
手把手教你爬取美国疫情实时数据

作者:刘早起早起
来源:早起python
大家好,最近一直有读者在后台留言说早起能不能写一下怎么获取国外的疫情数据、美国疫情数据怎么爬之类的。为了满足各位,今天就说一下如何爬取美国疫情数据。

废话不多说,直接开始,只需一台电脑,按照下面的顺序一步一步执行,爬不下来数据你打我,文末不提供源码,源码一字不少全在文中。首先感谢读者@荷月十九提供的目标网站(不然我肯定直接找个API )
)
https://coronavirus.1point3acres.com/?code=001XKpTM0fAHk92cYwUM0iSrTM0XKpTF打开这个网站,会吧
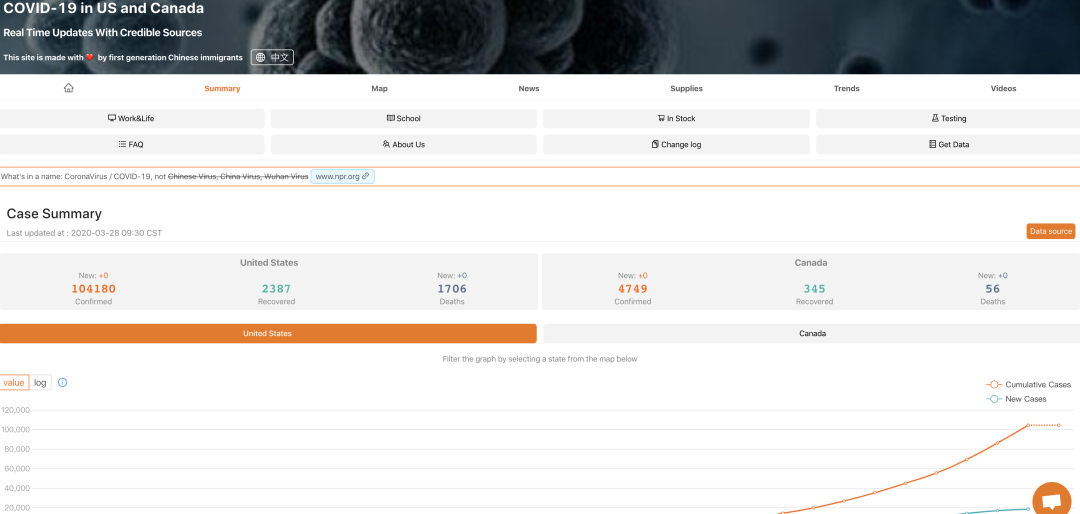
长这样?但是我们需要拿的数据是?
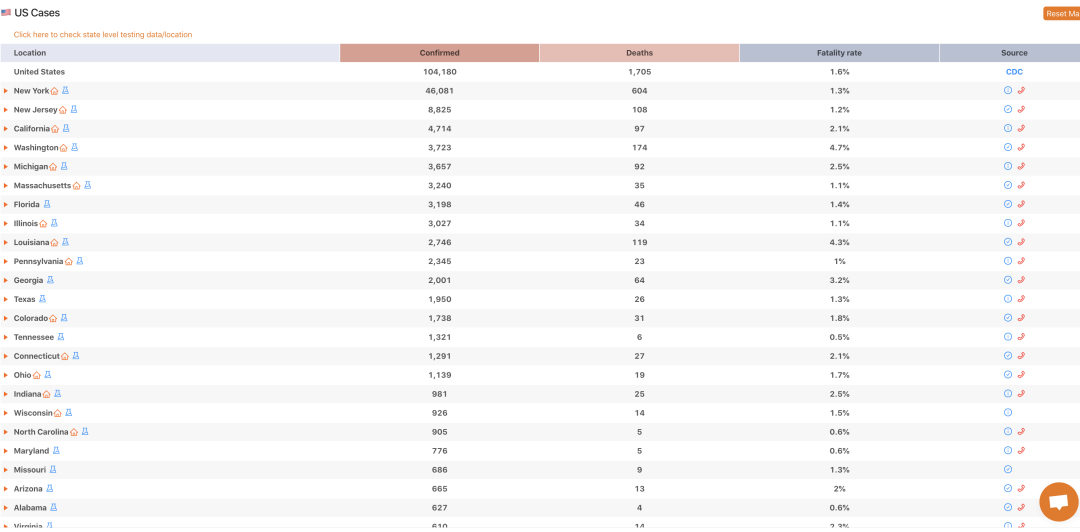
现在目标很明确,把上面这一堆数据取下来,下面有请Python出场
打开Notebook,导入以下包
import requests
import json
import re
import pandas as pd
from bs4 import BeautifulSoup如果有人留言怎么打开,怎么导入我会直接当场去世,接着设置下URL和headers,不用F12,URL就是上面的URL
