
一个ClickHouse高可用集群部署方案
 点击左下方 阅读原文 查看工程源码
点击左下方 阅读原文 查看工程源码
GitHub地址: https://github.com/mapcoding-cn/clickhouse
开箱即用的容器化部署clickhouse高可用集群方案
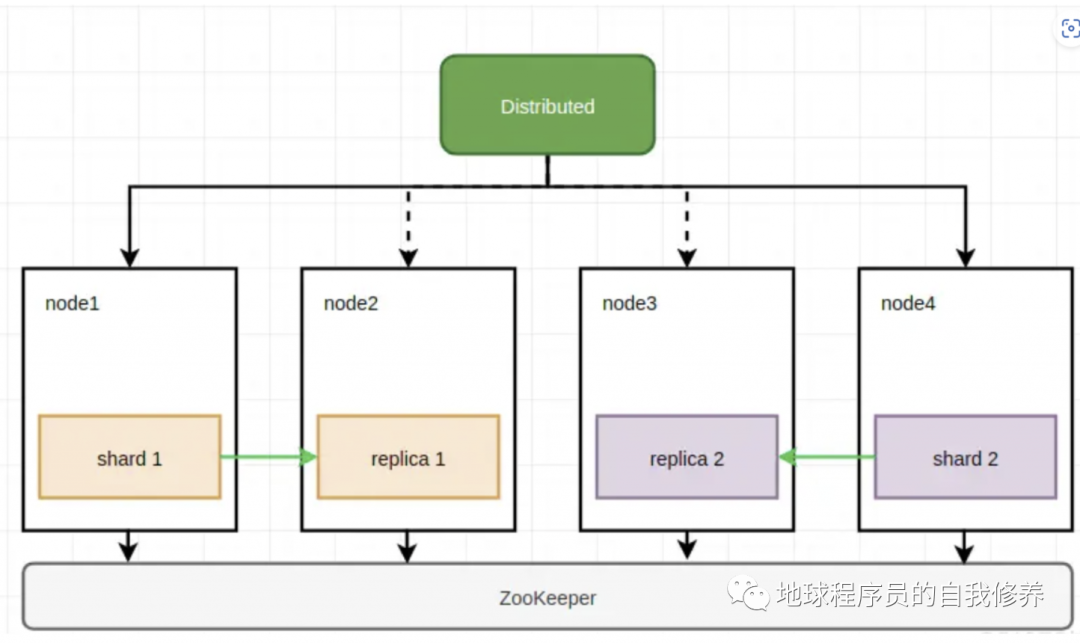
clickhouse-server
支持多副本多分片,支持zookeeper一致性副本的高可用集群,修复了docker化部署的一些问题 示例中是一个6节点3shard2副本的配置,真实部署需要修改docker IP和zookeeper指向地址
zookeeper-server
一个三节点的zookeeper高可用集群,clickhouse用它来注册配置和维护副本一致性
clickhouse-tabix
一个支持语法高亮和代码提示的sql编辑器,可以部署前端访问clickhouse,该版本做了部分优化,仍有非常多的beta特性,但也足够使用
--创建数据库
CREATE DATABASE mapcoding on CLUSTER map ;
--创建本地表
CREATE TABLE mapcoding.uk_price_paid on CLUSTER map
(
price UInt32,
date Date,
postcode1 LowCardinality(String),
postcode2 LowCardinality(String),
type Enum8('terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4, 'other' = 0),
is_new UInt8,
duration Enum8('freehold' = 1, 'leasehold' = 2, 'unknown' = 0),
addr1 String,
addr2 String,
street LowCardinality(String),
locality LowCardinality(String),
town LowCardinality(String),
district LowCardinality(String),
county LowCardinality(String)
)
ENGINE = ReplicatedMergeTree('/clickhouse/map/mapcoding/{shard}/uk_price_paid', '{replica}')
ORDER BY (postcode1, postcode2, addr1, addr2);
--创建分布式表
create TABLE mapcoding.uk_price_paid_distributed on cluster map as mapcoding.uk_price_paid ENGINE = Distributed("map", "mapcoding", "uk_price_paid", rand());
--插入测试数据
INSERT INTO mapcoding.uk_price_paid_distributed
WITH
splitByChar(' ', postcode) AS p
SELECT
toUInt32(price_string) AS price,
parseDateTimeBestEffortUS(time) AS date,
p[1] AS postcode1,
p[2] AS postcode2,
transform(a, ['T', 'S', 'D', 'F', 'O'], ['terraced', 'semi-detached', 'detached', 'flat', 'other']) AS type,
b = 'Y' AS is_new,
transform(c, ['F', 'L', 'U'], ['freehold', 'leasehold', 'unknown']) AS duration,
addr1,
addr2,
street,
locality,
town,
district,
county
FROM url(
' http://prod.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com/pp-complete.csv ',
'CSV',
'uuid_string String,
price_string String,
time String,
postcode String,
a String,
b String,
c String,
addr1 String,
addr2 String,
