
如何安装一个高可用K3s集群?
作者介绍

在之前的文章中,我们已经了解到如何设置一个多节点的etcd集群。在本文中,我们将利用相同的基础架构来设置和配置一个基于K3s的高可用Kubernetes集群。
高可用Kubernetes集群
Kubernetes集群的控制平面大多是是无状态的。唯一有状态的控制平面组件是etcd数据库,它为整个集群充当了唯一事实来源。API Server作为etcd数据库的网关,内部和外部的用户都可以通过它访问和操作状态。
etcd数据库必须配置在HA模式下,以确保没有单点故障。配置高可用(HA)Kubernetes集群的拓扑有两种选择,这取决于如何设置etcd。
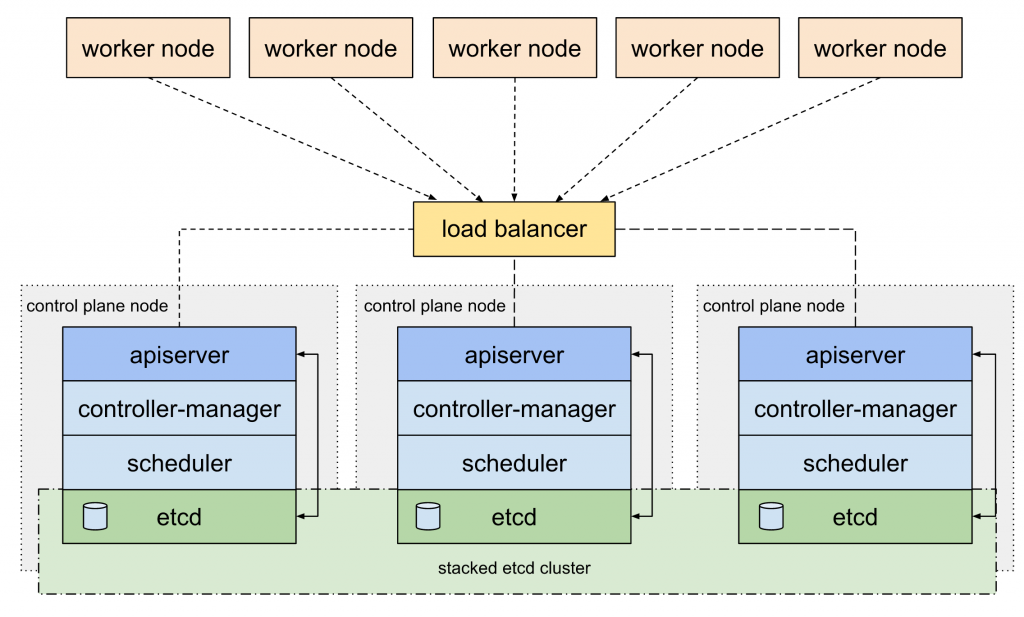
第一种拓扑是基于堆栈集群设计的,每个节点与控制平面一起运行一个etcd实例。每个控制平面节点运行一个kube-apiserver、kube-scheduler和kube-controller-manager的实例。kube-apiserver使用负载均衡器暴露给worker节点。
每个控制平面节点创建一个本地etcd成员,并且该etcd成员仅与这一节点的kube-apiserver进行通信。这同样适用于本地的kube-controller-manager和kube-scheduler实例。
这种拓扑结构要求HA Kubernetes集群至少有三种堆栈控制平面模式。Kubeadm,这个流行的集群安装工具,使用这种拓扑来配置Kubernetes集群。
