
手把手带你爬虫 | 爬取语录大全
↑ 关注 + 星标 ,每天学Python新技能
后台回复【大礼包】送你Python自学大礼包
作者:大头雪糕
来源:数据分析与统计学之美
目标
爬取语录,批量下载到本地。
项目准备
软件:Pycharm
第三方库:requests,fake_useragent,re,lxml
网站地址:http://www.yuluju.com
网站分析
打开网站。

有很多分类,不同类型的语录。
点击爱情语录,发现上方网址变化为http://www.yuluju.com/aiqingyulu/
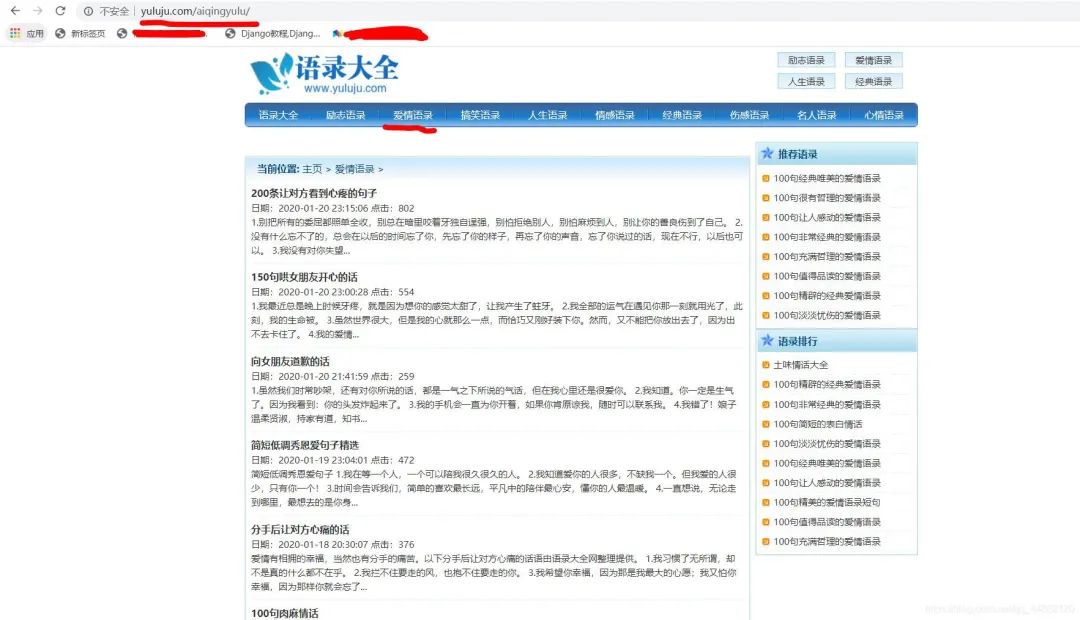
点击搞笑语录,也会发生类似的变化。
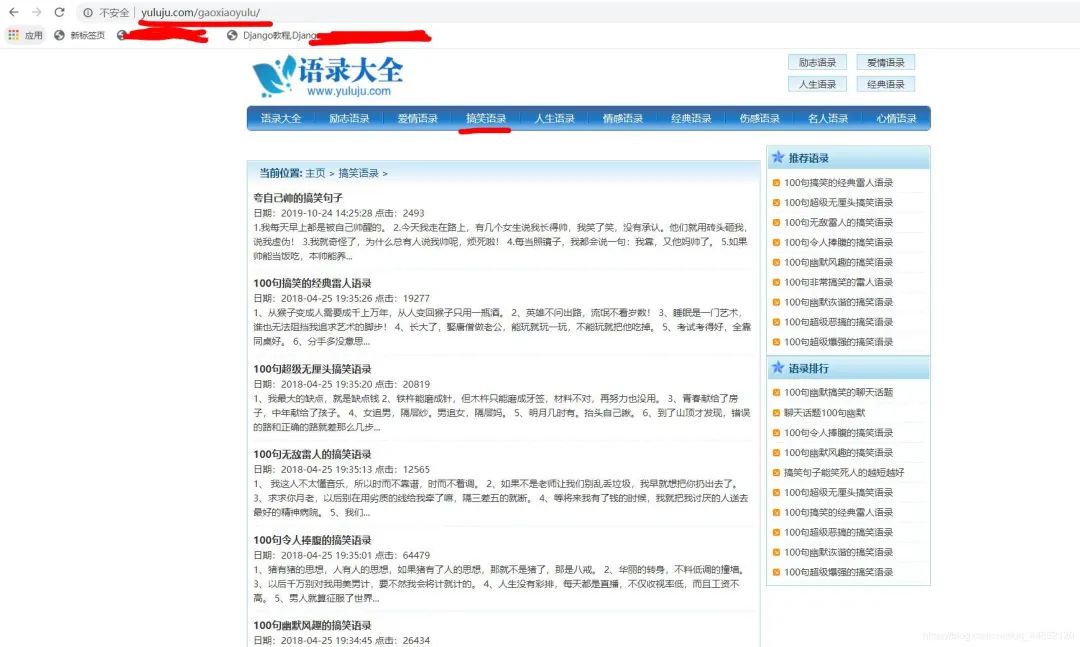
判断是否为静态网页。
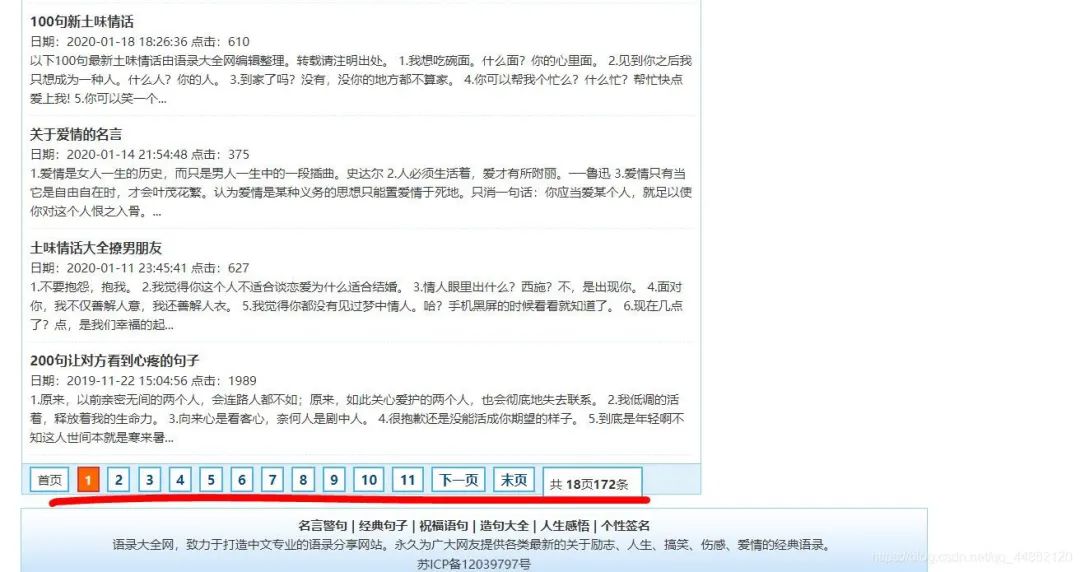
有页码跳转一般为静态网页。Ctrl+U查看源代码,Ctrl+F调出搜索框,输入一些网页上出现的文字。
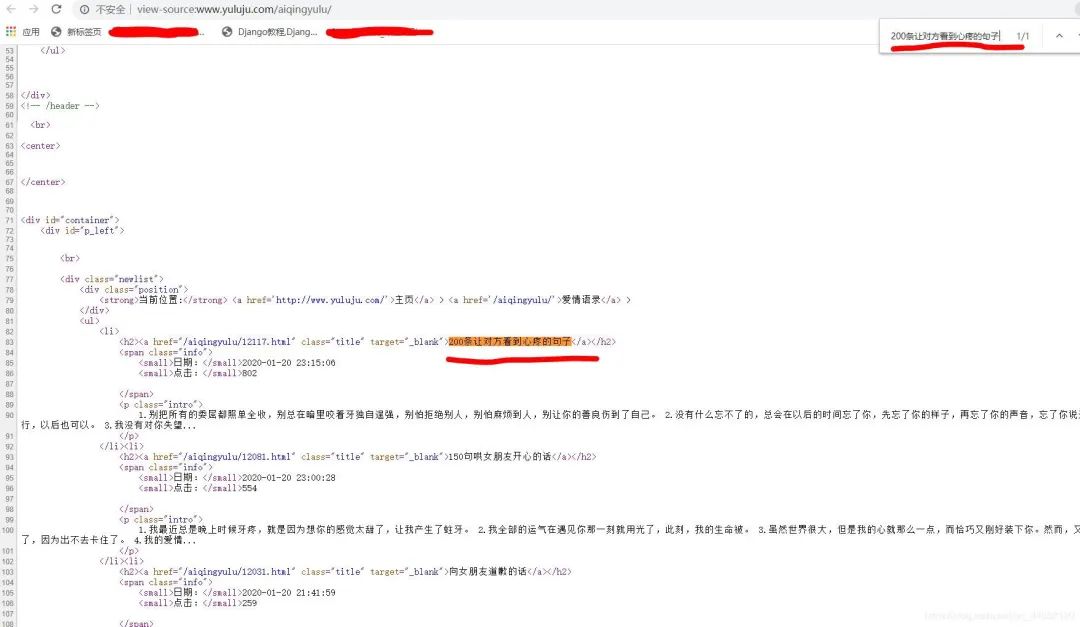
反爬分析
同一个ip地址去多次访问会面临被封掉的风险,这里采用fake_useragent,产生随机的User-Agent请求头进行访问。
每一页的链接分析
第一页:http://www.yuluju.com/aiqingyulu/list_18_1.html
第二页:http://www.yuluju.com/aiqingyulu/list_18_2.html
第三页:http://www.yuluju.com/aiqingyulu/list_18_3.html
可以发现,每页的变化会随着数字变化。当然这里分析的是爱情语录这一栏目,其它的也类似。
代码实现
1.导入相对应的第三方库,定义一个class类继承object,定义init方法继承self,主函数main继承self。
import requests
from fake_useragent import UserAgent
from lxml import etree
class yulu(object):
def __init__(self):
self.url = 'http://www.yuluju.com'
ua = UserAgent(verify_ssl=False)
#随机产生user-agent
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def mian(self):
pass
if __name__ == '__main__':
spider = yulu()
spider.main()
2.交互界面
print(' 1.励志语录\n'
'2.爱情语录\n'
'3.搞笑语录\n'
'4.人生语录\n'
'5.情感语录\n'
'6.经典语录\n'
'7.伤感语录\n'
'8.名人语录\n'
'9.心情语录\n')
select=int(input('请输入您的选择:'))
if (select==1):
url=self.url+'lizhimingyan/list_1_{}.html'
elif (select==2):
url = self.url + 'aiqingyulu/list_18_{}.html'
elif (select==3):
url = self.url + 'gaoxiaoyulu/list_19_{}.html'
elif (select==4):
url=self.url+'renshenggeyan/list_14_{}.html'
elif (select==5):
url=self.url+'qingganyulu/list_23_{}.html'
elif (select==6):
url=self.url+'jingdianyulu/list_12_{}.html'
elif (select==7):
url=self.url+'shangganyulu/list_21_{}.html'
elif (select==8):
url=self.url+'mingrenmingyan/list_2_{}.html'
else:
url=self.url+'xinqingyulu/list_22_{}.html'
3.发送请求,获取网页。
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.content.decode('gb2312')#经过测试这里是'gb2312'
return html
4.解析网页,获取文本信息。
def parse_html(self,html):
#获取每页中的链接地址和标题
datas=re.compile('(.*?)' ).findall(html)
for data in datas:
host='http://www.yuluju.com'+data[0]
res=requests.get(host,headers=self.headers)
con=res.content.decode('gb2312')
target=etree.HTML(con)
#获取文本内容
results=target.xpath('//div[@class="content"]/div/div/span/text()')
filename=data[1]
#保存本地
with open('F:/pycharm文件/document/'+filename+'.txt','a',encoding='utf-8')as f:
for result in results:
f.write(result+'\n')
5.获取多页及主函数调用。
def main(self):
print('1.励志语录\n'
'2.爱情语录\n'
'3.搞笑语录\n'
'4.人生语录\n'
'5.情感语录\n'
'6.经典语录\n'
'7.伤感语录\n'
'8.名人语录\n'
'9.心情语录\n')
select=int(input('请输入您的选择:'))
if (select==1):
url=self.url+'lizhimingyan/list_1_{}.html'
elif (select==2):
url = self.url + 'aiqingyulu/list_18_{}.html'
elif (select==3):
url = self.url + 'gaoxiaoyulu/list_19_{}.html'
elif (select==4):
url=self.url+'renshenggeyan/list_14_{}.html'
elif (select==5):
url=self.url+'qingganyulu/list_23_{}.html'
elif (select==6):
url=self.url+'jingdianyulu/list_12_{}.html'
elif (select==7):
url=self.url+'shangganyulu/list_21_{}.html'
elif (select==8):
url=self.url+'mingrenmingyan/list_2_{}.html'
else:
url=self.url+'xinqingyulu/list_22_{}.html'
start = int(input('输入开始:'))
end = int(input('输入结束页:'))
for page in range(start, end + 1):
print('第%s页开始:...' % page)
newUrl=url.format(page)
html=self.get_html(newUrl)
self.parse_html(html)
print('第%s页爬取完成!'%page)
效果显示
 打开文件目录:
打开文件目录:
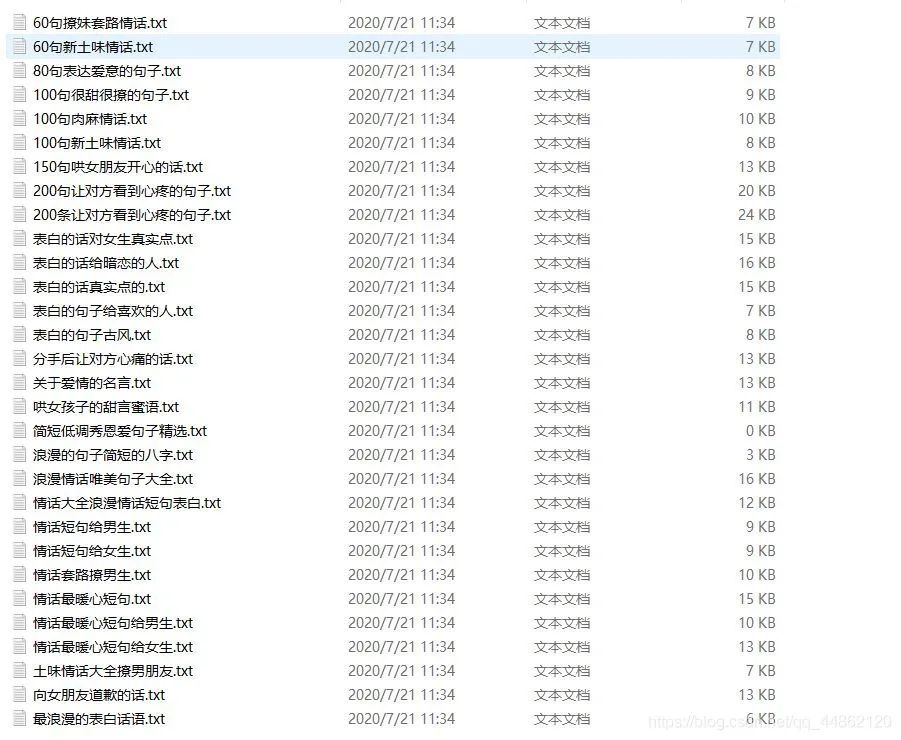
爬取其它栏目也是可以的,就不做演示了,都一样。
完整代码
import requests
from fake_useragent import UserAgent
import re
from lxml import etree
class yulu(object):
def __init__(self):
self.url='http://www.yuluju.com/'
ua = UserAgent(verify_ssl=False)
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.content.decode('gb2312')
return html
def parse_html(self,html):
datas=re.compile('(.*?)' ).findall(html)
for data in datas:
host='http://www.yuluju.com'+data[0]
res=requests.get(host,headers=self.headers)
con=res.content.decode('gb2312')
target=etree.HTML(con)
results=target.xpath('//div[@class="content"]/div/div/span/text()')
filename=data[1]
with open('F:/pycharm文件/document/'+filename+'.txt','a',encoding='utf-8')as f:
for result in results:
f.write(result+'\n')
def main(self):
print('1.励志语录\n'
'2.爱情语录\n'
'3.搞笑语录\n'
'4.人生语录\n'
'5.情感语录\n'
'6.经典语录\n'
'7.伤感语录\n'
'8.名人语录\n'
'9.心情语录\n')
select=int(input('请输入您的选择:'))
if (select==1):
url=self.url+'lizhimingyan/list_1_{}.html'
elif (select==2):
url = self.url + 'aiqingyulu/list_18_{}.html'
elif (select==3):
url = self.url + 'gaoxiaoyulu/list_19_{}.html'
elif (select==4):
url=self.url+'renshenggeyan/list_14_{}.html'
elif (select==5):
url=self.url+'qingganyulu/list_23_{}.html'
elif (select==6):
url=self.url+'jingdianyulu/list_12_{}.html'
elif (select==7):
url=self.url+'shangganyulu/list_21_{}.html'
elif (select==8):
url=self.url+'mingrenmingyan/list_2_{}.html'
else:
url=self.url+'xinqingyulu/list_22_{}.html'
start = int(input('输入开始:'))
end = int(input('输入结束页:'))
for page in range(start, end + 1):
print('第%s页开始:...' % page)
newUrl=url.format(page)
html=self.get_html(newUrl)
self.parse_html(html)
print('第%s页爬取完成!'%page)
if __name__ == '__main__':
spider = yulu()
spider.main()
◆ ◆ ◆ ◆ ◆
推荐阅读
太惨了!!!这9名程序员开发50余款APP获利500万,结果...
扫码回复「大礼包」后获取大礼
扫码加我微信备注「三剑客」送你上图三本电子书
评论