
Kubernetes Controller 如何管理资源?

一、Introduction
起因:工作上要重构一个现有的组件管理工具,要求实现全生命周期管理,还有上下游解耦,我心里一想这不就是 k8s controller 嘛!所以决定在动手前先学习一下 k8s 的先进理念。
此文就是通过对代码的简单分析,以及一些经验总结,来描述 k8s controller 管理资源的主要流程。
二、Concepts
resource: 资源,k8s 中定义的每一个实例都是一个资源,比如一个 rs、一个 deployment。资源有不同的 kind,比如 rs、deployment。资源间存在上下游关系。
注意:下文中提到的所有“资源”,都是指 k8s 中抽象的资源声明,而不是指 CPU、存储等真实的物理资源。
高度抽象 k8s 的话其实就三大件:
apiserver: 负责存储资源,并且提供查询、修改资源的接口 controller: 负责管理本级和下级资源。比如 deploymentController 就负责管理 deployment 资源 和下一级的 rs 资源。 kubelet: 安装在 node 节点上,负责部署资源
controller 和 kubelet 都只和 apiserver 通讯。controller 不断监听本级资源,然后修改下级资源的声明。kubelet 查询当前 node 所应部署的资源,然后执行清理和部署。
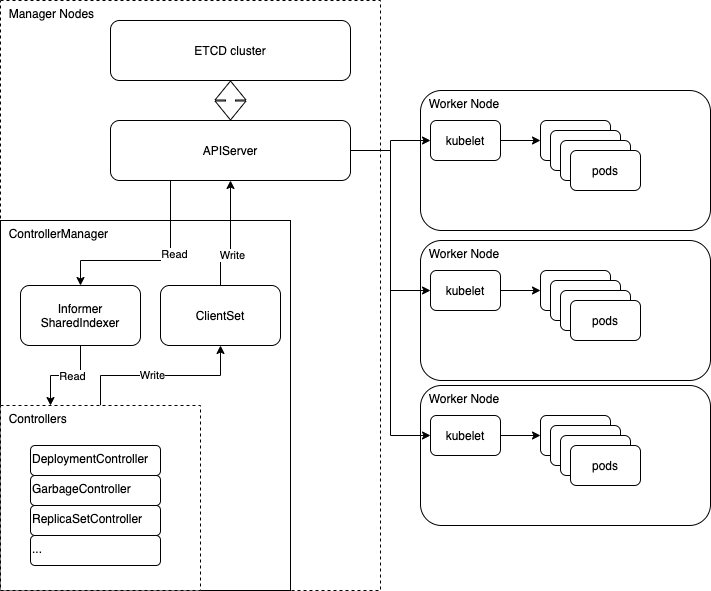
1、术语
metadata: 每一个资源都有的元数据,包括 label、owner、uid 等UID: 每一个被创建(提交给 apiserver)的资源都有一个全局唯一的 UUID。label: 每个资源都要定义的标签selector: 父资源通过 labelSelector 查询归其管理的子资源。不允许指定空 selector(全匹配)。owner: 子资源维护一个 owner UID 的列表 OwnerReferences, 指向其父级资源。列表中第一个有效的指针会被视为生效的父资源。selector 实际上只是一个 adoption 的机制, 真实起作用的父子级关系是靠 owner 来维持的, 而且 owner 优先级高于 selector。replicas: 副本数,pod 数 父/子资源的相关: orphan: 没有 owner 的资源(需要被 adopt 或 GC) adopt: 将 orphan 纳入某个资源的管理(成为其 owner) match: 父子资源的 label/selector 匹配 release: 子资源的 label 不再匹配父资源的 selector,将其释放 RS 相关: saturated: 饱和,意指某个资源的 replicas 已符合要求 surge: rs 的 replicas 不能超过 spec.replicas + surge proportion: 每轮 rolling 时,rs 的变化量(小于 maxSurge) fraction: scale 时 rs 期望的变化量(可能大于 maxSurge)
三、Controller
sample-controller@a40ea2c/controller.go kubernetes@59c0523b/pkg/controller/deployment/deployment_controller.go kubernetes@59c0523b/pkg/controller/controller_ref_manager.go
控制器,负责管理自己所对应的资源(resource),并创建下一级资源,拿 deployment 来说:
用户创建 deployment 资源 deploymentController 监听到 deployment 资源,然后创建 rs 资源 rsController 监听到 rs 资源,然后创建 pod 资源 调度器(scheduler)监听到 pod 资源,将其与 node 资源建立关联
