
RabbitMQ 集群高可用部署详细介绍


链接:cnblogs.com/knowledgesea/p/6535766.html
清风万里的季节,周末本该和亲人朋友一起消遣这烂漫的花花草草,或是懒洋洋的晒个太阳听听风声鸟鸣。无奈工作使然,理想使然,我回到啦公司,敲起啦键盘,撸起啦代码,程序狗的世界一片黯然,一片黯然,愿天下所有努力的程序狗都梦想成真吧!!回到正题,为什么搭建rabbitmq集群?rabbitmq集群有那些模式?如何搭建Rabbitmq集群?rabbitmq镜像高可用策略有那些?
1、首先这款产品本身的优点众多,大家最看好的便是他的异步化提高系统抗峰值能力,然后便是系统及功能结构解耦,那么照此两点来说,他的在整个系统中的作用还是至关重要的,那么如此重要,当然要考虑他的高可用性,那么便有啦第一个问题的解答。
2、rabbitmq有3种模式,但集群模式是2种。详细如下:
- 单一模式:即单机情况不做集群,就单独运行一个rabbitmq而已。
- 普通模式:默认模式,以两个节点(rabbit01、rabbit02)为例来进行说明。对于Queue来说,消息实体只存在于其中一个节点rabbit01(或者rabbit02),rabbit01和rabbit02两个节点仅有相同的元数据,即队列的结构。当消息进入rabbit01节点的Queue后,consumer从rabbit02节点消费时,RabbitMQ会临时在rabbit01、rabbit02间进行消息传输,把A中的消息实体取出并经过B发送给consumer。所以consumer应尽量连接每一个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连rabbit01或rabbit02,出口总在rabbit01,会产生瓶颈。当rabbit01节点故障后,rabbit02节点无法取到rabbit01节点中还未消费的消息实体。如果做了消息持久化,那么得等rabbit01节点恢复,然后才可被消费;如果没有持久化的话,就会产生消息丢失的现象。
- 镜像模式:把需要的队列做成镜像队列,存在与多个节点属于RabbitMQ的HA方案。该模式解决了普通模式中的问题,其实质和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在客户端取数据时临时拉取。该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。所以在对可靠性要求较高的场合中适用。
[root@G bin]# cat /etc/hosts
127.0.0.1 G localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 G localhost localhost.localdomain localhost6 localhost6.localdomain6
172.18.8.224 G
172.18.8.229 F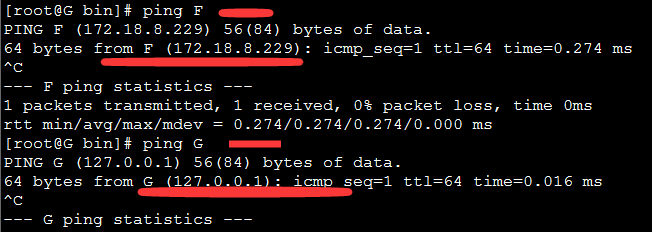

- vim /etc/rabbitmq/enable_plugins :删除文件中的内容。
- 查看hosts文件是否配置完善,相互是否可以ping通
- 查看相关端口是否被占用,如若占用kill掉
- 如果已经集群,那么要查看所有集群中的/var/lib/rabbitmq/.erlang.cookie是否一致。
- 如果不存在上述文件,echo $HOME ,打开此文件夹,查看cookie文件是否一致。
- 重启电脑,防止缓存数据配置未更新过来。
[root@G bin]# ./rabbitmq-server -deched --后台启动服务
[root@G bin]# ./rabbitmqctl start_app --启动服务
[root@G bin]# ./rabbitmqctl stop_app --关闭服务
[root@G bin]# ./rabbitmq-plugins enable rabbitmq_management --启动web管理插件
[root@G bin]# ./rabbitmqctl add_user zlh zlh --添加用户,密码
[root@G bin]# ./rabbitmqctl set_user_tags zlh administrator --设置zlh为administrator权限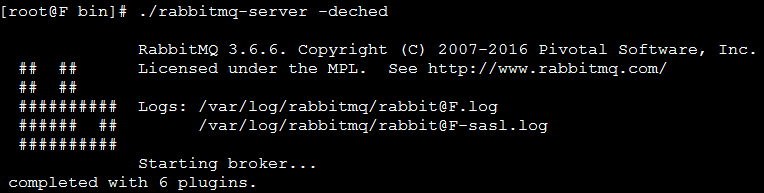


[root@F ~]# chmod 600 .erlang.cookie[root@F bin]# ./rabbitmqctl cluster_status
Cluster status of node rabbit@F ...
[{nodes,[{disc,[rabbit@G]},{ram,[rabbit@F]}]},
{running_nodes,[rabbit@G,rabbit@F]},
{cluster_name,<<"rabbit@F">>},
{partitions,[]},
{alarms,[{rabbit@G,[]},{rabbit@F,[]}]}][root@F bin]# ./rabbitmqctl stop_app[root@F bin]# ./rabbitmqctl join_cluster --ram rabbit@G[root@F bin]# ./rabbitmqctl start_app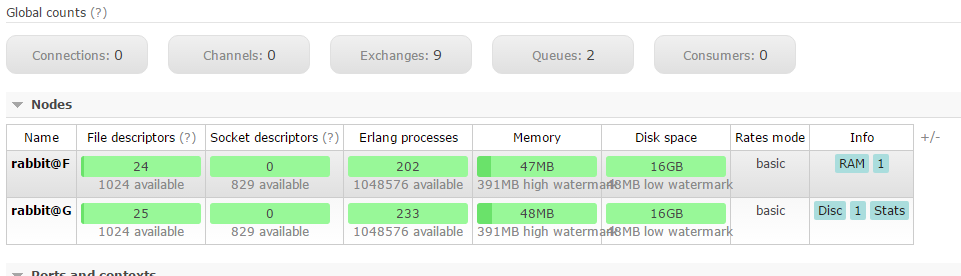
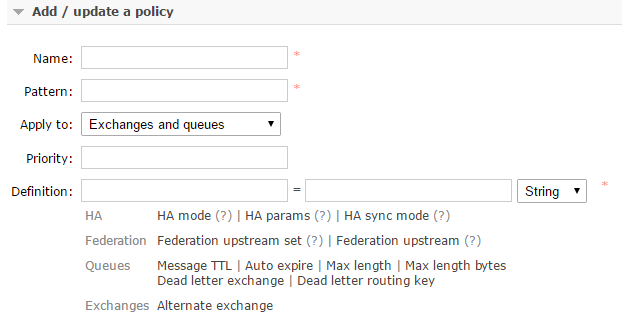
[root@G ~]# ./rabbitmqctl set_policy ha-all "^" '{"ha-mode":"all"}'

- End -

技术连载目录(可点击跳转即可阅读):
面试题系列教程 点击--> 面试题技术干货连载目录 跳转
Maven系列教程 点击--> Maven技术干货连载目录 跳转
MyBatis系列教程 点击--> MyBatis技术干货连载目录 跳转
JVM调优总结系列教程 点击--> JVM调优技术干货连载目录 跳转
点击在看,愿你我不再陌生 ![]()
评论