
Kubernetes工作负载资源之StatefulSet
这里将介绍Kubernetes工作负载资源中的StatefulSet

创建StatefulSet
不同于RC、RS、Deployment可以用于部署无状态的应用。而对于有状态的应用而言,其要求Pod需要具有稳定的、唯一的网标识符,稳定的、持久的存储。这对于RS、Deployment而言是无法满足的。为此K8s中提供了一种专用于有状态应用的StatefulSet,其可以保证当一个有状态的Pod被删除后(比如人工手动删除),K8s则会创建一个与之完全一致的Pod出来,包括Pod名称、网络主机名、存储等
对于StatefulSet的Pod而言,即使其被重新调度到别的节点,其也必须挂载旧Pod此前所使用的存储。为此Pod所使用的必须是PV持久卷,且需要与Pod解耦。故需要将每个Pod绑定各自的PVC持久卷声明。为此在StatefulSet的定义中,我们需设置PVC模板即可。以便StatefulSet能够按照PVC模板创建出与Pod数量相同的PVC。而PV持久卷则既可以是管理员提前创建的,也可以是动态制备的
这里我们先手动创建两个PV
# 创建持久卷PV
apiVersion: v1
kind: PersistentVolume
metadata:
# PV卷名称
name: pv-a
spec:
# 容量
capacity:
# 存储大小: 30MB
storage: 30Mi
# 该卷支持的访问模式
accessModes:
- ReadWriteOnce # RWO, 该卷可以被一个节点以读写方式挂载
- ReadOnlyMany # ROX, 该卷可以被多个节点以只读方式挂载
# 回收策略: 保留
persistentVolumeReclaimPolicy: Retain
# 该持久卷的实际存储类型: 此处使用HostPath类型卷
hostPath:
path: /tmp/PvA
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv-b
spec:
capacity:
storage: 30Mi
accessModes:
- ReadWriteOnce
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /tmp/PvB
---
效果如下所示

对于StatefulSet而言,其还需要提前创建一个Headless Service
# 创建 Headless Service
apiVersion: v1
kind: Service
metadata:
name: my-kubia-headless-service
spec:
type: ClusterIP
