
手把手教你使用XPath爬取免费代理IP
点击上方“Python爬虫与数据挖掘”,进行关注
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是霖hero。
前言
可能有人说,初学者Python爬虫爬数据太难啦,构造正则表达式的时候,太烦琐了,眼睛都看花了,而且前一秒还可以愉快地爬取,下一秒IP就被封了,这还爬个屁啊,不爬了。哎,不要着急,这篇文章我们教你如何使用XPath来爬取快代理中的免费代理IP,告别眼花,告别IP被封的烦恼。
XPath
首先我们来简单了解一下XPath,想要了解更多XPath,我们可以打开W3school官方文档进行了解。
什么是 XPath?
XPath是XML路径语言(XML Path Language); XPath 使用路径表达式在 XML 文档中进行导航; XPath 包含一个标准函数库; XPath 是 XSLT 中的主要元素; XPath 是一个 W3C 标准;
XPath作用是什么?
XPath用来确定XML文档中某部分位置的语言 XPath在XML文档中查找信息的语言 XPath用于在XML文档中通过元素和属性进行导航。
XPath 含有超过 100 个内建的函数。这些函数用于字符串值、数值、日期和时间比较、节点和 QName 处理、序列处理、逻辑值等等。在Python爬虫中,我们完成可以使用XPath来做相应的信息抽取。
XPath——常用规则
简单了解一下XPath后,我们来看看它的常用规则,如下表:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
我们来简单说一个示例:
//title[@*]
这就是一个XPath规则,它代表选择选取所有带有属性的 title 元素。
