
自监督学习简介以及在三大领域中现状

来源:Deephub Imba 本文约2000字,建议阅读5分钟
本文为你介绍了子监督学习的三大领域的现状。
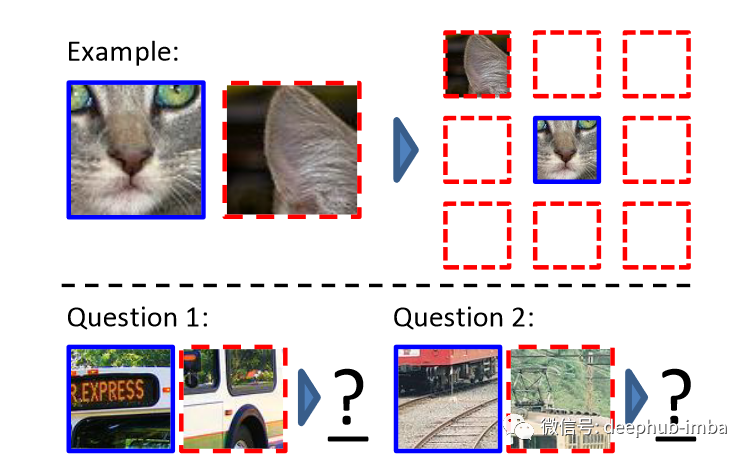
计算机视觉的自监督学习

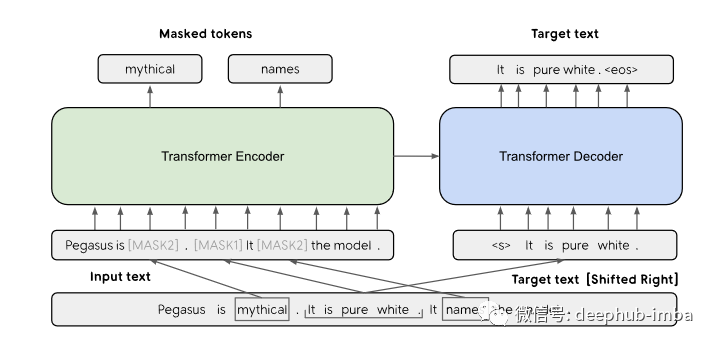
自然语言处理的自监督学习
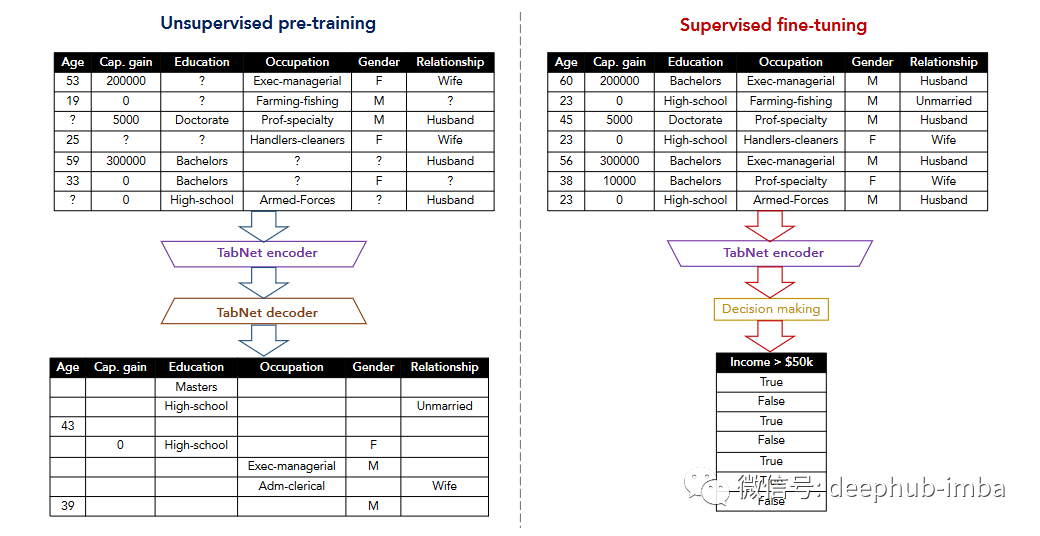
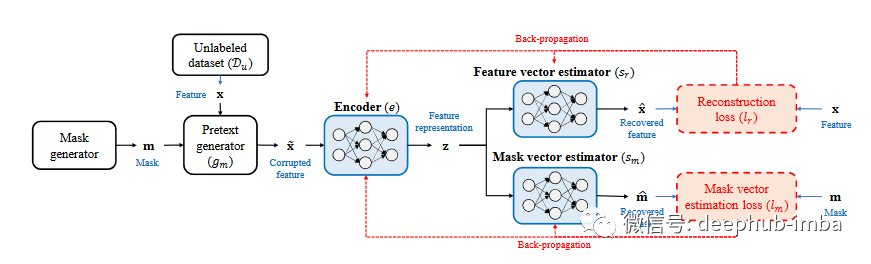
表格数据的自监督学习
总结
引用
[1] Richard Zhang, Phillip Isola, and Alexei A. Efros, Colorful image colorization (2016), In European conference on computer vision
[2] Carl Doersch, Abhinav Gupta, and Alexei A. Efros, Unsupervised visual representation learning by context prediction (2015), In Proceedings of the IEEE international conference on computer vision
[3] Longlong Jing, and Yingli Tian, Self-supervised visual feature learning with deep neural networks: A survey (2020), IEEE transactions on pattern analysis and machine intelligence
[4] Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu, Pegasus: Pre-training with extracted gap-sentences for abstractive summarization (2020), In International Conference on Machine Learning
[5] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and Pierre-Antoine Manzagol, Extracting and composing robust features with denoising autoencoders (2008), In Proceedings of the 25th international conference on Machine learning
[6] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros, Context encoders: Feature learning by inpainting (2016), In Proceedings of the IEEE conference on computer vision and pattern recognition
[7] Sercan Ö. Arik, and Tomas Pfister, Tabnet: Attentive interpretable tabular learning (2021), In Proceedings of the AAAI Conference on Artificial Intelligence
[8] Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Sebastian Riedel, TaBERT: Pretraining for Joint Understanding of Textual and Tabular Data (2020), In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
[9] Jinsung Yoon, Yao Zhang, James Jordon, and Mihaela van der Schaar, Vime: Extending the success of self-and semi-supervised learning to tabular domain (2020), Advances in Neural Information Processing Systems