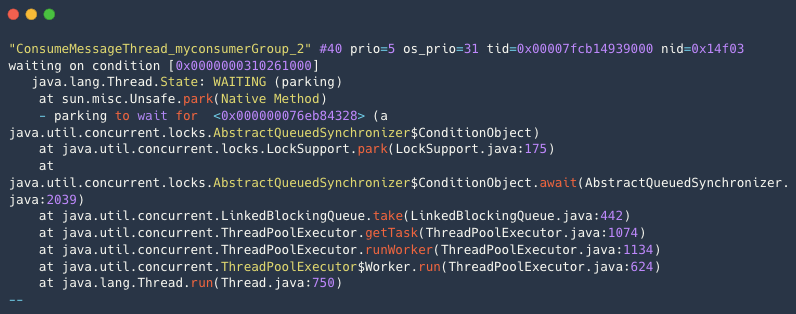
示例1:空闲无堆积的堆栈 。
消费空闲情况下消费线程都会处于
WAITING状态等待从消费任务队里中获取消息。
-
示例2:消费逻辑有抢锁休眠等待等情况 。
消费线程阻塞在内部的一个睡眠等待上,导致消费缓慢。
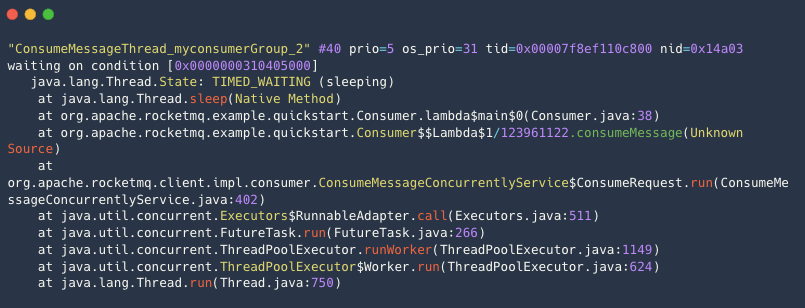
-
示例3:消费逻辑操作数据库等外部存储卡住 。
消费线程阻塞在外部的 HTTP 调用上,导致消费缓慢。
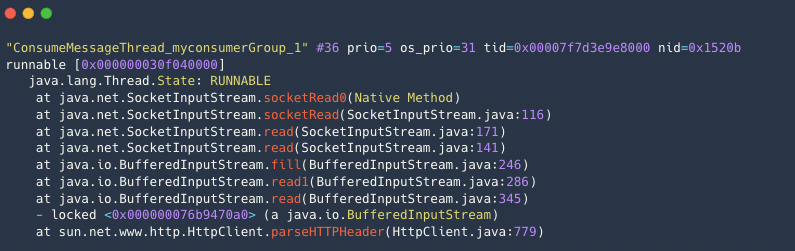
客户端使用 Push模式 启动后,消费消息时,分为以下两个阶段:拉取消息和消费消息。
客户端消费原理可以看出,消息堆积的主要瓶颈在于本地客户端的消费能力,即消费耗时和消费并发度。
首先分析消费耗时,然后根据耗时大小,采取不同的措施。
- 若查看到消费耗时较长,则查看客户端堆栈信息排查具体业务逻辑,并优化消费逻辑。
- 若查看到消费耗时正常,则有可能是因为消费并发度不够导致消息堆积,需要逐步调大消费线程或扩容节点来解决。
参考文档:
Java项目训练营
阿里云官方文档:
https://help.aliyun.com/zh/apsaramq-for-rocketmq/cloud-message-queue-rocketmq-4-x-series/use-cases/message-accumulation-and-latency#concept-2004064
我开通了 项目股东服务 ,已经有不少消息推送平台项目股东拿了阿里/vivo等大厂offer了。 我是没找到网上有跟我提供相同的服务,价格还比我低的 。
👉一对一周到的服务: 有很多人的自学能力和基础确实不太行,不知道怎么开始学习,从哪开始看起,学习项目的过程中会走很多弯路,很容易就迷茫了。付费最跟自学最主要的区别就是我的服务会更周到。我会告诉你怎么开始学这个开源项目,哪些是重点需要掌握的,如何利用最短的时间把握整个系统架构和编码的设计,把时间节省下来去做其他事情。学习经验/路线/简历编写/面试经验知无不言
👉本地直连远程服务: 生产环境的应用系统肯定会依赖各种中间件,我专门买了两台服务器已经搭建好必要的环境🙉,在本地就可以直接启动运行体验和学习,无须花额外的时间自行搭建调试。
👉细致的文档&视频: 巨细致的语雀文档11W+ 字,共106个文档,项目视频还在持续制作更新中(20个),不怕你学不会。
👉付费社群 : 优质的社群里需筛选过滤,学习氛围是很重要的,多跟同辈或前辈聊聊,会少走很多弯路💯
👉清爽干练commit: 专属股东仓库,一步一步从零复现austin,每个commit都带着文档&视频学习。
如果想获取上面的权益,可以看看👉 Java项目训练营