好了,大概了解了XPath的常用规则和用法了,我们来添加一个Chrome浏览器的小插件——XPath Helper,这个小插件可以大大提高了我们使用XPath的效率。
XPath Helper的添加与使用
XPath Helper的添加
首先打开Chrome商店搜索XPath Helper,如下图所示:
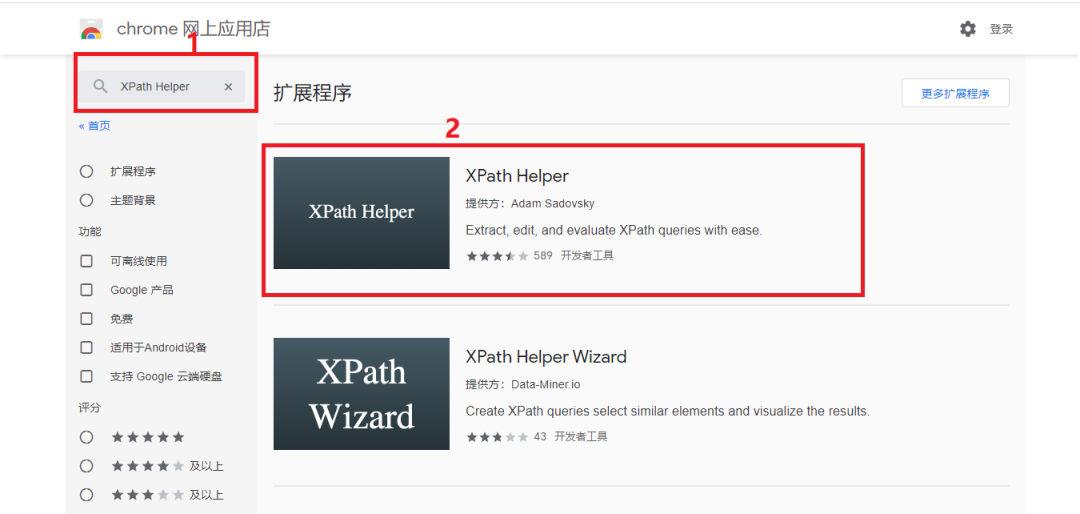
点击方框2,将插件添加至Chrome中,如下图所示:
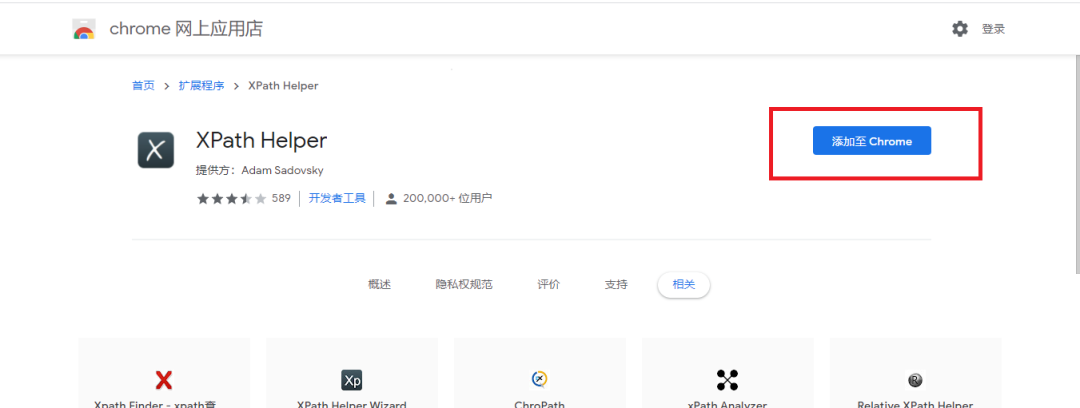
这里我们推荐点击下图的小图钉,更方便我们使用XPath Helper插件
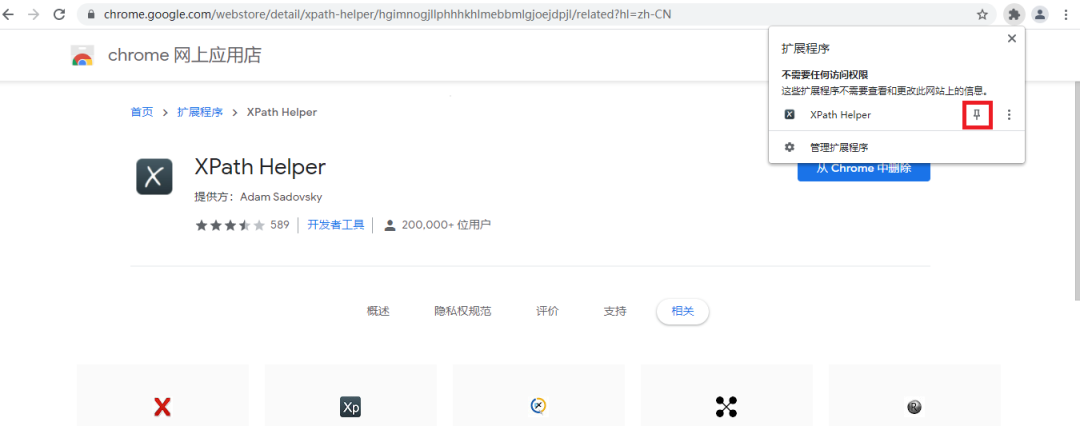
这样XPath Helper插件就添加完毕了,接下来我们简单演示一下如何使用该插件。
XPath Helper的使用
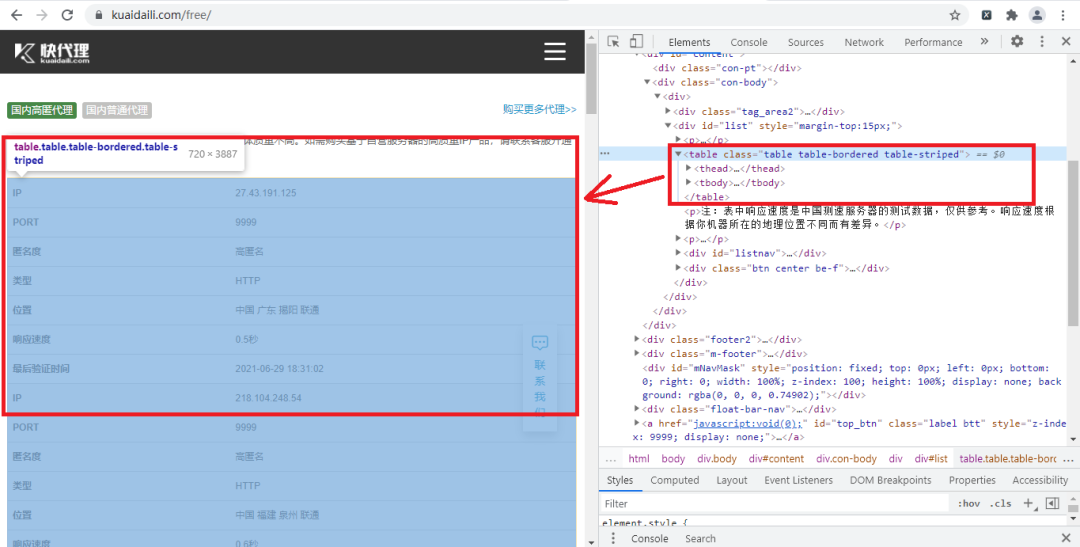
首先我们打开今天要爬取的快代理网站并打开开发者工具,找到我们要爬取内容的节点,如下图所示:
然后打开我们添加的插件,并输入XPath规则,如下图所示:
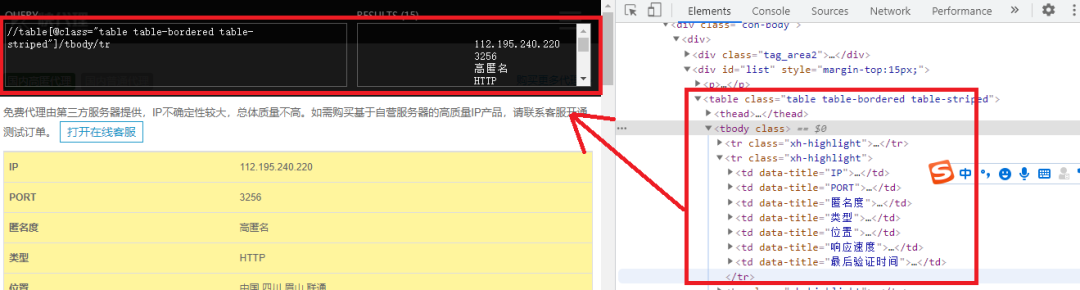
我们根据了table节点信息,来构造了XPath规则,输入XPath规矩可以直接看到返回的是什么,这样我们就不需要每构成一次就在程序里运行看看能不能返回我们想要的值,这样大大提高我们的效率。
实战演练
爬取首页
我们首先打开快代理免费代理网站并打开开发者工具,如下图所示:
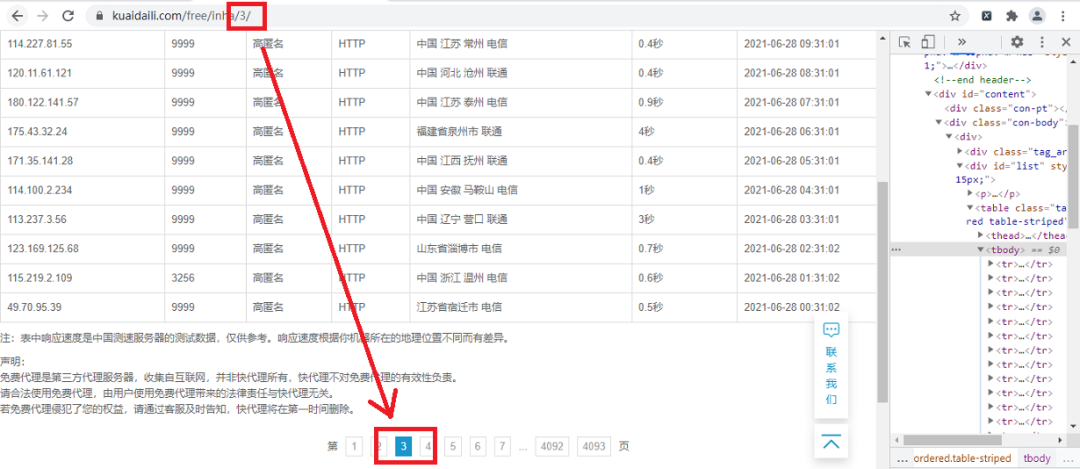
通过观察可以发现,页面的URL最后的那个数字就是页码,也就是我们进行翻页的重要参数,这里我们使用了page变量为我们翻页的参数,具体代码如下:
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.106 Safari/537.36'
}
def get_page(page):
url='https://www.kuaidaili.com/free/inha/'+str(page)
response=requests.get(url,headers=headers)
#数据类型转换
html = parsel.Selector(response.text)
parse_page(html)
首先我们构造了一个请求头,然后定义了一个get_page()方法,这里要注意的是,当我们获取了请求页面的文本数据时,要进行数据类型的转换,转换为XPath可以查找信息的HTML文本,也就是创建了一个parsel.Selector对象,转换后,我们就调用parse_page()方法,并传入html参数。
XPath规则提取内容
我们已经成功提取了网页的HTML文本,接下来我们开始利用XPath规则来提取想要的内容,首先我们要确定XPath规则提取内容的范围,如下图所示:
从图中我们可以看到table节点里包含我们要提取内容,然后我们使用XPath Helper插件来方便我们确定是否能准确提取目标内容,如下图所示:
图中的方框就是我们要提取内容的范围,确定范围后,我们确定提取内容对应的XPath规则,如下图所示:
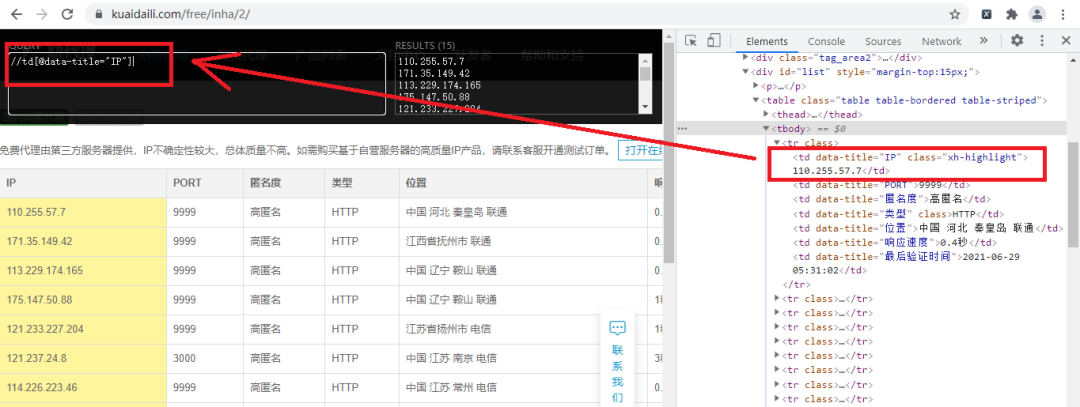
好了,我们成功提取到了IP地址,经过观察,我们只要把图中左上角的方框中IP改为PORT,这样就可以提取到了端口号了,具体实现代码如下:
def parse_page(html):
#XPath的匹配范围
parse_list = html.xpath('//table[@class="table table-bordered table-striped"]/tbody/tr')