url = 'https://coronavirus.1point3acres.com/?code=001XKpTM0fAHk92cYwUM0iSrTM0XKpTF'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}这两句复制粘贴执行谢谢,我们继续,下一步直接请求数据
res = requests.get(url,headers=headers)这一句就是使用Requests使用get方法向服务器请求数据,我们来看一下返回的值
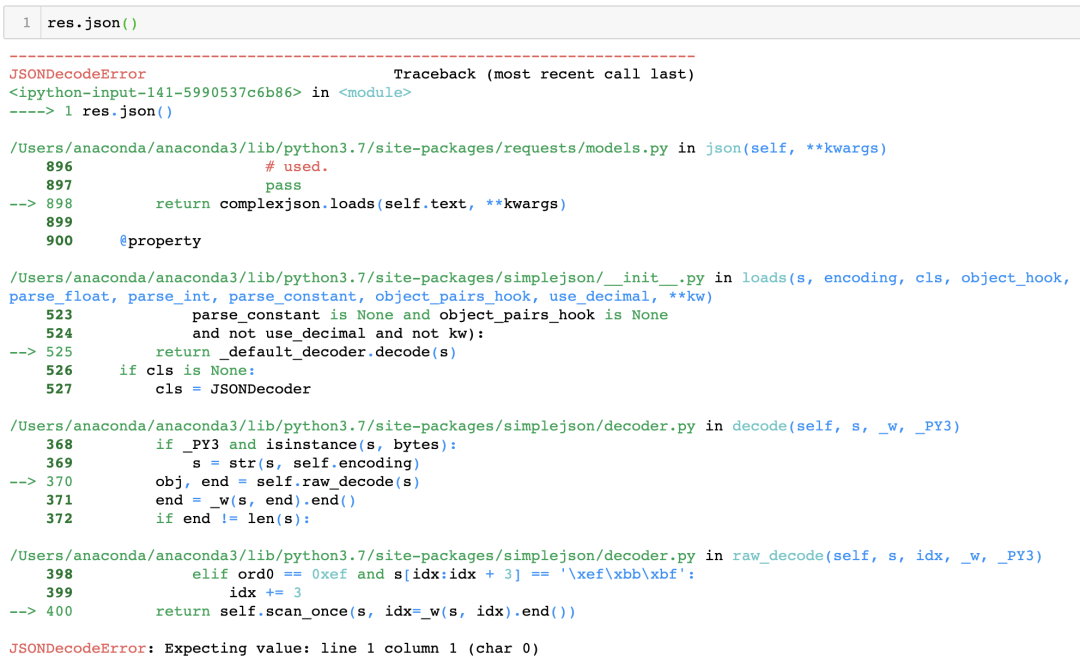
哦豁,报错了,从报错代码来看说明返回的并不能解析为json数据,没事不慌,bs4登场,我们用美丽的汤试试
soup = BeautifulSoup(res.text)
soup
搞定?,接下来干嘛?我们想要的数据都在这汤(soup)里了,取出来不就完事了,这时候F12就不得不登场了,回到浏览器刚刚的页面按下F12
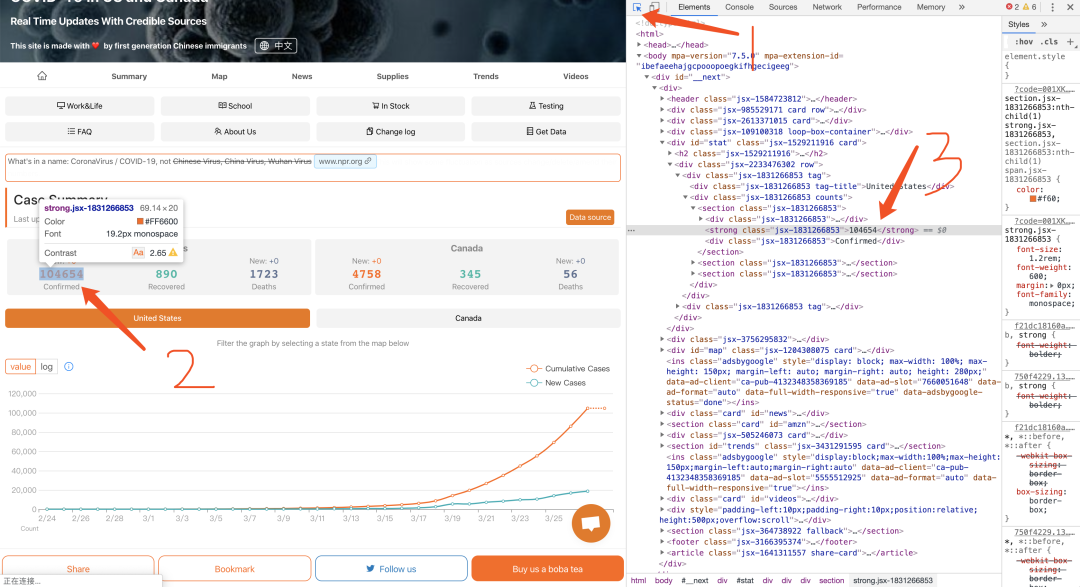
