
使用 OpenKruise 增强 Kubernetes 工作负载之 CloneSet
OpenKruise 是一个基于 Kubernetes 的扩展套件,主要聚焦于云原生应用的自动化,比如部署、发布、运维以及可用性防护。OpenKruise 提供的绝大部分能力都是基于 CRD 扩展来定义的,它们不存在于任何外部依赖,可以运行在任意纯净的 Kubernetes 集群中。Kubernetes 自身提供的一些应用部署管理功能,对于大规模应用与集群的场景这些功能是远远不够的,OpenKruise 弥补了 Kubernetes 在应用部署、升级、防护、运维等领域的不足。
OpenKruise 提供了以下的一些核心能力:
增强版本的 Workloads:OpenKruise 包含了一系列增强版本的工作负载,比如 CloneSet、Advanced StatefulSet、Advanced DaemonSet、BroadcastJob 等。它们不仅支持类似于 Kubernetes 原生 Workloads 的基础功能,还提供了如原地升级、可配置的扩缩容/发布策略、并发操作等。其中,原地升级是一种升级应用容器镜像甚至环境变量的全新方式,它只会用新的镜像重建 Pod 中的特定容器,整个 Pod 以及其中的其他容器都不会被影响。因此它带来了更快的发布速度,以及避免了对其他 Scheduler、CNI、CSI 等组件的负面影响。 应用的旁路管理:OpenKruise 提供了多种通过旁路管理应用 sidecar 容器、多区域部署的方式,“旁路” 意味着你可以不需要修改应用的 Workloads 来实现它们。比如,SidecarSet 能帮助你在所有匹配的 Pod 创建的时候都注入特定的 sidecar 容器,甚至可以原地升级已经注入的 sidecar 容器镜像、并且对 Pod 中其他容器不造成影响。而 WorkloadSpread 可以约束无状态 Workload 扩容出来 Pod 的区域分布,赋予单一 workload 的多区域和弹性部署的能力。 高可用性防护:OpenKruise 可以保护你的 Kubernetes 资源不受级联删除机制的干扰,包括 CRD、Namespace、以及几乎全部的 Workloads 类型资源。相比于 Kubernetes 原生的 PDB 只提供针对 Pod Eviction 的防护,PodUnavailableBudget 能够防护 Pod Deletion、Eviction、Update 等许多种 voluntary disruption 场景。 高级的应用运维能力:OpenKruise 也提供了很多高级的运维能力来帮助你更好地管理应用,比如可以通过 ImagePullJob 来在任意范围的节点上预先拉取某些镜像,或者指定某个 Pod 中的一个或多个容器被原地重启。
架构
下图是 OpenKruise 的整体架构:
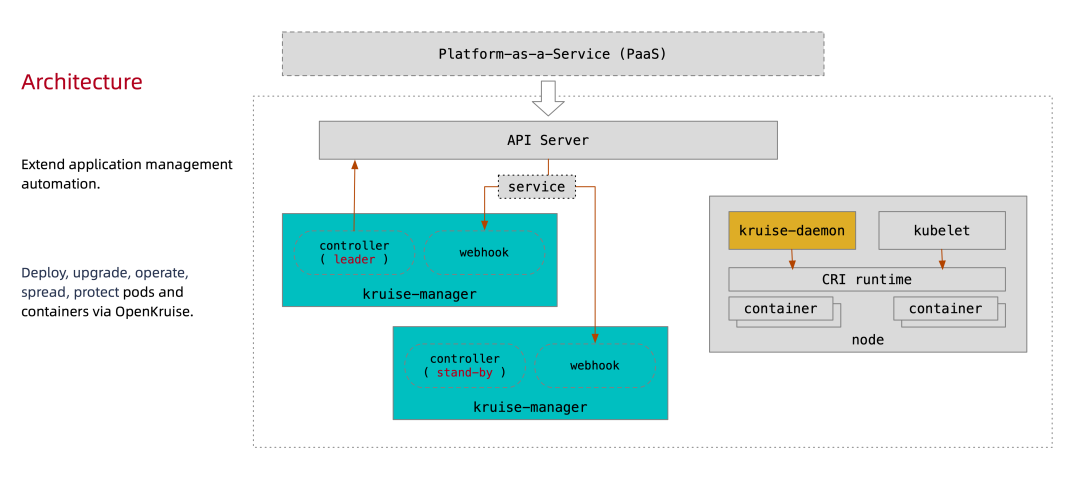
首先我们要清楚所有 OpenKruise 的功能都是通过 Kubernetes CRD 来提供的:
➜ kubectl get crd | grep kruise.io
advancedcronjobs.apps.kruise.io 2021-09-16T06:02:36Z
broadcastjobs.apps.kruise.io 2021-09-16T06:02:36Z
clonesets.apps.kruise.io 2021-09-16T06:02:36Z
containerrecreaterequests.apps.kruise.io 2021-09-16T06:02:36Z
daemonsets.apps.kruise.io 2021-09-16T06:02:36Z
imagepulljobs.apps.kruise.io 2021-09-16T06:02:36Z
nodeimages.apps.kruise.io 2021-09-16T06:02:36Z
podunavailablebudgets.policy.kruise.io 2021-09-16T06:02:36Z
resourcedistributions.apps.kruise.io 2021-09-16T06:02:36Z
sidecarsets.apps.kruise.io 2021-09-16T06:02:36Z
statefulsets.apps.kruise.io 2021-09-16T06:02:36Z
uniteddeployments.apps.kruise.io 2021-09-16T06:02:37Z
workloadspreads.apps.kruise.io 2021-09-16T06:02:37Z
