
C++ 如何避免内存泄露?
来源:知乎-张凯(Kyle Zhang)

【CPP开发者导读】:内存泄漏是C/C++的一个老生常谈的问题,无论是新手还是有经验的开发者都会在这个问题上栽跟头。
前言

也就是说,如果你的应用场景可以容忍不定期的 500us 的延迟,那么用 Go 都是没有问题的。如果你无法容忍 500us 的延迟,那么带 GC 功能的语言就基本无法使用了,只能选择自己管理内存的语言,例如 C++。那么由手动管理内存而带来的编程复杂度也就随之而来了。
作为 C++ 程序员,内存泄露始终是悬在头上的一颗炸弹。在过去几年的 C++ 开发过程中,由于我们采用了一些技术,我们的程序发生内存泄露的情况屈指可数。今天就在这里向大家做一个简单的介绍。
内存是如何泄露的
在 C++ 程序中,主要涉及到的内存就是『栈』和『堆』(其他部分不在本文中介绍了)。
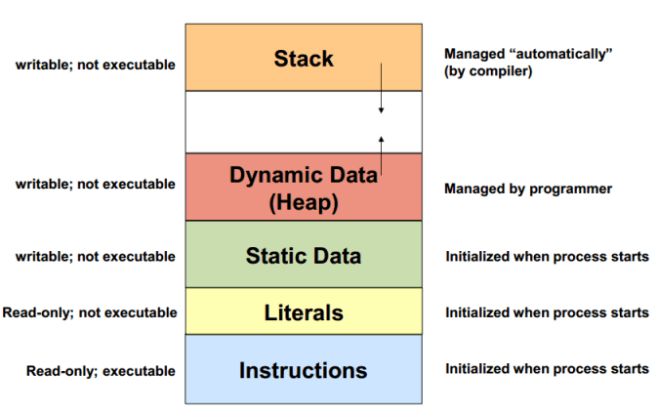
由于栈上的内存的分配和回收都是由编译器控制的,所以在栈上是不会发生内存泄露的,只会发生栈溢出(Stack Overflow),也就是分配的空间超过了规定的栈大小。
而堆上的内存是由程序直接控制的,程序可以通过 malloc/free 或 new/delete 来分配和回收内存,如果程序中通过 malloc/new 分配了一块内存,但忘记使用 free/delete 来回收内存,就发生了内存泄露。
经验 #1:尽量避免在堆上分配内存
既然只有堆上会发生内存泄露,那第一原则肯定是避免在堆上面进行内存分配,尽可能的使用栈上的内存,由编译器进行分配和回收,这样当然就不会有内存泄露了。
然而,只在栈上分配内存,在有 IO 的情况下是存在一定局限性的。
void Foo(Reuqest* req) {RequestContext ctx(req);HandleRequest(&ctx);}
如果 HandleRequest 是一个同步函数,当这个函数返回时,请求就可以被处理完成,那么显然 ctx 是可以被分配在栈上的。
但如果 HandleRequest 是一个异步函数,例如:
void HandleRequest(RequestContext* ctx, Callback cb);那么显然,ctx 是不能被分配在栈上的,因为如果 ctx 被分配在栈上,那么当 Foo 函数推出后,ctx 对象的生命周期也就结束了。而 FooCB 中显然会使用到 ctx 对象。
void HandleRequest(RequestContext* ctx, Callback cb);void Foo(Reuqest* req) {auto ctx = new RequestContext(req);HandleRequest(ctx, FooCB);}void FooCB(RequestContext* ctx) {FinishRequest(ctx);delete ctx;}
那么怎么才能避免这种情况的产生呢?引入智能指针显然是一种可行的方法,但引入 shared_ptr 往往引入了额外的性能开销,并不十分理想。
经验 #2:使用 Arena
Arena 是一种统一化管理内存生命周期的方法。所有需要在堆上分配的内存,不通过 malloc/new,而是通过 Arena 的 CreateObject 接口。同时,不需要手动的执行 free/delete,而是在 Arena 被销毁的时候,统一释放所有通过 Arena 对象申请的内存。所以,只需要确保 Arena 对象一定被销毁就可以了,而不用再关心其他对象是否有漏掉的 free/delete。这样显然降低了内存管理的复杂度。
此外,我们还可以将 Arena 的生命周期与 Request 的生命周期绑定,一个 Request 生命周期内的所有内存分配都通过 Arena 完成。这样的好处是,我们可以在构造 Arena 的时候,大概预估出处理完成这个 Request 会消耗多少内存,并提前将会使用到的内存一次性的申请完成,从而减少了在处理一个请求的过程中,分配和回收内存的次数,从而优化了性能。
我们最早看到 Arena 的思想,是在 LevelDB 的代码中。这段代码相当简单,建议大家直接阅读。