street String,
locality String,
town String,
district String,
county String,
d String,
e String'
) SETTINGS max_http_get_redirects=10;
机器配置推荐
硬盘存储: 31亿Github Events数据占用磁盘空间约在200G左右,同级别mysql占用了1T,验证ch的压缩效率约为mysql的5倍,推测单机百亿级别磁盘合理配置应在1T以上,需使用副本确保数据不丢失
CPU和内存: 使用场景强相关,推荐单机最低配置在4c8G以上,设置多分片增强性能.CH会根据机器配置自动调整资源使用,使用2c4g在31亿数据集上查询出现memory_limit
附:性能测试报告
测试脚本 clickhouse-benchmark -h 172.17.1.1 –user=map –password=clic -c 100 -i 1000 -r < log.txt
查询性能
SELECT count(*) from mapcoding.github_events_distributed where event_type='IssuesEvent';
--group
SELECT actor_login,count(),uniq(repo_name) AS repos,uniq(repo_name, number) AS prs, replaceRegexpAll(substringUTF8(anyHeavy(body), 1, 100), '[\r\n]', ' ') AS comment FROM mapcoding.github_events_distributed WHERE (event_type = 'PullRequestReviewCommentEvent') AND (action = 'created') GROUP BY actor_login ORDER BY count() DESC LIMIT 50
--join
select count(*) from (SELECT repo_name from mapcoding.github_events_distributed where event_type='IssuesEvent' limit 10000000) A left join (SELECT repo_name from mapcoding.github_events_distributed where event_type='IssueCommentEvent' limit 10000000) B ON A.repo_name=B.repo_name ;
--复合查询
SELECT actor_login, COUNT(*) FROM mapcoding.github_events_distributed WHERE event_type='IssuesEvent' GROUP BY actor_login HAVING COUNT(*) > 10 ORDER BY count(*) DESC LIMIT 100
--主键查询
select actor_login from mapcoding.github_events_distributed where repo_name like 'elastic%' limit 100
--二级索引 主键和索引粒度的选择对查询性能有致命的影响
-- ALTER TABLE mapcoding.github_events ON cluster unimap_test ADD INDEX actor_login_index actor_login TYPE set(0) GRANULARITY 2;
-- ALTER TABLE mapcoding.github_events ON cluster unimap_test MATERIALIZE INDEX actor_login_index;
-- ALTER TABLE mapcoding.github_events ON cluster unimap_test DROP INDEX actor_login_index;
SELECT count(*) FROM mapcoding.github_events_distributed WHERE actor_login='frank';
限制查询并发在100以内,走主键的查询耗时90分位在2s左右
大数据量的分析时间和索引相关度高,31亿数据分析走全表扫描约在10-20s
写入性能
批量插入测试31亿数据耗时3个小时,每秒插入数据在20-30w
单条插入性能没有测试,预计不佳
点击左下方 阅读原文 查看工程源码