其中 Kruise-manager 是一个运行控制器和 webhook 的中心组件,它通过 Deployment 部署在 kruise-system 命名空间中。从逻辑上来看,如 cloneset-controller、sidecarset-controller 这些的控制器都是独立运行的,不过为了减少复杂度,它们都被打包在一个独立的二进制文件、并运行在 kruise-controller-manager-xxx 这个 Pod 中。除了控制器之外,kruise-controller-manager-xxx 中还包含了针对 Kruise CRD 以及 Pod 资源的 admission webhook。Kruise-manager 会创建一些 webhook configurations 来配置哪些资源需要感知处理、以及提供一个 Service 来给 kube-apiserver 调用。
从 v0.8.0 版本开始提供了一个新的 Kruise-daemon 组件,它通过 DaemonSet 部署到每个节点上,提供镜像预热、容器重启等功能。
安装
这里我们同样还是使用 Helm 方式来进行安装,需要注意从 v1.0.0 开始,OpenKruise 要求在 Kubernetes >= 1.16 以上版本的集群中安装和使用。
首先添加 charts 仓库:
➜ helm repo add openkruise https://openkruise.github.io/charts
➜ helm repo update
然后执行下面的命令安装最新版本的应用:
➜ helm upgrade --install kruise openkruise/kruise --version 1.0.1
该 charts 在模板中默认定义了命名空间为 kruise-system,所以在安装的时候可以不用指定,如果你的环境访问 DockerHub 官方镜像较慢,则可以使用下面的命令将镜像替换成阿里云的镜像:
➜ helm upgrade --install kruise openkruise/kruise --set manager.image.repository=openkruise-registry.cn-hangzhou.cr.aliyuncs.com/openkruise/kruise-manager --version 1.0.1
应用部署完成后会在 kruise-system 命名空间下面运行2个 kruise-manager 的 Pod,同样它们之间采用 leader-election 的方式选主,同一时间只有一个提供服务,达到高可用的目的,此外还会以 DaemonSet 的形式启动 kruise-daemon 组件:
➜ kubectl get pods -n kruise-system
NAME READY STATUS RESTARTS AGE
kruise-controller-manager-f5c9b55c5-7hgt9 1/1 Running 0 4m3s
kruise-controller-manager-f5c9b55c5-v9ptf 1/1 Running 0 4m3s
kruise-daemon-bqf5v 1/1 Running 0 4m3s
kruise-daemon-hvgwv 1/1 Running 0 4m3s
kruise-daemon-tnqsx 1/1 Running 0 4m3s
如果不想使用默认的参数进行安装,也可以自定义配置,可配置的 values 值可以参考 charts 文档 https://github.com/openkruise/charts 进行定制。
CloneSet
CloneSet 控制器是 OpenKruise 提供的对原生 Deployment 的增强控制器,在使用方式上和 Deployment 几乎一致,如下所示是我们声明的一个 CloneSet 资源对象:
# cloneset-demo.yaml
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
replicas: 3
selector:
matchLabels:
app: cs
template:
metadata:
labels:
app: cs
spec:
containers:
- name: nginx
image: nginx:alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
直接创建上面的这个 CloneSet 对象:
➜ kubectl apply -f cloneset-demo.yaml
➜ kubectl get cloneset cs-demo
NAME DESIRED UPDATED UPDATED_READY READY TOTAL AGE
cs-demo 3 3 3 3 3 112s
➜ kubectl describe cloneset cs-demo
Name: cs-demo
Namespace: default
Labels:
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps.kruise.io/v1alpha1","kind":"CloneSet","metadata":{"annotations":{},"name":"cs-demo","namespace":"default"},"spec":{"re...