(node 资源是 kubelet 安装后上报注册的)
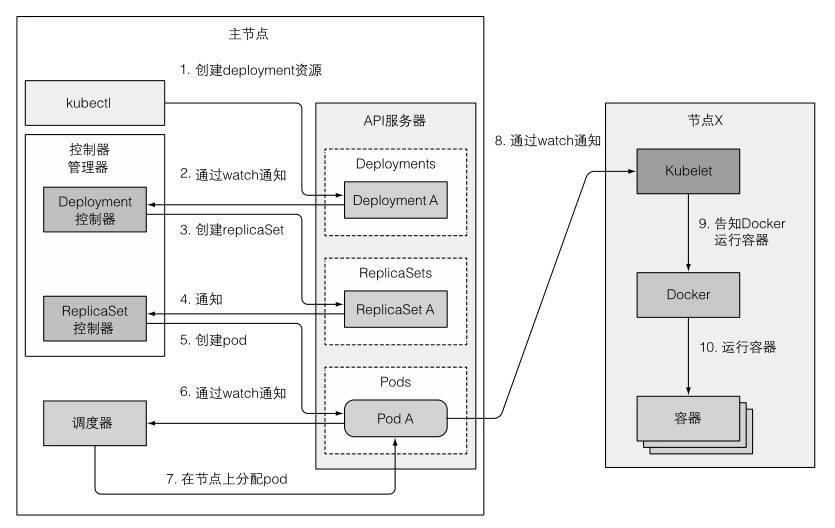
理想中,每一层管理器只管理本级和子两层资源。但因为每一个资源都是被上层创建的, 所以实际上每一层资源都对下层资源的定义有完全的了解,即有一个由下至上的强耦合关系。
比如 A -> B -> C -> D 这样的生成链,A 当然是知道 D 资源的全部定义的, 所以从理论上说,A 是可以去获取 D 的。但是需要注意的是,如果出现了跨级的操作,A 也只能只读的获取 D,而不要对 D 有任何改动, 因为跨级修改数据的话会干扰下游的控制器。
k8s 中所有的控制器都在同一个进程(controller-manager)中启动, 然后以 goroutine 的形式启动各个不同的 controller。所有的 contorller 共享同一个 informer,不过可以注册不同的 filter 和 handler, 监听自己负责的资源的事件。
(informer 是对 apiserver 的封装,是 controller 查询、订阅资源消息的组件,后文有介绍)
注:如果是用户自定义 controller(CRD)的话,需要以单独进程的形式启动,需要自己另行实例化一套 informer, 不过相关代码在 client-go 这一项目中都做了封装,编写起来并不会很复杂。
控制器的核心代码可以概括为:
for {
for {
// 从 informer 中取出订阅的资源消息
key, empty := queue.Get()
if empty {
break
}
defer queue.Done(key)
// 处理这一消息:更新子资源的声明,使其匹配父资源的要求。
// 所有的 controller 中,这一函数都被命名为 `syncHandler`。
syncHandler(key)
}
// 消息队列被消费殆尽,等待下一轮运行
time.sleep(time.Second)
}
通过 informer(indexer)监听资源事件,事件的格式是字符串 / 控制器通过 namespace 和 name 去查询自己负责的资源和下级资源 比对当前资源声明的状态和下级资源可用的状态是否匹配,并通过增删改让下级资源匹配上级声明。比如 deployments 控制器就查询 deployment 资源和 rs 资源,并检验其中的 replicas 副本数是否匹配。
controller 内包含几个核心属性/方法:
informer: sharedIndexer,用于获取资源的消息,支持注册 Add/Update/Delete 事件触发,或者调用 lister遍历。clientset: apiserver 的客户端,用来对资源进行增删改。 syncHandler: 执行核心逻辑代码(更新子资源的声明,使其匹配父资源的要求)。
1、syncHandler
syncHandler 像是一个约定,所有的 controller 内执行核心逻辑的函数都叫这个名字。该函数负责处理收到的资源消息,比如更新子资源的声明,使其匹配父资源的要求。
以 deploymentController 为例,当收到一个事件消息,syncHandler 被调用后:
注:
de: 触发事件的某个 deployment 资源dc: deploymentController 控制器自己rs: replicaset,deployment 对应的 replicaset 子资源
注:事件是一个字符串,形如 namespace/name,代表触发事件的资源的名称以及所在的 namespace。因为事件只是个名字,所以 syncHandler 需要自己去把当前触发的资源及其子资源查询出来。这里面涉及很多查询和遍历,不过这些查询都不会真实的调用 apiserver,而是在 informer 的内存存储里完成的。