为了再照顾一下不熟悉的读者,我已经标注了你F12之后要干嘛,先点击位置1处的小箭头,它就变成了蓝色,再点击页面中美国确诊的总人数的数字,你戳它一下,右边的页面就会自动定位到前端页面中该数字的位置,从标注3中可以看到这个数字被存储在一个名为strong的标签中,并且class属性为jsx-1831266853,OK请执行下面代码
t = soup.find_all('strong', class_="jsx-1831266853")
这段代码具体是什么意思呢?就是从soup中找标签为'strong',class为"jsx-1831266853"的内容?

返回了一个list,我们要的数据都在里面,拿总确诊人数来说,怎么取出来?
total_confirmed = int(t[0].text)上面这行代码不难看懂吧,首先取出t的第0个位置元素,再用.text函数取出中间的数字,再将这个数字转换为int,这不就把美国确诊总人数取出来了吗。不过话说这有啥用啊,自己百度也能得到啊,别急,我们再把各个州的数据拿下
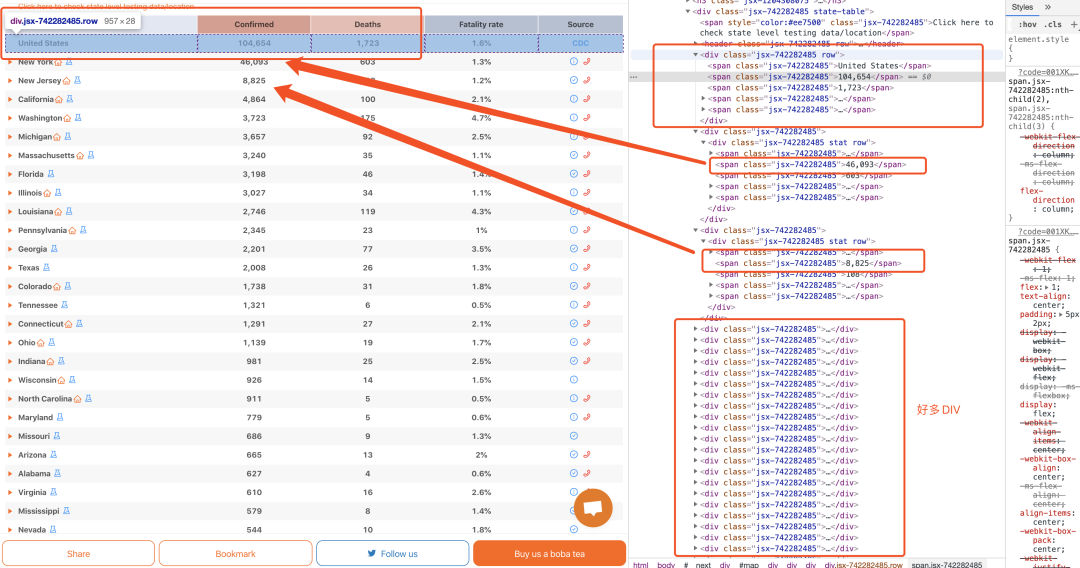
让我们故技重施?,回到浏览器页面中,F12定位到各个州的位置,戳一下看看数据存储在哪些标签中,看不懂的话回去看上一张图,结果我们发现好多div啊,点开一个就是一行数据,再观察观察发现每一行的数据都被一个属性是class="jsx-742282485 stat row"的标签包住?