# 对于ClusterIP类型服务而言, 当clusterIP为None时表示这是一个Headless Service
clusterIP: None
selector:
app: my-kubia
ports:
- port: 12121 # 服务监听端口
targetPort: 8080 # 服务将请求转发到Pod的目标端口
现在我们开始创建StatefulSet,配置文件如下所示
# 创建 StatefulSet
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: my-statefulset-kubia
spec:
# 标签选择器
selector:
matchLabels:
app: my-kubia
# 设定Headless Service的服务名称
serviceName: my-kubia-headless-service
# Pod的副本数
replicas: 2
# Pod模板
template:
metadata:
labels:
# 标签信息
app: my-kubia
spec:
containers:
- name: my-app-kubia
image: luksa/kubia-pet
# 仅用于展示容器所使用的端口
ports:
- containerPort: 8080
protocol: TCP
volumeMounts:
# 将名为my-volume-data的卷挂载到容器指定路径/var/data上
- name: my-volume-data
mountPath: /var/data
# PVC模板
volumeClaimTemplates:
- metadata:
# 卷的名称
name: my-volume-data
spec:
# 禁止使用动态制备的卷, 即使用静态制备
storageClassName: ""
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Mi
效果如下所示,两个Pod分别绑定各自的PVC。而这两个PVC进一步地分别使用了我们之前创建的两个PV。与此同时,对于StatefulSet创建的Pod而言,其名称命名规则是StatefulSet名称加索引编号

测试
该应用支持通过POST请求将数据存储到容器内的/var/data路径下,通过GET请求获取容器内的/var/data路径下的数据内容。这里我们先启动一个代理,然后利用API服务器访问指定的Pod。效果如下所示,符合预期
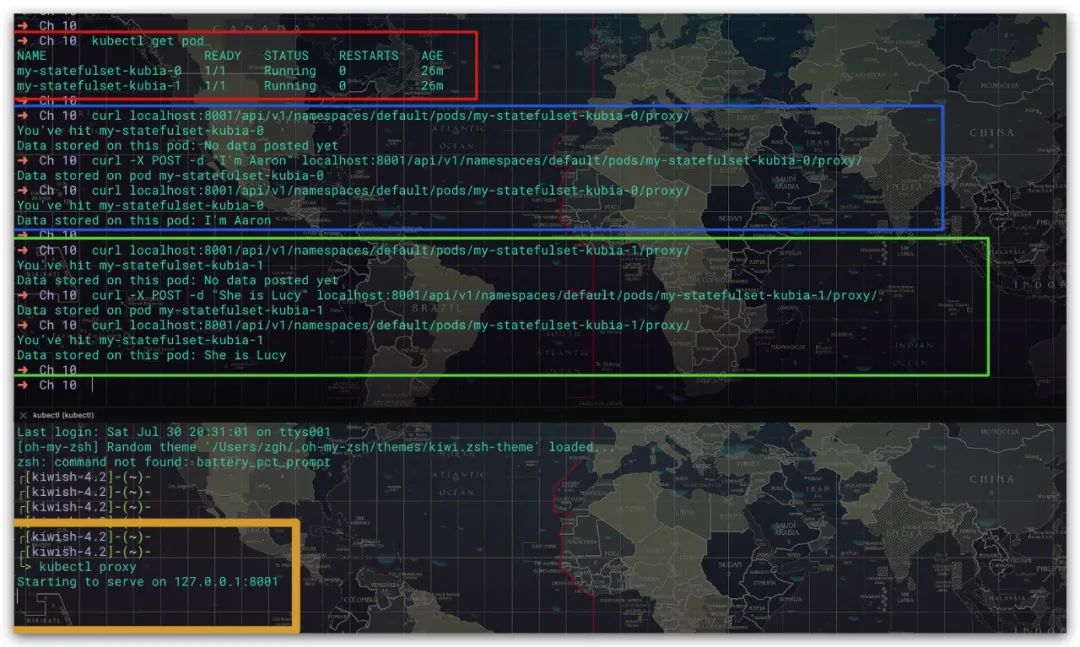
对于包含N个Pod副本的StatefulSet而言,其会按照索引顺序依次创建N个Pod。即先创建索引为0的Pod,再创建索引为1的Pod,再创建索引为2的Pod,以此类推。而当我们进行缩容的时候,则它们是按照索引逆序的顺序依次终止Pod的,即顺序为N-1、N-2、N-3、...、2、1、0。现在我们将该StatefulSet的Pod副本数缩容为1