graph TD
A1[将 key 解析为 namespace 和 name] --> A2[查询 de]
A2 --> A3[查询关联子资源 rs]
A3 --> A31{de 是否 paused}
A31 --> |yes| A32[调用 dc.sync 部署 rs]
A31 --> |no| A4{是否设置了 rollback}
A4 --> |yes| A41[按照 annotation 设置执行 rollback]
A4 --> |no| A5[rs 是否匹配 de 声明]
A5 --> |no| A32
A5 --> |yes| A6{de.spec.strategy.type}
A6 --> |recreate| A61[dc.rolloutRecreate]
A6 --> |rolling| A62[dc.rolloutRolling]
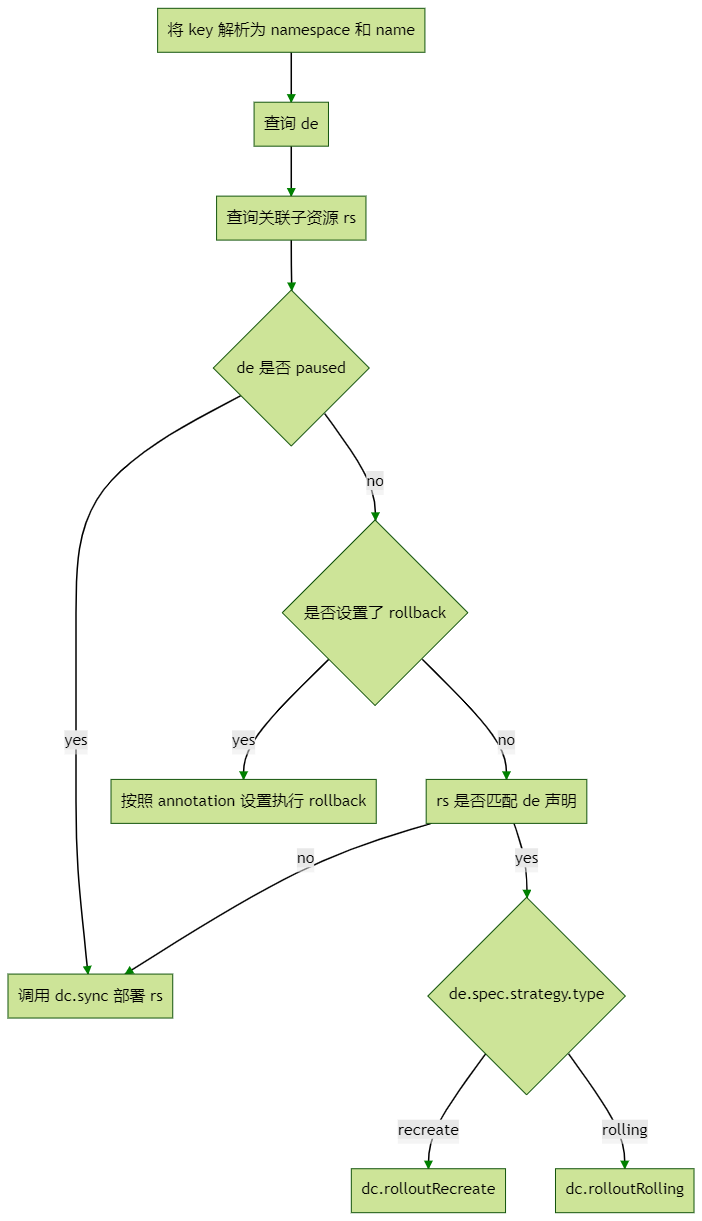
查询关联子资源
kubernetes@59c0523b/pkg/controller/deployment/deployment_controller.go:getReplicaSetsForDeployment
k8s 中,资源间可以有上下级(父子)关系。
理论上 每一个 controller 都负责创建当前资源和子资源,父资源通过 labelSelector 查询应该匹配的子资源。
一个 deployment 的定义:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
上文中讲到 syncHandler 的时候,提到需要“查询关联子资源”。其实这一步骤很复杂,不仅仅是查询,还包含对现有子资源进行同步(修改)的操作。简而言之,这一步骤实际上做的是通过对 owner、label 的比对,确认并更新当前真实的父子资源关系。
对用户呈现的资源关联是依靠 label/selector。但实际上 k8s 内部使用的是 owner 指针。(owner 指针是资源 metadata 内用来标记其父资源的 OwnerReferences)。
查询匹配子资源的方法是:
遍历 namespace 内所有对应类型的子资源 (比如 deployment controller 就会遍历所有的 rs) 匹配校验 owner 和 label
(父是当前操作的资源,子是查询出的子资源)
还是用 deployment 举例,比如此时收到了一个 deployment 事件,需要查询出该 de 匹配的所有 rs:
graph LR
A(遍历 namespace 内所有 rs) --> A1{子.owner == nil}
A1 --> |false| A2{子.owner == 父.uid}
A2 --> |false| A21[skip]
A2 --> |true| A3{labels matched}
A3 --> |true| A5
A3 --> |false| A31[release]
A1 --> |true| A4{labels matched}
A4 --> |false| A21
A4 --> |true| A41[adopt]
A41 --> A5[标记为父子]
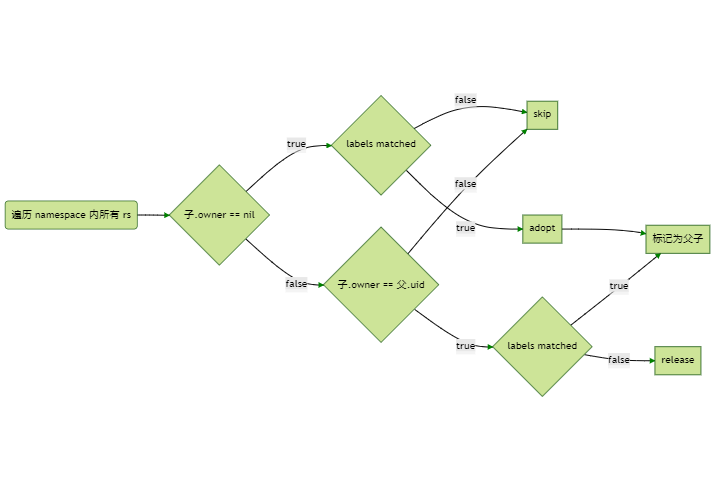
如上图所示,其实只有两个 case 下,rs 会被视为是 de 的子资源:
rs owner 指向 de,且 labels 匹配 rs owner 为空,且 labels 匹配
注意:如果 rs owner 指向了其他父资源,即使 label 匹配,也不会被视为当前 de 的子资源。
dc.sync
kubernetes@59c0523b/pkg/controller/deployment/sync.go:sync