经验 #3:使用 Coroutine
Coroutine 相信大家并不陌生,那 Coroutine 的本质是什么?我认为 Coroutine 的本质,是使得一个线程中可以存在多个上下文,并可以由用户控制在多个上下文之间进行切换。而在上下文中,一个重要的组成部分,就是栈指针。使用 Coroutine,意味着我们在一个线程中,可以创造(或模拟)多个栈。
有了多个栈,意味着当我们要做一个异步处理时,不需要释放当前栈上的内存,而只需要切换到另一个栈上,就可以继续做其他的事情了,当异步处理完成时,可以再切换回到这个栈上,将这个请求处理完成。
void Foo(Reuqest* req) {RequestContext ctx(req);HandleRequest(&ctx);}void HandleRequest(RequestCtx* ctx) {SubmitAsync(ctx);Coroutine::Self()->Yield();CompleteRequest(ctx);}
这样一来,我们就可以完全抛弃在堆上申请内存,只是用栈上的内存,就可以完成请求的处理,完全不用考虑内存泄露的问题。然而这种假设过于理想,由于在栈上申请内存存在一定的限制,例如栈大小的限制,以及需要在编译是知道分配内存的大小,所以在实际场景中,我们通常会结合使用 Arena 和 Coroutine 两种技术一起使用。
有人可能会提到,想要多个栈用多个线程不就可以了?然而用多线程实现多个栈的问题在于,线程的创建和销毁的开销极大,且线程间切块,也就是在栈之间进行切换的代销需要经过操作系统,这个开销也是极大的。所以想用线程模拟多个栈的想法在实际场景中是走不通的。
关于 Coroutine 有很多开源的实现方式,大家可以在 github 上找到很多,C++20 标准也会包含 Coroutine 的支持。在 SmartX 内部,我们很早就实现了 Coroutine,并对所有异步 IO 操作进行了封装,示例可参考我们之前的一篇文章 smartx:基于 Coroutine 的异步 RPC 框架示例(C++)
这里需要强调一下,Coroutine 确实会带来一定的性能开销,通常 Coroutine 切换的开销在 20ns 以内,然而我们依然在对性能要求很苛刻的场景使用 Coroutine,一方面是因为 20ns 的性能开销是相对很小的,另一方面是因为 Coroutine 极大的降低了异步编程的复杂度,降低了内存泄露的可能性,使得编写异步程序像编写同步程序一样简单,降低了程序员心智的开销。
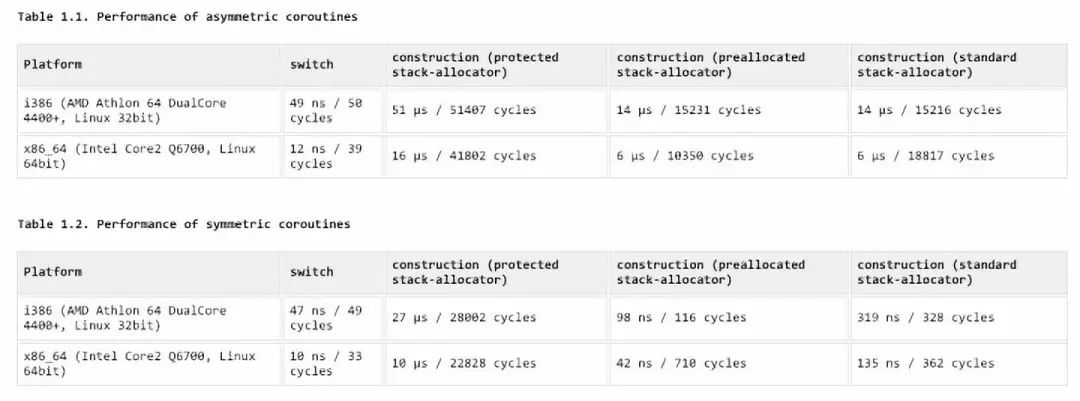
boost 实现的 coroutine 的性能测试结果
经验 #4:善用 RAII
尽管在有些场景使用了 Coroutine,但还是可能会有在堆上申请内存的需要,而此时有可能 Arena 也并不适用。在这种情况下,善用 RAII(Resource Acquisition Is Initialization)思想会帮助我们解决很多问题。
简单来说,RAII 可以帮助我们将管理堆上的内存,简化为管理栈上的内存,从而达到利用编译器自动解决内存回收问题的效果。此外,RAII 可以简化的还不仅仅是内存管理,还可以简化对资源的管理,例如 fd,锁,引用计数等等。
当我们需要在堆上分配内存时,我们可以同时在栈上面分配一个对象,让栈上面的对象对堆上面的对象进行封装,用时通过在栈对象的析构函数中释放堆内存的方式,将栈对象的生命周期和堆内存进行绑定。
unique_ptr 就是一种很典型的例子。然而 unique_ptr 管理的对象类型只能是指针,对于其他的资源,例如 fd,我们可以通过将 fd 封装成另外一个 FileHandle 对象的方式管理,也可以采用一些更通用的方式。例如,在我们内部的 C++ 基础库中实现了 Defer 类,想法类似于 Go 中 defer。
void Foo() {int fd = open();Defer d = [=]() { close(fd); }// do something with fd}
经验 #5:便于 Debug
在特定的情况下,我们难免还是要手动管理堆上的内存。然而当我们面临一个正在发生内存泄露线上程序时,我们应该怎么处理呢?