# 将StatefulSet的Pod副本数调整为指定数量
kubectl scale statefulset my-statefulset-kubia --replicas=1
# 将指定名称的StatefulSet的Pod副本数调整为指定数量
kubectl scale statefulset <StatefulSet的名称> --replicas=<Pod的副本数>
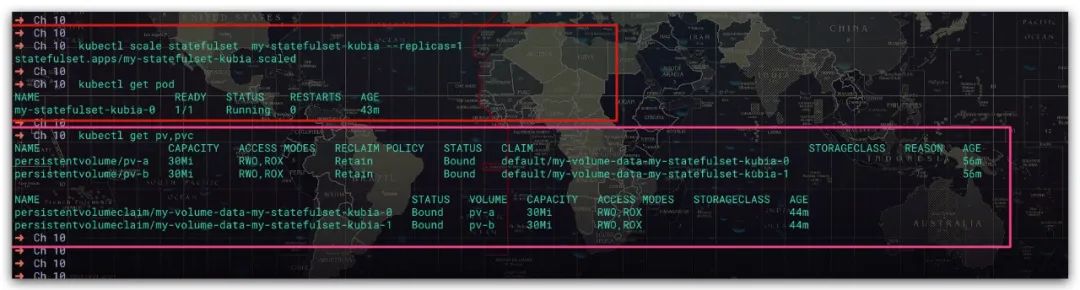
效果如下所示。而且即使缩容了,索引1的Pod所使用的PVC、PV也依然会被保留。这样当你再次扩容时,其依然会创建一个索引为1的Pod,且依然会绑定此前索引为1的Pod所使用的PVC。无论这个新Pod会被调度哪个集群节点当中
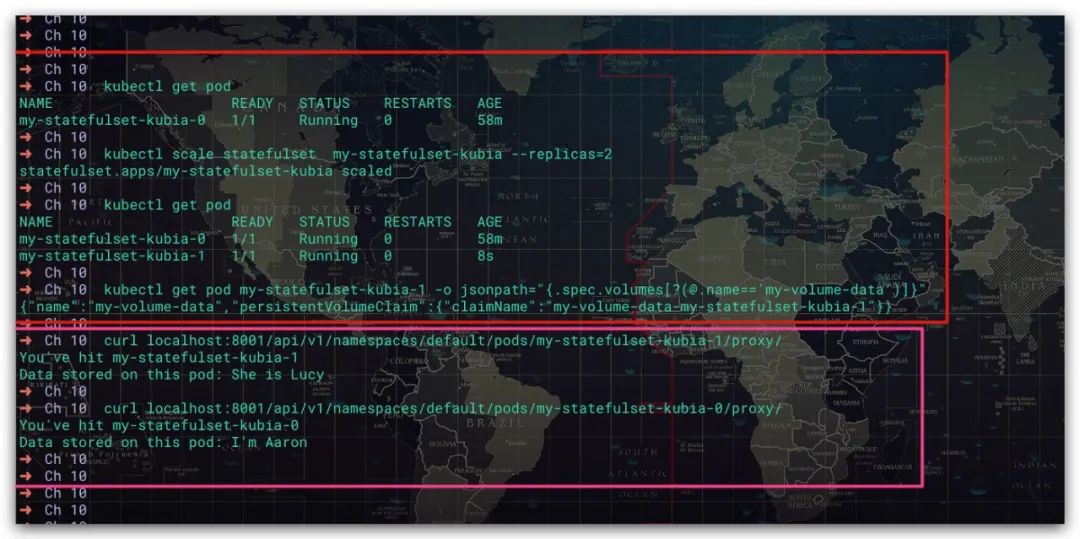
现在我们重新将该StatefulSet扩容到2。可以看到索引为1的Pod再次使用了之前的PVC。且访问该Pod可以查询到此前的数据,进一步验证了这个结果
查询SRV记录
现在我们创建一个Pod演示如何用于获取该StatefulSet中全部Pod的网络信息
# 创建一个包含dig、ping命令的Pod
apiVersion: v1
kind: Pod
metadata:
# Pod 名称
name: my-dnsutils
spec:
# 容器信息
containers:
- name: my-dnsutils
# 镜像信息
image: tutum/dnsutils
# 设置容器启动时执行的命令、参数
command: # 该命令可以保持容器一直运行, 而不会结束退出
- sleep
- infinity
在创建StatefulSet时我们指定了一个Headless Service。其目的在于该Headless Service会创建出相应的SRV记录。通过SRV记录我们就可以知道来该服务对应Pod的域名、IP、端口等信息了。其中该StatefulSet的域名规则一般如下所示
# StatefulSet的域名规则
<Headless Service的服务名称>.<命名空间的名称>.svc.cluster.local
# 通过dig srv命令查询SRV记录
dig srv my-kubia-headless-service.default.svc.cluster.local
效果如下所示。这样我们就可以实现获取StatefulSet中全部Pod的网络地址了

参考文献
Kubernetes in Action中文版 Marko Luksa著 深入剖析Kubernetes 张磊著