第二种拓扑使用在一组完全不同的主机上安装和管理的外部etcd集群。
在此拓扑中,每个控制平面节点都运行kube-apiserver,kube-scheduler和kube-controller-manager的实例,其中每个etcd主机与每个控制平面节点的kube-apiserver通信。
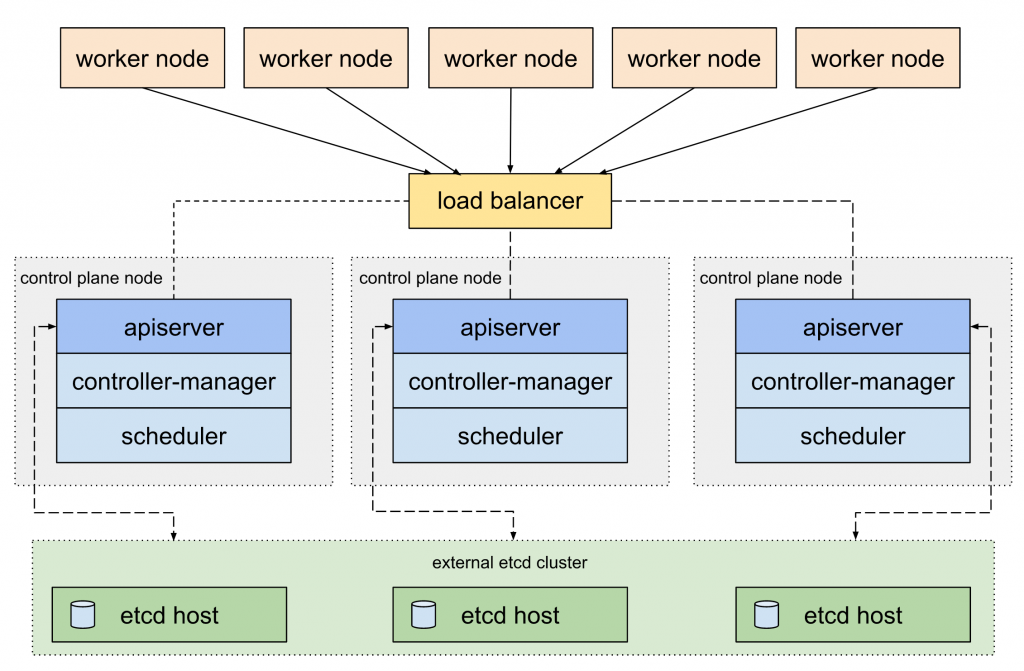
这种拓扑需要的主机数量是堆栈式HA拓扑的两倍。使用该拓扑的 HA 集群至少需要三个控制平面节点的主机和三个 etcd 节点的主机。
关于启动集群的更多信息,请参考Kubernetes官方文档:
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
高可用模式的K3s
由于K3s大多部署在边缘,硬件资源有限,可能无法在专用主机上运行etcd数据库。部署架构与堆栈式拓扑极为类似,只是事先配置了etcd数据库。
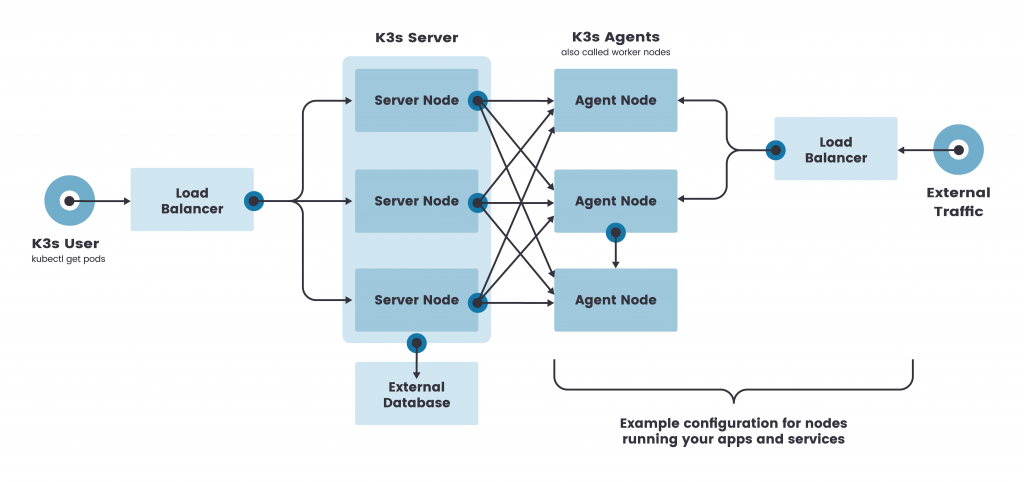
在这次教程中,我使用的是运行在Intel NUC硬件上的裸机基础设施,其映射如下:
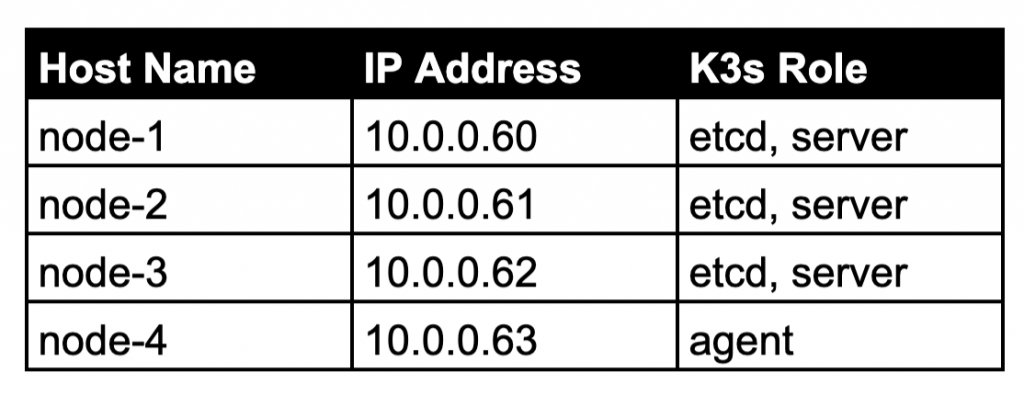
参考本系列教程的前一部分,在IP地址为10.0.0.60、10.0.0.61和10.0.0.62的前三个节点上安装和配置etcd。