这是 deployment controller 中执行“检查和子资源,令其匹配父资源声明”的一步。准确的说:
dc.sync: 检查子资源是否符合父资源声明 dc.scale: 操作更新子资源,使其符合父资源声明
graph TD
A1[查询 de 下所有旧的 rs] --> A2{当前 rs 是否符合 de}
A2 --> |no| A21[newRS = nil]
A2 --> |yes| A22[NewRS = 当前 rs]
A22 --> A23[将 de 的 metadata 拷贝给 newRS]
A23 --> A231[newRS.revision=maxOldRevision+1]
A231 --> A3[调用 dc.scale]
A21 --> A33
A3 --> A31{是否有 active/latest rs}
A31 --> |yes| A311[dc.scaleReplicaSet 扩缩容]
A31 --> |no| A32{newRS 是否已饱和}
A32 --> |yes|A321[把所有 oldRS 清零]
A32 --> |no|A33{de 是否允许 rolling}
A33 --> |no|A331[return]
A33 --> |yes|A34[执行滚动更新]
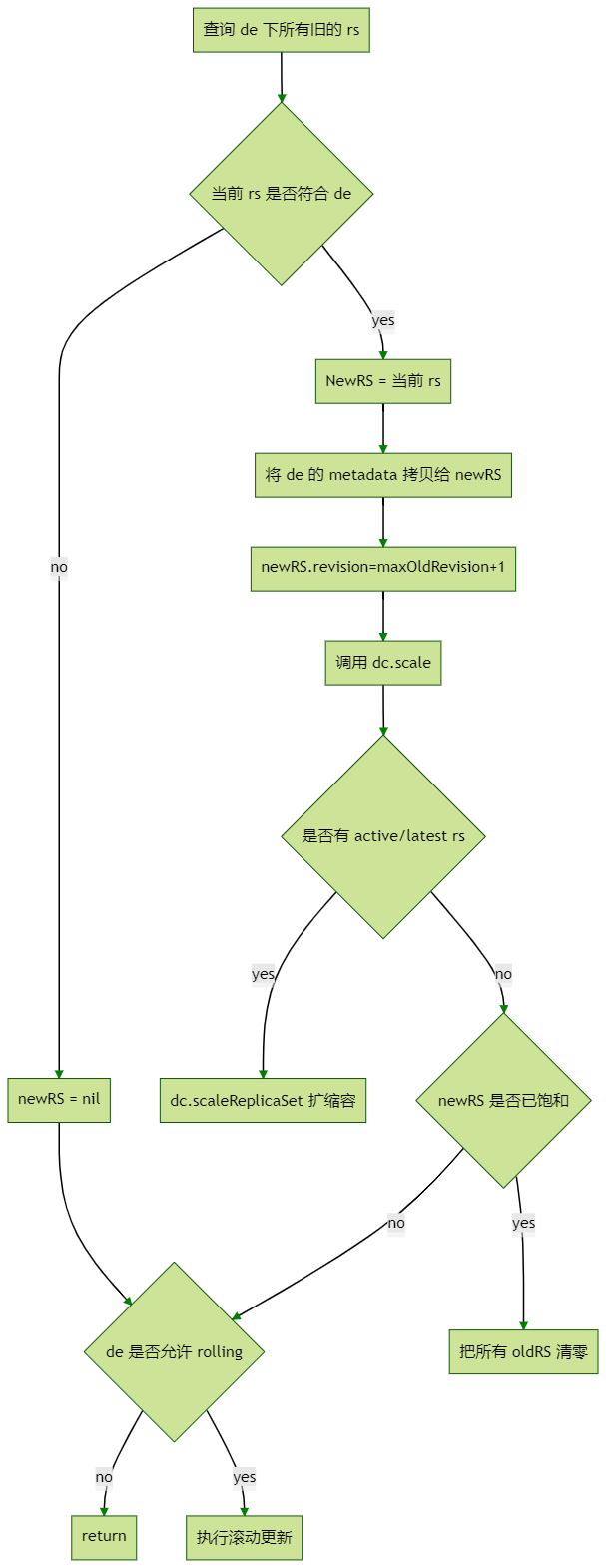
滚动更新的流程为:
(if deploymentutil.IsRollingUpdate(deployment) {...} 内的大量代码,实际做的事情就是按照 deployment 的要求更新 rs 的 replicas 数。不过每次变更都涉及到对 rs 和 deployment 的 maxSurge 的检查,所以代码较为复杂。)
计算所有 RS replicas 总和 allRSsReplicas。计算滚动升级过程中最多允许出现的副本数 allowedSize。allowedSize = de.Spec.Replicas + maxSurgedeploymentReplicasToAdd = allowedSize - allRSsReplicas遍历所有当前 rs,计算每一个 rs 的 replicas 变化量(proportion), 计算的过程中需要做多次检查,不能溢出 rs 和 deployment 的 maxSurge。 更新所有 rs 的 replicas,然后调用 dc.scaleReplicaSet提交更改。
四、Object
apimachinery@v0.0.0-20210708014216-0dafcb48b31e/pkg/apis/meta/v1/meta.go apimachinery@v0.0.0-20210708014216-0dafcb48b31e/pkg/apis/meta/v1/types.go
ObjectMeta 定义了 k8s 中资源对象的标准方法。
虽然 resource 定义里是通过 labelSelector 建立从上到下的关联, 但其实内部实现的引用链是从下到上的。每一个资源都会保存一个 Owner UID 的 slice。
每个资源的 metadata 中都有一个 ownerReferences 列表,保存了其父资源(遍历时遇到的第一个有效的资源会被认为是其父资源)。
type ObjectMeta struct {
OwnerReferences []OwnerReference `json:"ownerReferences,omitempty" patchStrategy:"merge" patchMergeKey:"uid" protobuf:"bytes,13,rep,name=ownerReferences"`
}
判断 owner 靠的是比对资源的 UID