API Version: apps.kruise.io/v1alpha1
Kind: CloneSet
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 53s cloneset-controller succeed to create pod cs-demo-b6r6t
Normal SuccessfulCreate 53s cloneset-controller succeed to create pod cs-demo-fsbx5
Normal SuccessfulCreate 53s cloneset-controller succeed to create pod cs-demo-fv5gb
该对象创建完成后我们可以通过 kubectl describe 命令查看对应的 Events 信息,可以发现 cloneset-controller 是直接创建的 Pod,这个和原生的 Deployment 就有一些区别了,Deployment 是通过 ReplicaSet 去创建的 Pod,所以从这里也可以看出来 CloneSet 是直接管理 Pod 的,3个副本的 Pod 此时也创建成功了:
➜ kubectl get pods -l app=cs
NAME READY STATUS RESTARTS AGE
cs-demo-b6r6t 1/1 Running 0 5m19s
cs-demo-fsbx5 1/1 Running 0 5m19s
cs-demo-fv5gb 1/1 Running 0 5m19s
CloneSet 虽然在使用上和 Deployment 比较类似,但还是有非常多比 Deployment 更高级的功能,下面我们来详细介绍下。
扩缩容
CloneSet 在扩容的时候可以通过 ScaleStrategy.MaxUnavailable 来限制扩容的步长,这样可以对服务应用的影响最小,可以设置一个绝对值或百分比,如果不设置该值,则表示不限制。
比如我们在上面的资源清单中添加如下所示数据:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
replicas: 5
......
上面我们配置 scaleStrategy.maxUnavailable 为1,结合 minReadySeconds 参数,表示在扩容时,只有当上一个扩容出的 Pod 已经 Ready 超过一分钟后,CloneSet 才会执行创建下一个 Pod,比如这里我们扩容成5个副本,更新上面对象后查看 CloneSet 的事件:
➜ kubectl describe cloneset cs-demo
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 35m cloneset-controller succeed to create pod cs-demo-b6r6t
Normal SuccessfulCreate 35m cloneset-controller succeed to create pod cs-demo-fsbx5
Normal SuccessfulCreate 35m cloneset-controller succeed to create pod cs-demo-fv5gb
Warning ScaleUpLimited 2m39s cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 1
Normal SuccessfulCreate 2m39s cloneset-controller succeed to create pod cs-demo-xlsdg
Normal SuccessfulCreate 98s cloneset-controller succeed to create pod cs-demo-8w7h4
Warning ScaleUpLimited 68s (x12 over 2m39s) cloneset-controller scaleUp is limited because of scaleStrategy.maxUnavailable, limit: 0
Normal SuccessfulCreate 37s cloneset-controller succeed to create pod cs-demo-79rcx
可以看到第一时间扩容了一个 Pod,由于我们配置了 minReadySeconds: 60,也就是新扩容的 Pod 创建成功超过1分钟后才会扩容另外一个 Pod,上面的 Events 信息也能表现出来,查看 Pod 的 AGE 也能看出来扩容的2个 Pod 之间间隔了1分钟左右:
➜ kubectl get pods -l app=cs
NAME READY STATUS RESTARTS AGE
cs-demo-79rcx 1/1 Running 0 2m3s
cs-demo-8w7h4 1/1 Running 0 3m4s
cs-demo-b6r6t 1/1 Running 0 36m
cs-demo-fv5gb 1/1 Running 0 36m
cs-demo-p4kmw 1/1 Running 0 36s
当 CloneSet 被缩容时,我们还可以指定一些 Pod 来删除,这对于 StatefulSet 或者 Deployment 来说是无法实现的, StatefulSet 是根据序号来删除 Pod,而 Deployment/ReplicaSet 目前只能根据控制器里定义的排序来删除。而 CloneSet 允许用户在缩小 replicas 数量的同时,指定想要删除的 Pod 名字,如下所示:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
minReadySeconds: 60
scaleStrategy:
maxUnavailable: 1
podsToDelete:
- cs-demo-79rcx
replicas: 4
......