安装K3s server
让我们先在所有安装etcd的节点中安装服务器。SSH进入第一个节点,并设置以下环境变量。这假定你按照前面教程中的步骤配置了etcd集群。
export K3S_DATASTORE_ENDPOINT='https://10.0.0.60:2379,https://10.0.0.61:2379,https://10.0.0.62:2379'export K3S_DATASTORE_CAFILE='/etc/etcd/etcd-ca.crt'export K3S_DATASTORE_CERTFILE='/etc/etcd/server.crt'export K3S_DATASTORE_KEYFILE='/etc/etcd/server.key'
这些环境变量指示K3s安装程序利用现有的etcd数据库进行状态管理。
接下来,我们将在K3S_TOKEN中填充一个agent加入集群时使用的token。
export K3S_TOKEN="secret_edgecluster_token"我们准备好在第一个节点中安装server。运行以下命令来启动进程:
curl -sfL https://get.k3s.io | sh -在节点2和节点3中重复这些步骤以启动额外的server。
此时,你有一个3节点的K3s集群,它在高可用模式下运行控制平面和etcd组件。
sudo kubectl get nodes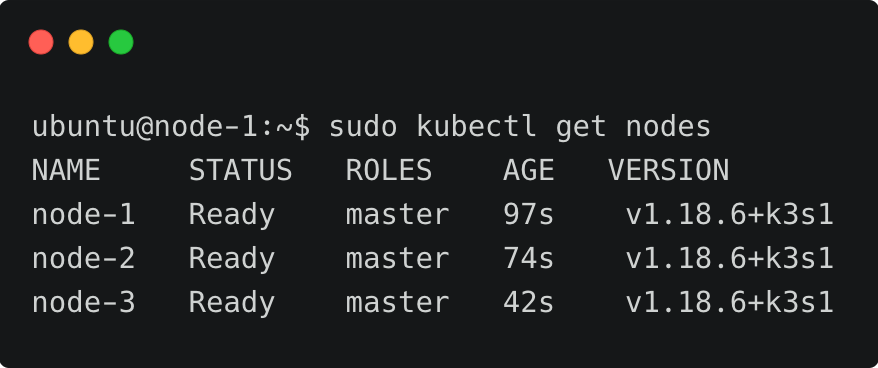
你可以使用以下命令检查服务状态:
sudo systemctl status k3s.service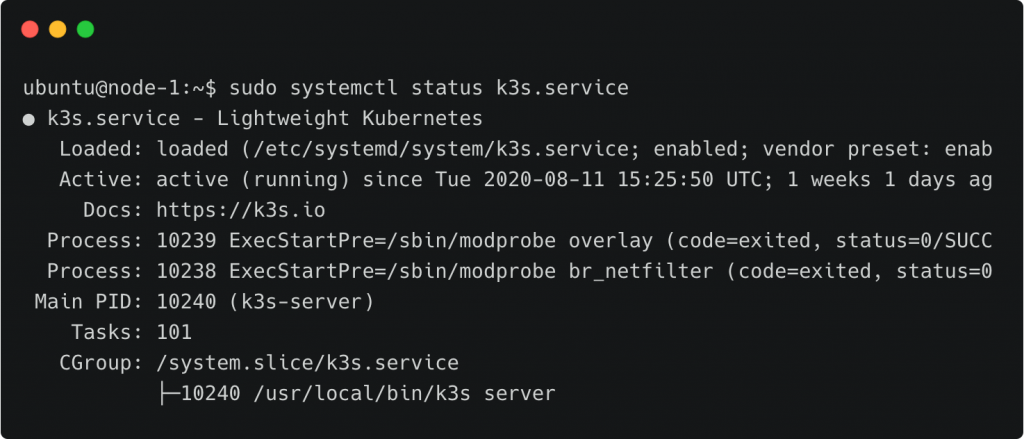
安装K3s Agent
随着控制平面的建立和运行,我们可以轻松地将worker节点获agent添加到集群中。我们只需要确保使用与server关联的相同token。
SSH进入其中一个worker节点并运行命令。
export K3S_TOKEN="secret_edgecluster_token"export K3S_URL=https://10.0.0.60:6443
环境变量K3S_URL是提示安装程序将节点配置为连接到现有服务器的agent。
最后,运行与我们上一步相同的脚本。
curl -sfL https://get.k3s.io | sh -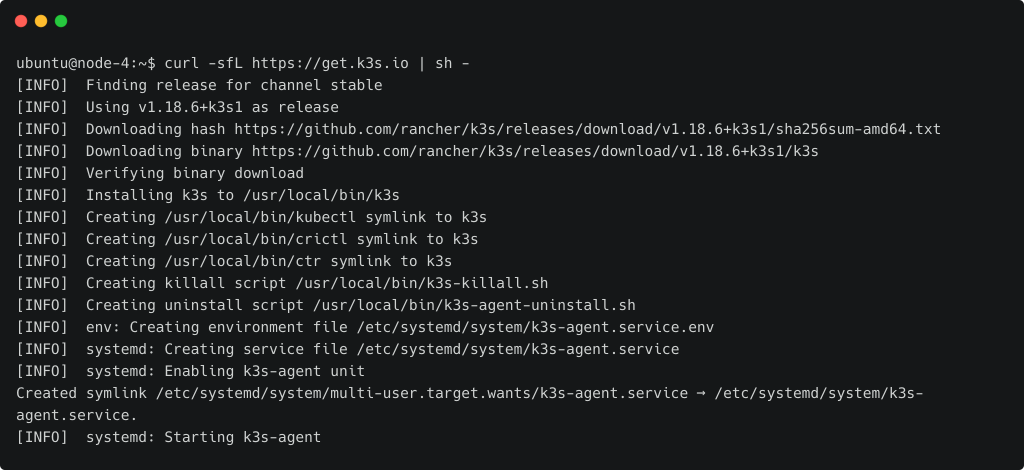
检查是否新节点已经添加到集群。
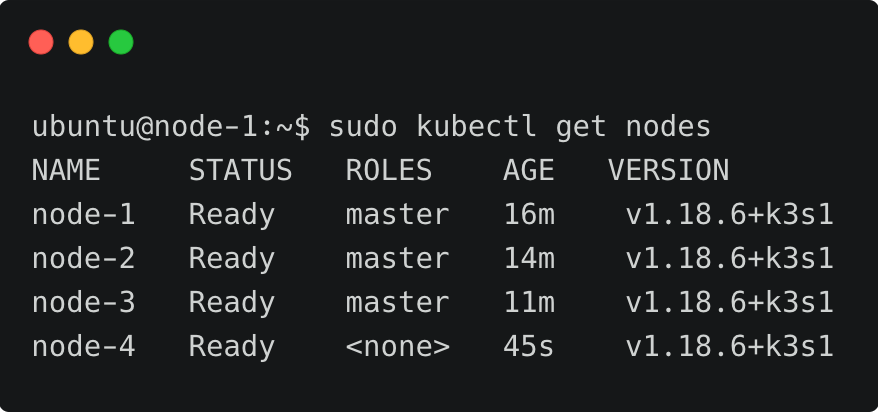
Congratulations!你已经成功安装了一个高可用K3s集群,并备份了一个外部的etcd数据库。
验证etcd数据库
让我们确保k3s集群正在使用etcd数据库进行状态管理。
我们将在K3s集群内启动一个简单的NGINX Pod。