func IsControlledBy(obj Object, owner Object) bool {
ref := GetControllerOfNoCopy(obj)
if ref == nil {
return false
}
// 猜测:UID 是任何资源在 apiserver 注册的时候,由 k8s 生成的 uuid
return ref.UID == owner.GetUID()
}
五、Informer
A deep dive into Kubernetes controllers[1] client-go@v0.0.0-20210708094636-69e00b04ba4c/informers/factory.go
Informer 也经历了两代演进,从最早各管各的 Informer,到后来统一监听,各自 filter 的 sharedInformer。
所有的 controller 都在一个 controller-manager 进程内,所以完全可以共享同一个 informer, 不同的 controller 注册不同的 filter(kind、labelSelector),来订阅自己需要的消息。
简而言之,现在的 sharedIndexer,就是一个统一的消息订阅器,而且内部还维护了一个资源存储,对外提供可过滤的消息分发和资源查询功能。
sharedIndexer 和 sharedInformer 的区别就是多了个 threadsafe 的 map 存储,用来存 shared resource object。
现在的 informer 中由几个主要的组件构成:
reflecter:查询器,负责从 apiserver 定期轮询资源,更新 informer 的 store。 store: informer 内部对资源的存储,用来提供 lister 遍历等查询操作。 queue:支持 controller 的事件订阅。
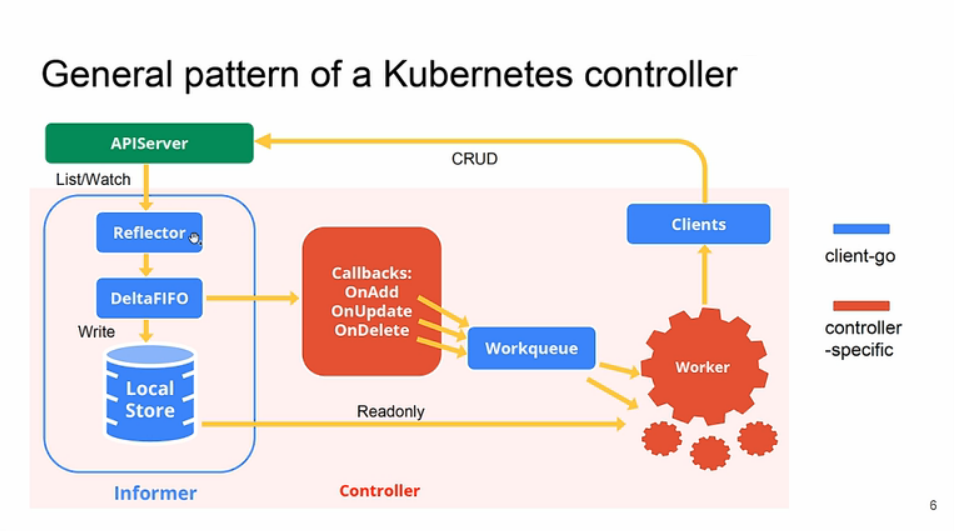
各个 controller 的订阅和查询绝大部分都在 sharedIndexer 的内存内完成,提高资源利用率和效率。
一般 controller 的消息来源就通过两种方式:
lister: controller 注册监听特定类型的资源事件,事件格式是字符串, / handler: controller 通过 informer 的 AddEventHandler方法注册Add/Update/Delete事件的处理函数。
这里有个值得注意的地方是,资源事件的格式是字符串,形如
那么某个版本的 controller 拿到这个信息后,并不知道查询出来的资源是否匹配自己的版本,也许会查出一个很旧版本的资源。
所以 controller 对于资源必须是向后兼容的,新版本的 controller 必须要能够处理旧版资源。这样的话,只需要保证运行的是最新版的 controller 就行了。
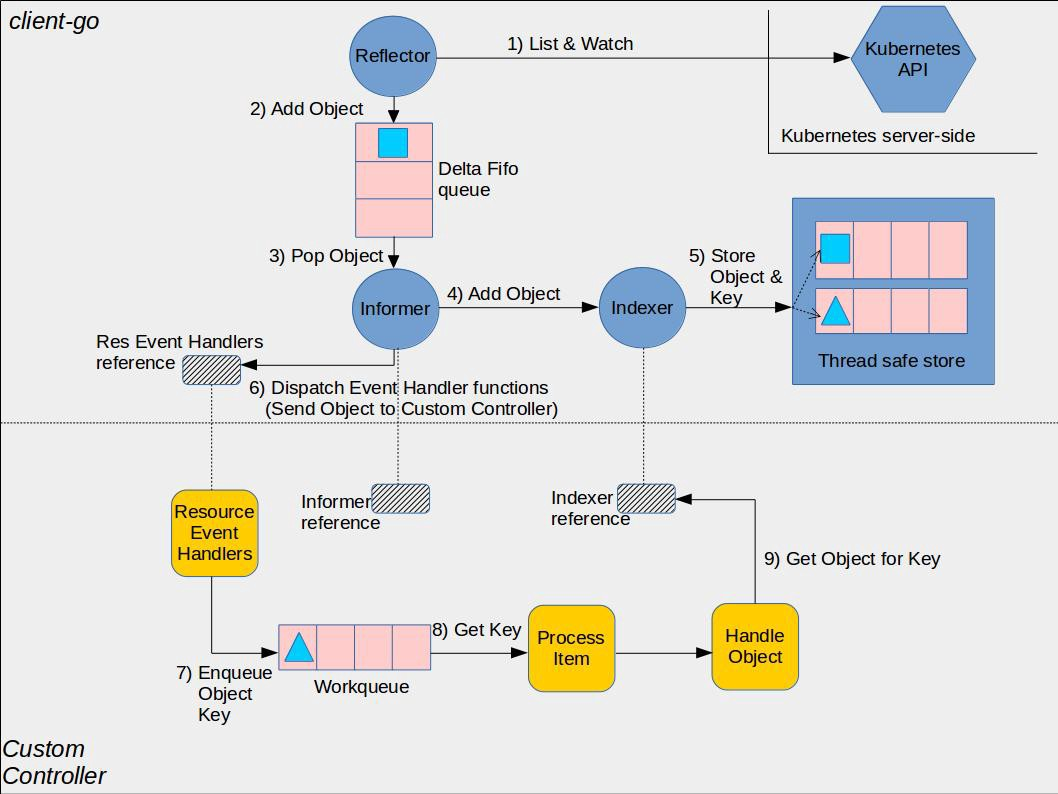
1、Queue
controller 内有大量的队列,最重要的就是注册到 informer 的三个 add/update/delete 队列。
RateLimitingQueue
client-go@v0.0.0-20210708094636-69e00b04ba4c/util/workqueue/rate_limiting_queue.go
实际使用的是队列类型是 RateLimitingQueue,继承于 Queue。
Queue
client-go@v0.0.0-20210708094636-69e00b04ba4c/util/workqueue/queue.go
type Interface interface {
// Add 增加任务,可能是增加新任务,可能是处理失败了重新放入
//
// 调用 Add 时,t 直接插入 dirty。然后会判断一下 processing,