更新上面的资源对象后,会将应用缩到4个 Pod,如果在 podsToDelete 列表中指定了 Pod 名字,则控制器会优先删除这些 Pod,对于已经被删除的 Pod,控制器会自动从 podsToDelete 列表中清理掉。比如我们更新上面的资源对象后 cs-demo-79rcx 这个 Pod 会被移除,其余会保留下来:
➜ kubectl get pods -l app=cs
NAME READY STATUS RESTARTS AGE
cs-demo-8w7h4 1/1 Running 4 (51m ago) 3d6h
cs-demo-b6r6t 1/1 Running 4 (51m ago) 3d6h
cs-demo-fv5gb 1/1 Running 4 (51m ago) 3d6h
cs-demo-p4kmw 1/1 Running 4 (51m ago) 3d6h
如果你只把 Pod 名字加到 podsToDelete,但没有修改 replicas 数量,那么控制器会先把指定的 Pod 删掉,然后再扩一个新的 Pod,另一种直接删除 Pod 的方式是在要删除的 Pod 上打 apps.kruise.io/specified-delete: true 标签。
相比于手动直接删除 Pod,使用 podsToDelete 或 apps.kruise.io/specified-delete: true 方式会有 CloneSet 的 maxUnavailable/maxSurge 来保护删除, 并且会触发 PreparingDelete 生命周期的钩子。
升级
CloneSet 一共提供了 3 种升级方式:
ReCreate: 删除旧 Pod 和它的 PVC,然后用新版本重新创建出来,这是默认的方式InPlaceIfPossible: 会优先尝试原地升级 Pod,如果不行再采用重建升级InPlaceOnly: 只允许采用原地升级,因此,用户只能修改上一条中的限制字段,如果尝试修改其他字段会被拒绝
这里有一个重要概念:原地升级,这也是 OpenKruise 提供的核心功能之一,当我们要升级一个 Pod 中镜像的时候,下图展示了重建升级和原地升级的区别:
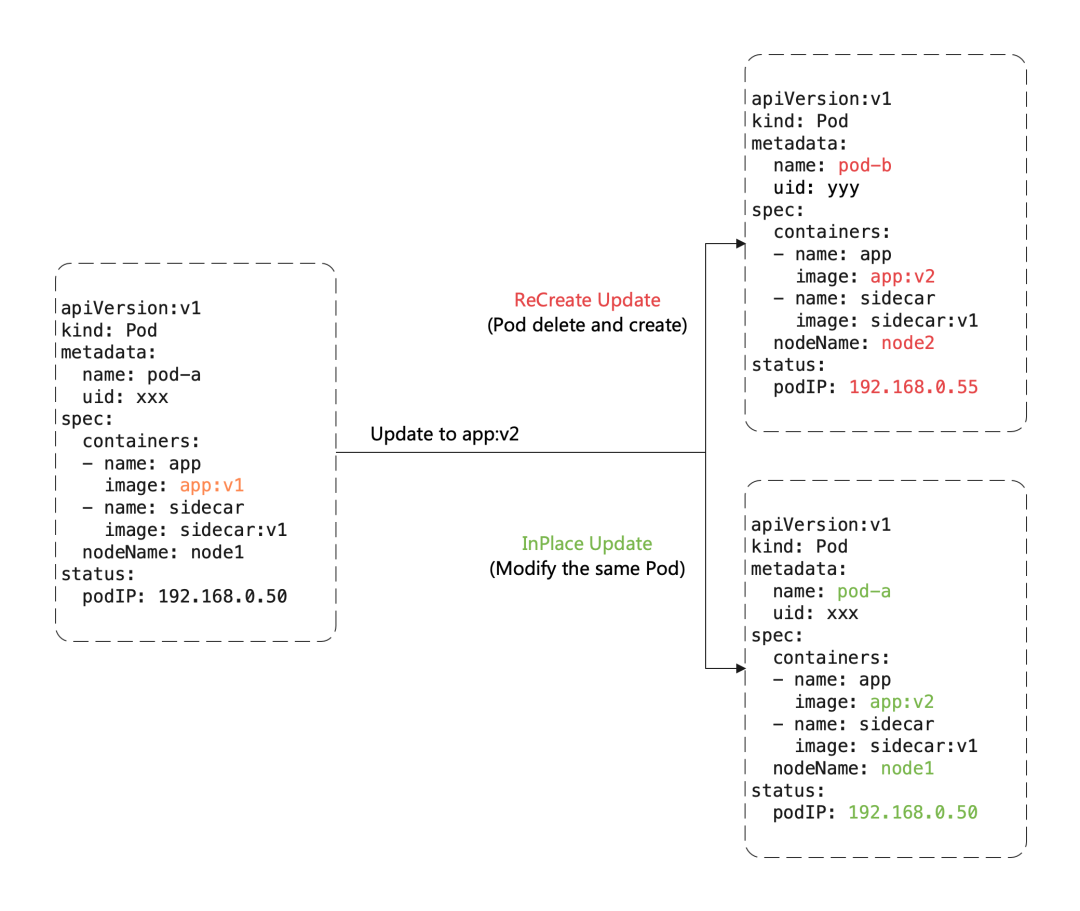
重建升级时我们需要删除旧 Pod、创建新 Pod:
Pod 名字和 uid 发生变化,因为它们是完全不同的两个 Pod 对象(比如 Deployment 升级) Pod 名字可能不变、但 uid 变化,因为它们是不同的 Pod 对象,只是复用了同一个名字(比如 StatefulSet 升级) Pod 所在 Node 名字可能发生变化,因为新 Pod 很可能不会调度到之前所在的 Node 节点 Pod IP 发生变化,因为新 Pod 很大可能性是不会被分配到之前的 IP 地址
但是对于原地升级,我们仍然复用同一个 Pod 对象,只是修改它里面的字段:
可以避免如调度、分配 IP、挂载盘等额外的操作和代价 更快的镜像拉取,因为会复用已有旧镜像的大部分 layer 层,只需要拉取新镜像变化的一些 layer 当一个容器在原地升级时,Pod 中的其他容器不会受到影响,仍然维持运行
所以显然如果能用原地升级方式来升级我们的工作负载,对在线应用的影响是最小的。上面我们提到 CloneSet 升级类型支持 InPlaceIfPossible,这意味着 Kruise 会尽量对 Pod 采取原地升级,如果不能则退化到重建升级,以下的改动会被允许执行原地升级:
更新 workload 中的 spec.template.metadata.*,比如 labels/annotations,Kruise 只会将 metadata 中的改动更新到存量 Pod 上。更新 workload 中的 spec.template.spec.containers[x].image,Kruise 会原地升级 Pod 中这些容器的镜像,而不会重建整个 Pod。从 Kruise v1.0 版本开始,更新 spec.template.metadata.labels/annotations并且 container 中有配置 env from 这些改动的labels/anntations,Kruise 会原地升级这些容器来生效新的 env 值。
否则,其他字段的改动,比如 spec.template.spec.containers[x].env 或 spec.template.spec.containers[x].resources,都是会回退为重建升级。
比如我们将上面的应用升级方式设置为 InPlaceIfPossible,只需要在资源清单中添加 spec.updateStrategy.type: InPlaceIfPossible 即可:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
name: cs-demo
spec:
updateStrategy:
type: InPlaceIfPossible
......
更新后可以发现 Pod 的状态并没有发生什么大的变化,名称、IP 都一样,唯一变化的是镜像 tag:
➜ kubectl get pods -l app=cs
NAME READY STATUS RESTARTS AGE
cs-demo-8w7h4 1/1 Running 4 (55m ago) 3d6h
cs-demo-b6r6t 1/1 Running 4 (55m ago) 3d6h
cs-demo-fv5gb 1/1 Running 5 (20s ago) 3d6h
cs-demo-p4kmw 1/1 Running 5 (83s ago) 3d6h
➜ kubectl describe cloneset cs-demo
Name: cs-demo
Namespace: default
Labels:
Annotations:
API Version: apps.kruise.io/v1alpha1
Kind: CloneSet
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulDelete 4m44s cloneset-controller succeed to delete pod cs-demo-79rcx
Normal SuccessfulUpdatePodInPlace 97s cloneset-controller successfully update pod cs-demo-p4kmw in-place(revision cs-demo-7cb9c88699)
Normal SuccessfulUpdatePodInPlace 34s cloneset-controller successfully update pod cs-demo-fv5gb in-place(revision cs-demo-7cb9c88699)
➜ kubectl describe pod cs-demo-p4kmw
......