下面就好办了,使用soup故技重施?
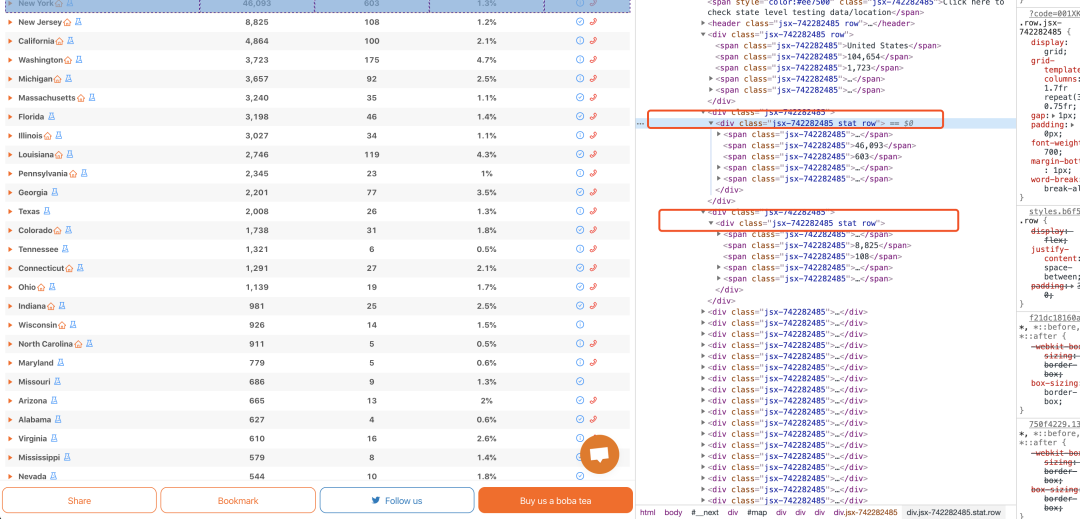
s = soup.find_all('div', class_="jsx-742282485 stat row")不难理解吧,将所有含属性是class="jsx-742282485 stat row"的div标签取出来,来看下结果
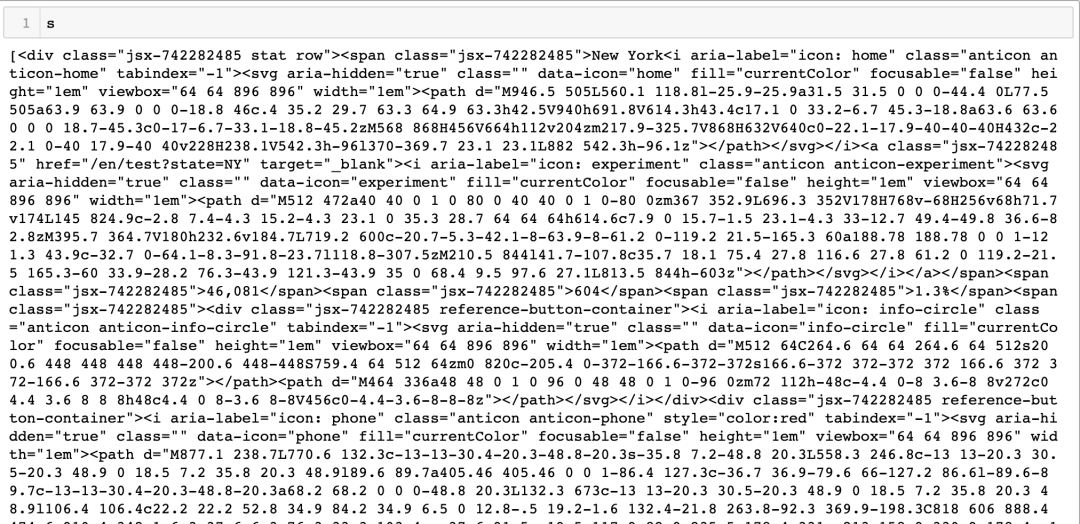
有点乱,但是不用慌我们通过len(s)可以发现返回的list长度为57,而上面刚好有57行(不用数了,我已经数过了),所以这57行的数据都在里面了,不用慌,一行一行取呗。
我们先尝试取出第一行的数据,看看套路是什么,搞定了写一个循环不就完事了。所以再回去浏览器看看第一行的数据怎么存储的?