sudo kubectl run nginx --image nginx --port 80sudo kubectl get pods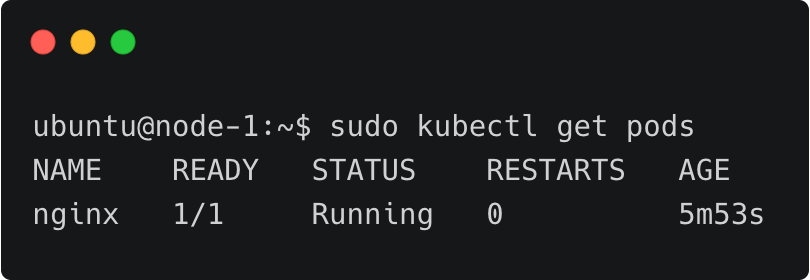
Pod规范和状态应该存储在etcd数据库中。让我们尝试通过etcdctl CLI来检索。安装jq工具来解析JSON输出。
由于输出是以base64编码的,我们将通过base64工具对其进行解码。
etcdctl --endpoints https://10.0.0.61:2379 \--cert /etc/etcd/server.crt \--cacert /etc/etcd/etcd-ca.crt \--key /etc/etcd/server.key get /registry/pods/default/nginx \--prefix=true -w json | jq -r .kvs[].value | base64 -d
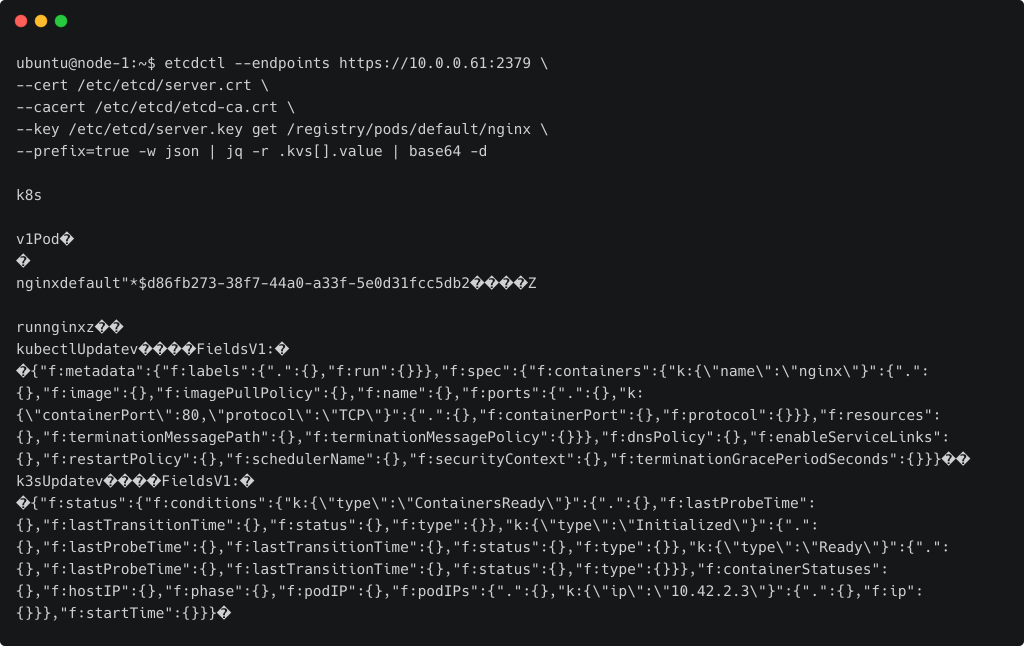
输出显示 pod 在 etcd 数据库中有一个相关的键和值。特殊字符没有正确显示,但它确实向我们展示了足够的关于pod的数据。
在本文中,我们了解了如何在高可用模式下设置和配置K3s集群,希望可以帮助你在边缘端更顺利地进行实践。
推荐阅读
扫码添加k3s中文社区助手
加入官方中文技术社区
官网:https://k3s.io