// 是否存在于 processing ? 返回 : 放入 queue
Add(item interface{})
Len() int
Get() (item interface{}, shutdown bool)
Done(item interface{})
ShutDown()
ShuttingDown() bool
}
type Type struct {
// queue 所有未被处理的任务
queue []t
// dirty 所有待处理的任务
//
// 从定义上看和 queue 有点相似,可以理解为 queue 的缓冲区。
// 比如调用 Add 时,如果 t 存在于 processing,就只会插入 dirty,不会插入 queue,
// 这种情况表明外部程序处理失败了,所以再次插入了 t。
dirty set
// processing 正在被处理的任务
//
// 一个正在被处理的 t 应该从 queue 移除,然后添加到 processing。
//
// 如果 t 处理失败需要重新处理,那么这个 t 会被再次放入 dirty。
// 所以调用 Done 从 processing 移除 t 的时候需要同步检查一下 dirty,
// 如果 t 存在于 dirty,则将其再次放入 queue。
processing set
cond *sync.Cond
shuttingDown bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.Clock
}
队列传递的资源事件是以字符串来表示的,格式形如 namespace/name。
正因为资源是字符串来表示,这导致了很多问题。其中对于队列的一个问题就是:没法为事件设置状态,标记其是否已完成。为了实现这个状态,queue 中通过 queue、dirty、processing 三个集合来表示。具体实现可以参考上面的注释和代码。
另一个问题就是资源中没有包含版本信息。
那么某个版本的 controller 拿到这个信息后,并不知道查询出来的资源是否匹配自己的版本,也许会查出一个很旧版本的资源。
所以 controller 对于资源必须是向后兼容的,新版本的 controller 必须要能够处理旧版资源。这样的话,只需要保证运行的是最新版的 controller 就行了。
六、GC
Garbage Collection[2] Using Finalizers to Control Deletion[3] kubernetes@59c0523b/pkg/controller/garbagecollector/garbagecollector.go
1、Concepts
我看到 GC 的第一印象是一个像语言 runtime 里的回收资源的自动垃圾收集器。但其实 k8s 里的 GC 的工作相对比较简单,更像是只是一个被动的函数调用,当用户试图删除一个资源的时候, 就会把这个资源提交给 GC,然后 GC 执行一系列既定的删除流程,一般来说包括:
删除子资源 执行删除前清理工作(finalizer) 删除资源
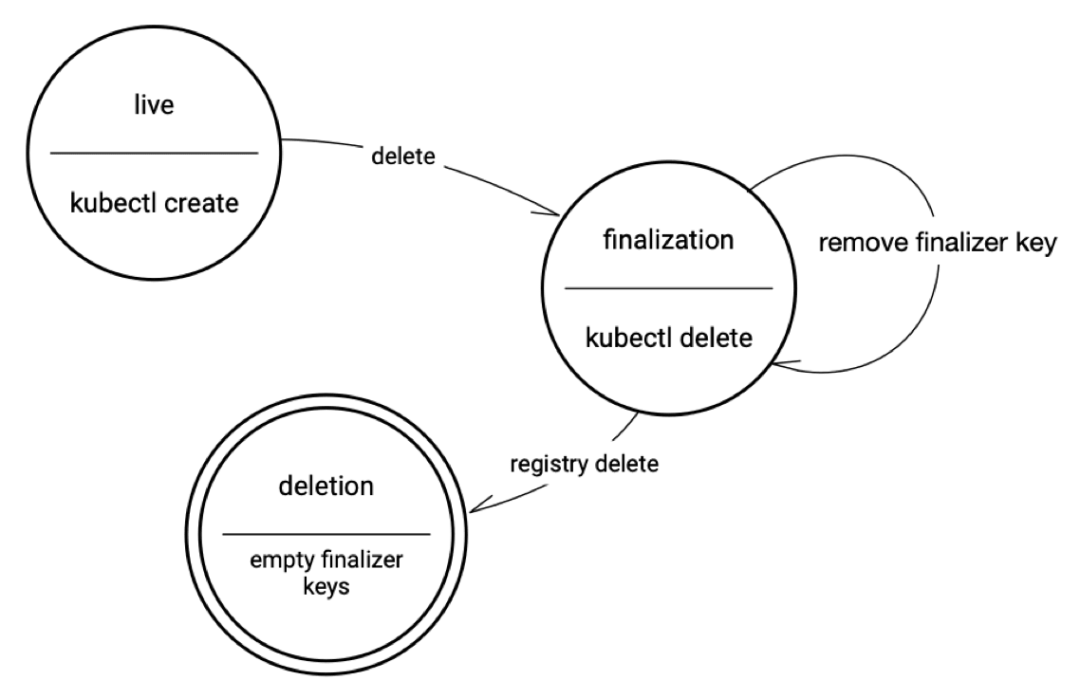
k8s 的资源间存在上下游依赖,当你删除一个上游资源时,其下游资源也需要被删除,这被称为级联删除 cascading deletion。
删除一个资源有三种策略(propagationPolicy/DeletionPropagation):
Foreground(default): Children are deleted before the parent (post-order)Background: Parent is deleted before the children (pre-order)Orphan: 忽略 owner references