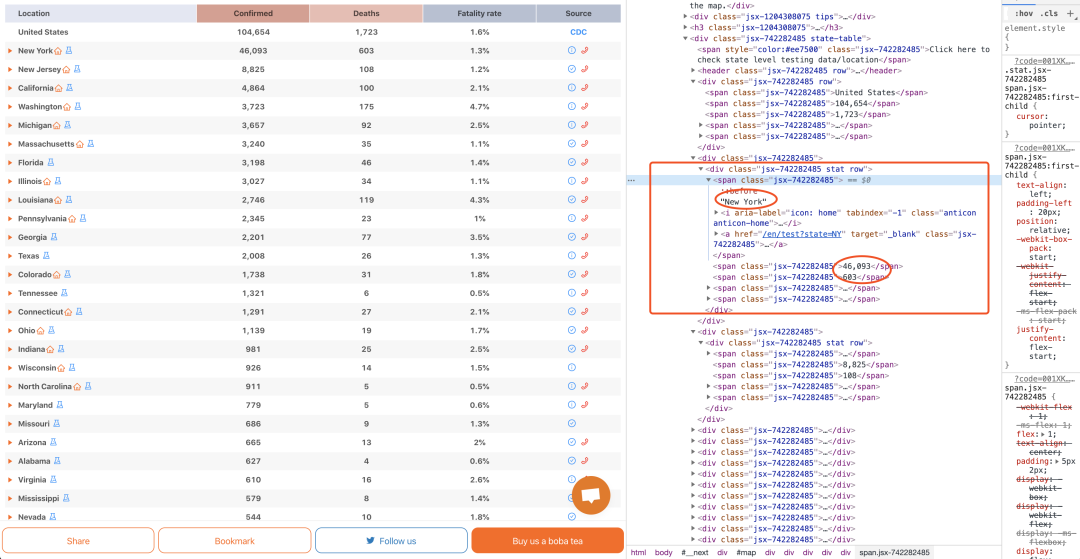
可以看到,我们刚刚取出了57个div标签,一个div标签里面有5个span,而前4个span中分别存储了州名、确诊、死亡、致死率,所以我们的思路就对每一个div取出这4个span中的内容,先取第一行?
name = s[0].find_all('span')[0].text
k = s[0].find_all('span')[1].text
confirmed = (int(re.findall(r"\d+\.?\d*",k)[0])*1000 + int(re.findall(r"\d+\.?\d*",k)[1])) if ',' in k else int(k)
deaths = int(s[0].find_all('span')[2].text)
rate = s[0].find_all('span')[3].text等等,4个数据为什么要5行,有没有注意到,确诊数据由于比较大,比如纽约确诊人数是46093,但是网页里面是46,093,多了一个,这个,会导致我们之后可视化不方便。所以使用两行代码来解决这个问题?