for tr in parse_list:
parse_lists = {}
http=tr.xpath('./td[@data-title="类型"]//text()').extract_first()
num=tr.xpath('./td[@data-title="IP"]//text()').extract_first()
port=tr.xpath('./td[@data-title="PORT"]//text()').extract_first()
parse_lists[http]=num+':'+port
time.sleep(0.1)
print(parse_lists)
要注意的是:
我们在构造XPath规则时,如://td[@data-title="IP"],我们要将最前面的/改为.,否则只匹配页面的第一个内容; 在XPath规则中,通过使用text()方法获取节点内部的文本,如在规则后面加//text(); 调用extract_first()返回的是一个string字符串,是list数组里面的第一个字符串。
最后我们通过构造一个parse_lists字典,来使我们的数据更好看。
循环遍历
我们使用一个for循环,来遍历翻页,具体代码为:
if __name__ == '__main__':
for page in range(1,3):
get_page(page)
好了,这样我们就成功爬取了快代理的免费代理IP的前两页,我们可以根据需要来进行保存免费代理IP。
结果展示
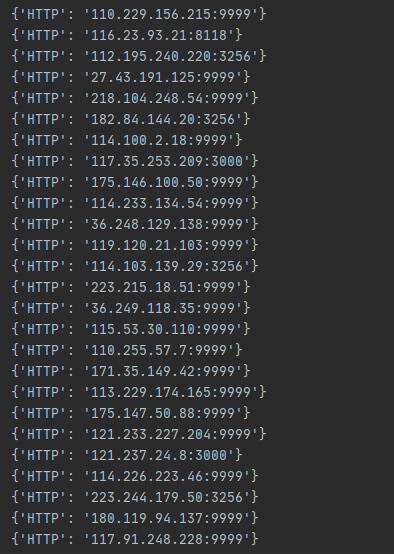
代码获取
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两个吧~