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulled 56m kubelet Container image "nginx:alpine" already present on machine
Normal Created 2m28s (x2 over 56m) kubelet Created container nginx
Normal Killing 2m28s kubelet Container nginx definition changed, will be restarted
Normal Pulled 2m28s kubelet Container image "nginx:1.7.9" already present on machine
Normal Started 2m27s (x2 over 56m) kubelet Started container nginx
这就是原地升级的效果,原地升级整体工作流程如下图所示:
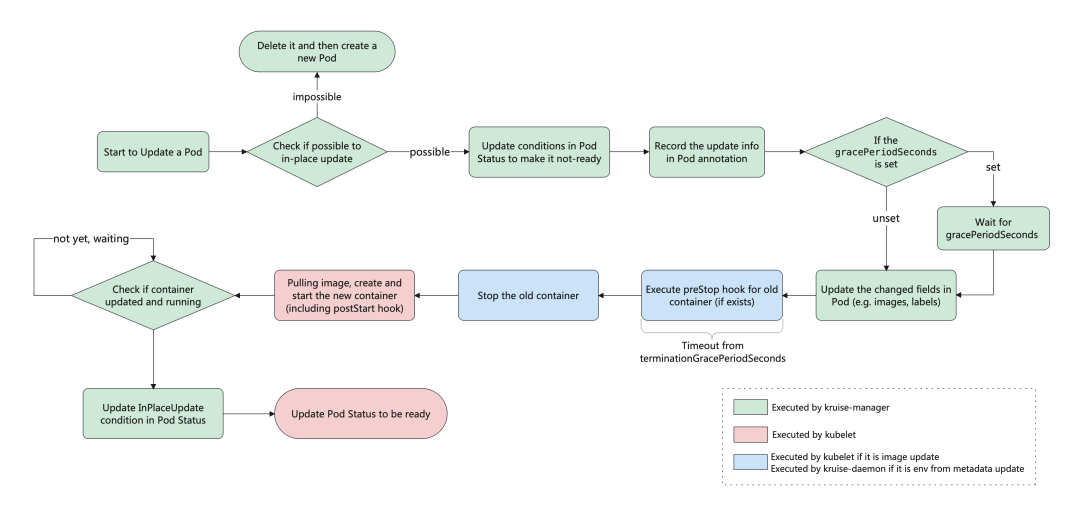
如果你在安装或升级 Kruise 的时候启用了 PreDownloadImageForInPlaceUpdate 这个 feature-gate,CloneSet 控制器会自动在所有旧版本 pod 所在节点上预热你正在灰度发布的新版本镜像,这对于应用发布加速很有帮助。
默认情况下 CloneSet 每个新镜像预热时的并发度都是 1,也就是一个个节点拉镜像,如果需要调整,你可以在 CloneSet annotation 上设置并发度:
apiVersion: apps.kruise.io/v1alpha1
kind: CloneSet
metadata:
annotations:
apps.kruise.io/image-predownload-parallelism: "5"
注意,为了避免大部分不必要的镜像拉取,目前只针对
replicas > 3的 CloneSet 做自动预热。
此外 CloneSet 还支持分批进行灰度,在 updateStrategy 属性中可以配置 partition 参数,该参数可以用来保留旧版本 Pod 的数量或百分比,默认为0:
如果是数字,控制器会将 (replicas - partition)数量的 Pod 更新到最新版本如果是百分比,控制器会将 (replicas * (100% - partition))数量的 Pod 更新到最新版本
比如,我们将上面示例中的的 image 更新为 nginx:latest 并且设置 partition=2,更新后,过一会查看可以发现只升级了2个 Pod:
➜ kubectl get pods -l app=cs -L controller-revision-hash
NAME READY STATUS RESTARTS AGE CONTROLLER-REVISION-HASH
cs-demo-dx4lb 1/1 Running 0 69s cs-demo-6599fc6cdd
cs-demo-fv5gb 1/1 Running 0 3d7h cs-demo-7cb9c88699
cs-demo-nngtm 1/1 Running 0 8s cs-demo-6599fc6cdd
cs-demo-p4kmw 1/1 Running 0 3d6h cs-demo-7cb9c88699
此外 CloneSet 还支持一些更高级的用法,比如可以定义优先级策略来控制 Pod 发布的优先级规则,还可以定义策略来将一类 Pod 打散到整个发布过程中,也可以暂停 Pod 发布等操作。