k = s[0].find_all('span')[1].text
confirmed = (int(re.findall(r"\d+\.?\d*",k)[0])*1000 + int(re.findall(r"\d+\.?\d*",k)[1])) if ',' in k else int(k)我稍微解释下,第一行把数字取出来是这样46,093,第二行先用正则表达式取出数字再拼接成正常的格式,如果看不懂也没关系,这不是本期重点,总之这两行就是把数字整理下
好了,到这里基本就算结束了,接下来我们创建一个空dataframe
df = pd.DataFrame(columns= ['Location','Confirmed','Deaths','Fatality rate'])
最后写一个循环重复执行刚刚的操作就搞定
for i in range(len(s)):
name = s[i].find_all('span')[0].text
k = s[i].find_all('span')[1].text
confirmed = (int(re.findall(r"\d+\.?\d*",k)[0])*1000 + int(re.findall(r"\d+\.?\d*",k)[1])) if ',' in k else int(k)
deaths = int(s[i].find_all('span')[2].text)
rate = s[i].find_all('span')[3].text
data = [name,confirmed,deaths,rate]
df.loc[i] = data上面这个也不难看懂把,对每一行取出数据并存到dataframe中,如果看不懂那你一定没做过Pandas120题系列,我们来看下最终取到的数据
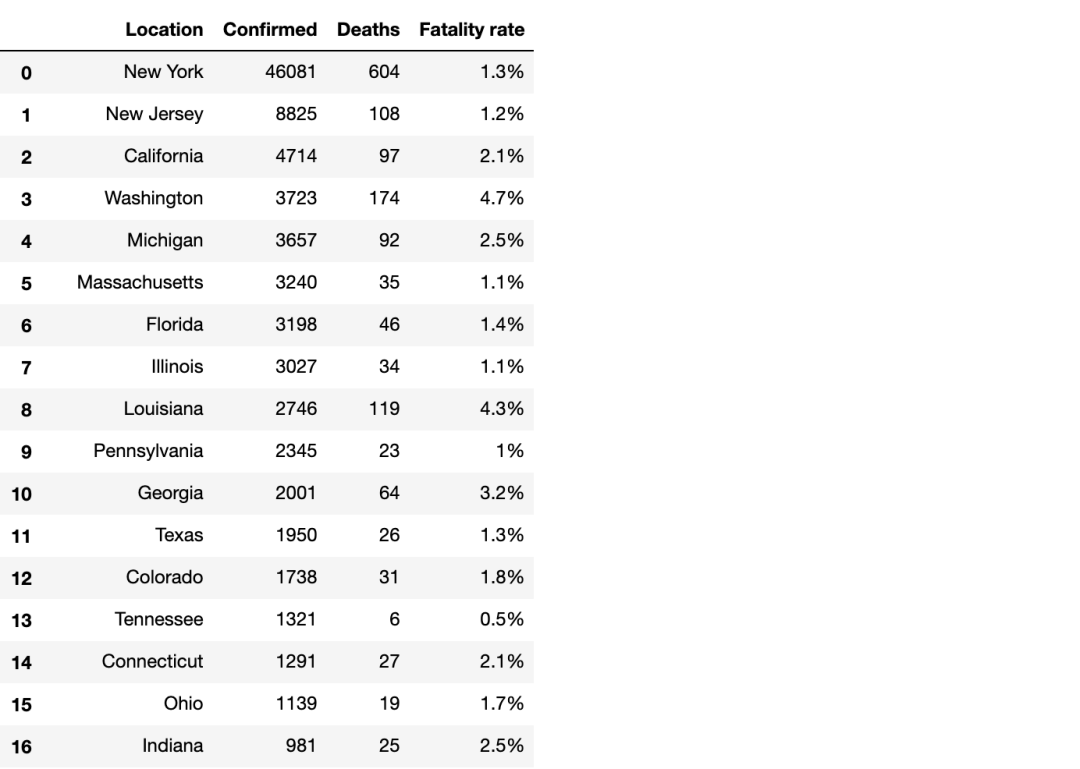
登登登登,美国各个州的疫情数据就成功取下来了,最后可以使用df.to_excel('filename.xlsx')存储到本地。
以上就是爬取美国疫情数据的全部过程,也不难吧!如果需要这个页面中更多的数据完全可以重复上述步骤,并且这个网站实时更新数据,如果定时执行就能获得时间序列数据,这些就不再多说了。拿到数据之后就能做一些分析可视化?

◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码: