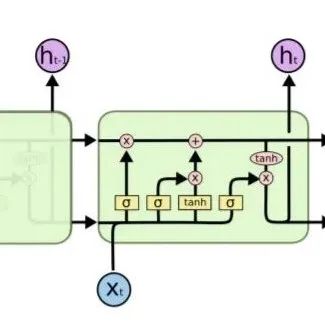
数据不平衡问题都怎么解?

作者 | Chilia
整理 | NewBeeNLP
本文主要讨论两种不平衡问题。
- 一是数据的类别本来就不平衡,比如在广告CTR预估中,可能90%的广告都不会被点击,只有一少部分被点击;
- 二是由于误分类cost的不对称性(asymmetric cost),例如把non-spam 分成spam的代价要远大于把spam分成non-spam。
在这篇文章中,我将介绍两大类方法:一是通过采样而改变数据集,二是修改训练策略。
1. 从数据层面解决 – 重采样 (Resampling)
1.1 随机欠采样(Random Under-Sampling)
通过随机删除多数类别的样本来平衡类别分布。
好处:
- 当训练数据集很大时,可以通过减少训练数据样本的数量来帮助改善运行时间和存储问题
缺点:
- 丢弃可能有用的信息
- 随机欠采样选择的样本可能是有偏差的样本, 它不会是整体分布的准确代表。因此,可能导致实际在测试集上的结果不准确
1.2 随机重采样(Random Over-Sampling)
通过「随机重复取少数类别的样本」来平衡类别分布。
好处
- 与欠采样不同,此方法不会导致信息丢失。此方法优于随机欠采样
缺点
- 重复取少数类别的样本,因此增加了过拟合的可能性。
1.3 Ensemble 采样
类似bagging的思想,有多个基学习器,每个基学习器都抽取一部分majority class,并且使用全部的minority class。这样,每个majority样本都能够被利用上,不会有信息的损失。
1.4 合成少数类过采样技术 (Synthetic Minority Over-sampling Technique, SMOTE)
此方法用来解决直接复制少数类样本导致的过拟合问题。SMOTE算法的基本思想是对少数类样本进行分析并根据少数类样本人工合成新样本添加到数据集中。
该算法的模拟过程采用了KNN技术,模拟生成新样本的步骤如下:
- 计算出每个少数类样本的K个近邻;
- 从K个近邻中随机挑选N个样本进行随机线性插值,从而构造新的少数类样本;
- 将新样本与原数据合成,产生新的训练集;
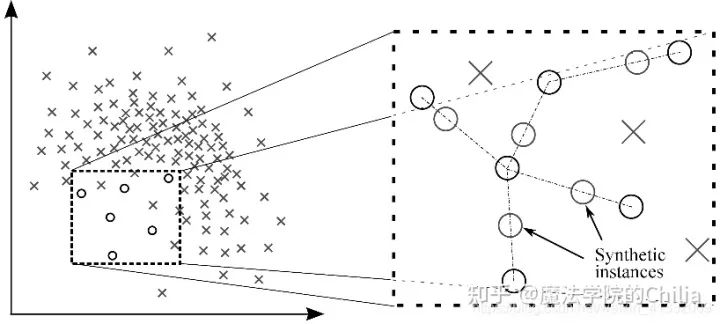
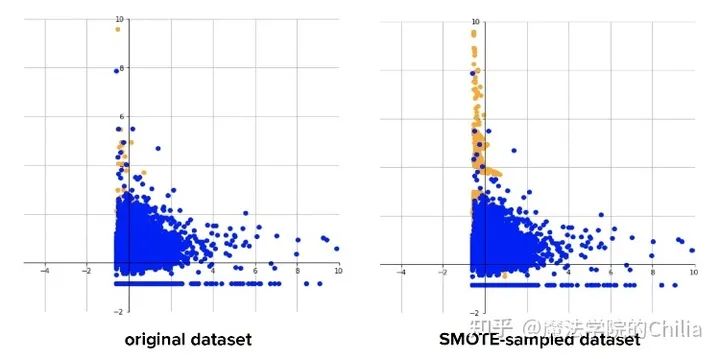 黄色点:minority;蓝色点:majority
黄色点:minority;蓝色点:majority2 从算法层面解决
2.1 改变loss的权重
重采样方法改变了数据集,可能导致数据集变得太大,或者丢弃了一些信息。所以,有没有一种方法能够从算法层面解决类别不平衡问题呢?
实际上,可以通过改变loss的方法来实现。对分类器的小类样本数据增加loss权值,降低大类样本的权值,从而使得分类器将重点集中在小类样本身上。具体做法就是,在训练分类器时,若分类器将小类样本分错时额外增加分类器一个小类样本分错代价,这个额外的代价可以使得分类器更加“关心”小类样本。
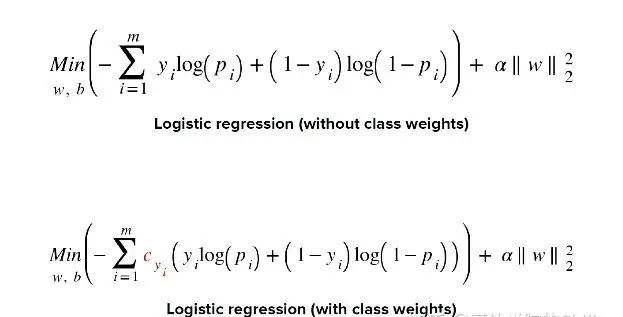 可以让majority的权重为1,minority权重为3
可以让majority的权重为1,minority权重为3 树模型
树模型2.2 boosting 方法
在boosting方法中,分类器每一步会关心上一步分错的那些样本,这样分类器就会越来越关心少数类样本,把它们的权值提高。久而久之,就能够将少数样本正确分类了。
三句话不离本行
在搜索、推荐、广告的实际场景下,怎么选择正负样本也是大有讲究。
对于召回阶段,一般初始的训练集是只有正样本的。什么样的样本被选作正样本,这个标准在每个公司都不一样。
例如,facebook在其最新的文章 Que2Search: Fast and Accurate Query and Document Understanding for Search at Facebook中提到,他们选择正样本标准十分严格:对于一个query,只有当用户点击了一个product,进去和卖家聊天,卖家还回复了,这才算一个正样本。
但是在其另外一篇文章Embedding-based Retrieval in Facebook Search中却提到,其实可以把用户点击的商品都算作正样本。这是因为其实召回可以看作排序阶段的一个近似,我们只需要快速的把和query相关的物品都拿出来。
那么召回阶段的负样本怎么来呢?在实际的数据流场景中,一般是用in-batch采样,但是这样有一个问题:越热门的商品,越容易出现在batch中,所以越容易成为负样本。这样,就对热门商品施加了不必要的惩罚。
为了解决这个问题,Google在Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations一文中提出streaming frequency estimation方法。其实还有一些负采样方法,比如难负例采样。还可以把in-batch采样与随机负采样相结合。这里的门道很多,之后会专门出专题介绍。
对于排序阶段,一般都是多目标预测,目标有是否点击、是否关注、是否购买、观看时长、评分等等(engagement & satisfaction),负样本就是那些曝光未点击的,由于曝光的商品本来就比较少了(相对召回阶段而言),所以数据不平衡没有那么严重。
一起交流想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)
本文参考:
- 哥伦比亚大学2021fall COMS 4995课件
- END -