可以在运行 kubectl delete --cascade=??? 的时候指定删除的策略,默认为 foreground。
2、Deletion
k8s 中,资源的 metadata 中有几个对删除比较重要的属性:
ownerRerences: 指向父资源的 UIDdeletionTimestamp: 如果不为空,表明该资源正在被删除中finalizers: 一个字符串数组,列举删除前必须执行的操作blockOwnerDeletion: 布尔,当前资源是否会阻塞父资源的删除流程
每一个资源都有 metadata.finalizers,这是一个 []string, 内含一些预定义的字符串,表明了在删除资源前必须要做的操作。每执行完一个操作,就从 finalizers 中移除这个字符串。
无论是什么删除策略,都需要先把所有的 finalizer 逐一执行完,每完成一个,就从 finalizers 中移除一个。在 finalizers 为空后,才能正式的删除资源。
foreground、orphan 删除就是通过 finalizer 来实现的。
const (
FinalizerOrphanDependents = "orphan"
FinalizerDeleteDependents = "foregroundDeletion"
)
注:有一种让资源永不删除的黑魔法,就是为资源注入一个不存在的 finalizer。因为 GC 无法找到该 finalizer 匹配的函数来执行,就导致这个 finalizer 始终无法被移除, 而 finalizers 为空清空的资源是不允许被删除的。
3、Foreground cascading deletion
设置资源的 deletionTimestamp,表明该资源的状态为正在删除中("deletion in progress")。设置资源的 metadata.finalizers为"foregroundDeletion"。删除所有 ownerReference.blockOwnerDeletion=true的子资源删除当前资源
每一个子资源的 owner 列表的元素里,都有一个属性 ownerReference.blockOwnerDeletion,这是一个 bool, 表明当前资源是否会阻塞父资源的删除流程。删除父资源前,应该把所有标记为阻塞的子资源都删光。
在当前资源被删除以前,该资源都通过 apiserver 持续可见。
4、Orphan deletion
触发 FinalizerOrphanDependents,将所有子资源的 owner 清空,也就是令其成为 orphan。然后再删除当前资源。
5、Background cascading deletion
立刻删除当前资源,然后在后台任务中删除子资源。
graph LR
A1{是否有 finalizers} --> |Yes: pop, execute| A1
A1 --> |No| A2[删除自己]
A2 --> A3{父资源是否在等待删除}
A3 --> |No| A4[删除所有子资源]
A3 --> |Yes| A31[在删除队列里提交父资源]
A31 --> A4
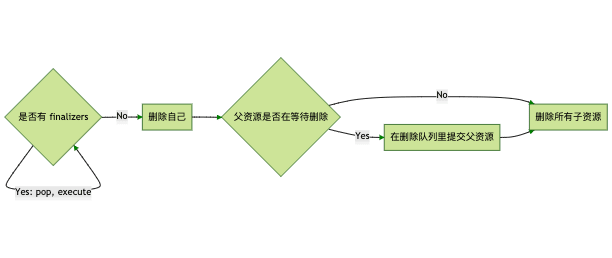
foreground 和 orphan 删除策略是通过 finalizer 实现的 因为这两个策略有一些删除前必须要做的事情:
foreground finalizer: 将所有的子资源放入删除事件队列 orphan finalizer: 将所有的子资源的 owner 设为空
而 background 则就是走标准删除流程:删自己 -> 删依赖。
这个流程里有一些很有趣(绕)的设计。比如 foreground 删除,finalizer 里把所有的子资源都放入了删除队列, 然后下一步在删除当前资源的时候,会发现子资源依然存在,导致当前资源无法删除。实际上真正删除当前资源(父资源),实在删除最后一个子资源的时候,每次都会去检查下父资源的状态是否是删除中, 如果是,就把父资源放入删除队列,此时,父资源才会被真正删除。
6、Owner References
每个资源的 metadata 中都有一个 ownerReferences 列表,保存了其父资源(遍历时遇到的第一个有效的资源会被认为是其父资源)。
owner 决定了资源会如何被删除。删除子资源不会影响到父资源。删除父资源会导致子资源被联动删除。(默认 kubectl delete --cascade=foreground)
七、参考资料
关于本主题的内容,我制作了一个 slides,可用于内部分享:https://s3.laisky.com/public/slides/k8s-controller.slides.html#/
1、如何阅读源码
核心代码:https://github.com/kubernetes/kubernetes,所有的 controller 代码都在 pkg/controller/ 中。
所有的 clientset、informer 都被抽象出来在 https://github.com/kubernetes/client-go 库中,供各个组件复用。
学习用示例项目:https://github.com/kubernetes/sample-controller
2、参考文章
Garbage Collection[4] Using Finalizers to Control Deletion[5] A deep dive into Kubernetes controllers[6] kube-controller-manager[7]
引用链接
A deep dive into Kubernetes controllers: https://app.yinxiang.com/shard/s17/nl/2006464/674c3d83-f011-49b8-9135-413588c22c0f/
[2]Garbage Collection: https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/
[3]Using Finalizers to Control Deletion: https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/
[4]Garbage Collection: https://kubernetes.io/docs/concepts/workloads/controllers/garbage-collection/
[5]Using Finalizers to Control Deletion: https://kubernetes.io/blog/2021/05/14/using-finalizers-to-control-deletion/
[6]A deep dive into Kubernetes controllers: https://engineering.bitnami.com/articles/a-deep-dive-into-kubernetes-controllers.html
[7]kube-controller-manager: https://kubernetes.io/docs/reference/command-line-tools-reference/kube-controller-manager/
原文链接:https://blog.laisky.com/p/kubernetes-controller/


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰 🤘
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