当然不是简单的『重启大法好』,毕竟重启后还是可能会产生泄露,而且最宝贵的现场也被破坏了。最佳的方式,还是利用现场进行 Debug,这就要求程序具有便于 Debug 的能力。
这里不得不提到一个经典而强大的工具 gperftools。gperftools 是 google 开源的一个工具集,包含了 tcmalloc,heap profiler,heap checker,cpu profiler 等等。gperftools 的作者之一,就是大名鼎鼎的 Sanjay Ghemawat,没错,就是与 Jeff Dean 齐名,并和他一起写 MapReduce 的那个 Sanjay。

gperftools 的一些经典用法,我们就不在这里进行介绍了,大家可以自行查看文档。而使用 gperftools 可以在不重启程序的情况下,进行内存泄露检查,这个恐怕是很少有人了解。
实际上我们 Release 版本的 C++ 程序可执行文件在编译时全部都链接了 gperftools。在 gperftools 的 heap profiler 中,提供了 HeapProfilerStart 和 HeapProfilerStop 的接口,使得我们可以在运行时启动和停止 heap profiler。同时,我们每个程序都暴露了 RPC 接口,用于接收控制命令和调试命令。在调试命令中,我们就增加了调用 HeapProfilerStart 和 HeapProfilerStop 的命令。由于链接了 tcmalloc,所以 tcmalloc 可以获取所有内存分配和回收的信息。当 heap profiler 启动后,就会定期的将程序内存分配和回收的行为 dump 到一个临时文件中。
当程序运行一段时间后,你将得到一组 heap profile 文件
profile.0001.heapprofile.0002.heap...profile.0100.heap每个 profile 文件中都包含了一段时间内,程序中内存分配和回收的记录。如果想要找到内存泄露的线索,可以通过使用
pprof --base=profile.0001.heap /usr/bin/xxx profile.0100.heap --text
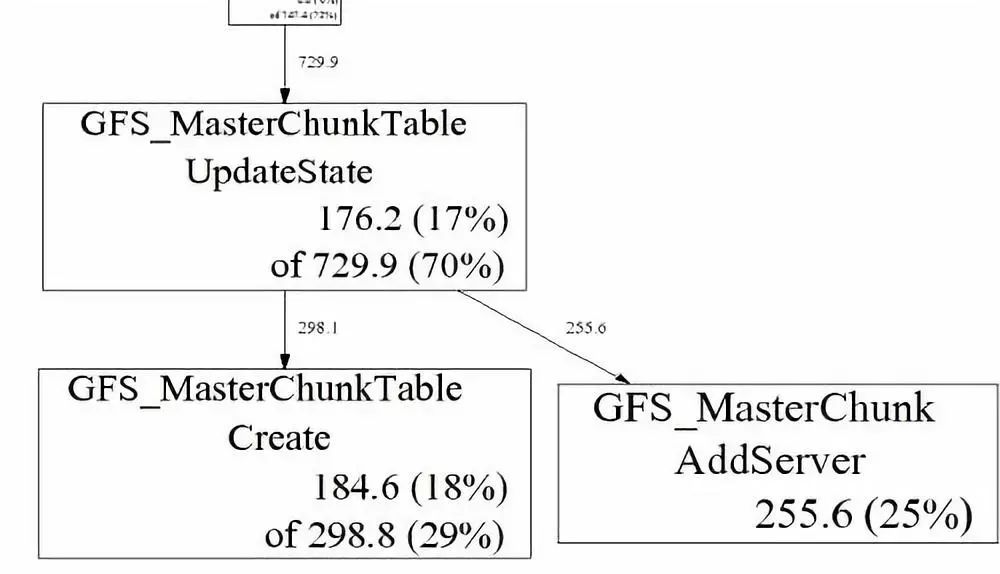
这样一来,我们就可以很方便的对线上程序的内存泄露进行 Debug 了。
写在最后
C++ 可谓是最复杂、最灵活的语言,也最容易给大家带来困扰。如果想要用好 C++,团队必须保持比较成熟的心态,团队成员必须愿意按照一定的规则来使用 C++,而不是任性的随意发挥。这样大家才能把更多精力放在业务本身,而不是编程语言的特性上。
评论