
微博位置爬虫发布
点击上方 月小水长 并 设为星标,第一时间接收干货推送
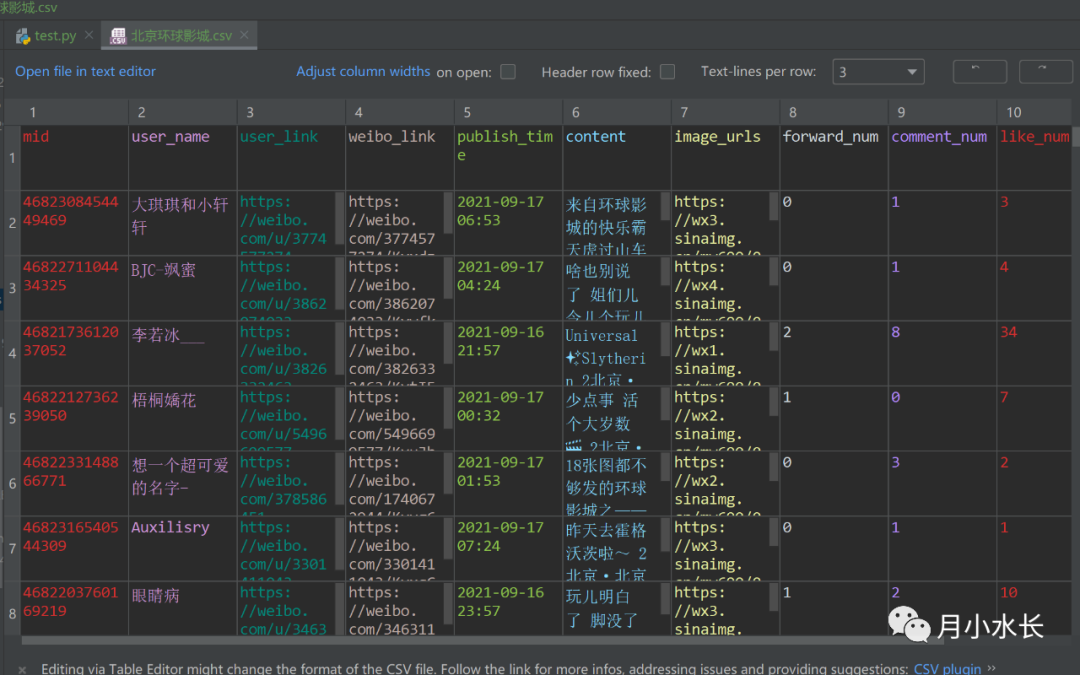
微博数据分析经常需要和地理位置相关联,比如查看某一话题爬虫下发博人员地理分布,或者用户爬虫下某人轨迹分布,等等;而这次的微博位置爬虫则是直接以位置为切入点爬取微博,只需要输入一个地名,就能抓取在该地点发过的微博具体信息,表结构类似话题爬虫。
这个位置爬虫的结果可以和用户信息爬虫联动,比如有这样一个分析任务:去北京环球影城的人,都发了什么微博,男生多还是女生多,年龄群体分布怎么样,等等。都可以先用这个微博位置爬虫,爬完后的 csv 交给用户信息爬虫处理。
闲话不多说,首先在本号(月小水长)后台回复关键词 微博位置爬虫 获取 pyd 文件(only for python3.6 64 bit),然后在新建一个 py 文件,引用这个 pyd 文件
from WeiboLocationSpider import WeiboLocationSpiderif __name__ == '__main__':WeiboLocationSpider(location_title='北京环球影城',cookie='改成你自己的 cookie',save_image=False)
首先是三个参数介绍,字面意思,第一个 location_title 就是你要爬的地名,必选;

https://weibo.com/p/100101B2094654D36EA5FF459E第三个 save_image 非必选,意思是是否保存爬取到的微博的图片,并且是微博原图,清晰度比较高,所以下载比较慢,所以为了快速抓取,默认值为 False,不保存,想要保存的话指定为 True 即可;河南暴雨超话时,很多信息是通过图片发布的,所以图片信息也很重要,可以通过 OCR 技术提取出文本,尝试了下,由于该微博保存的图片是原图,图片里面的文本信息几乎都能解析出来。
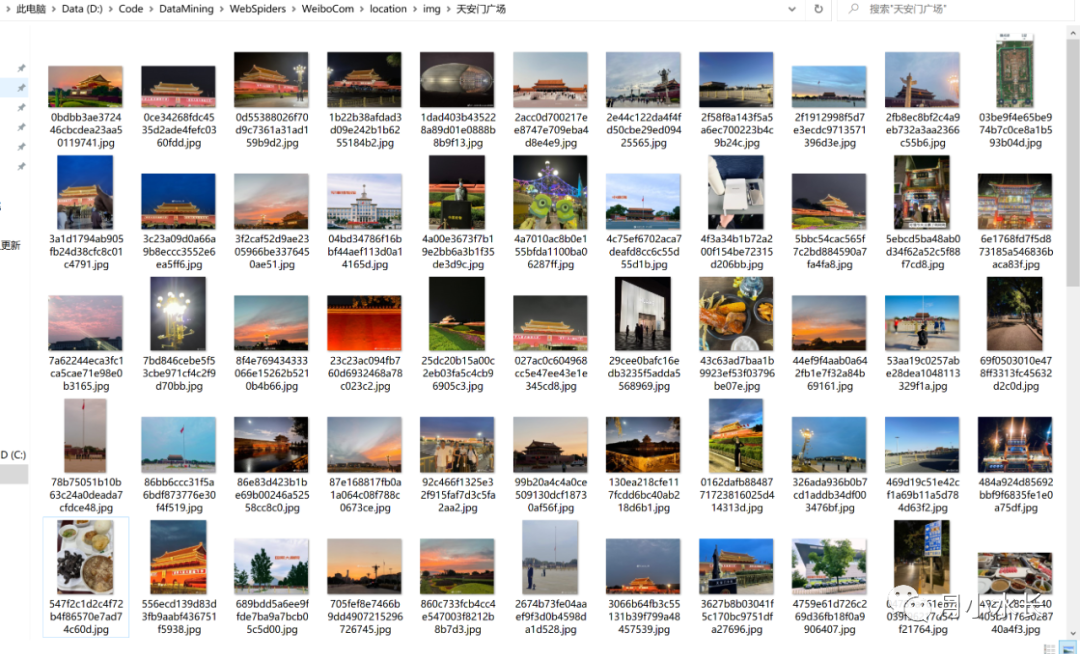
一个地点无论大小,最多只能爬到四位数左右的微博数据,想要爬到更多怎么办,可以拆分成很多小地点,比如爬北京,你可以改成海淀区、朝阳区等等,或者把海淀区按照街道再细分,这样就能爬到更多的位置微博数据。
这个位置爬虫报错会有一些提示信息,如果出现 List IndexError,一般是需要换 cookie 了,报错会同时保存配置信息,比如当前爬到哪一页了,换了 cookie 后可以继续爬取,自动保存的配置文件格式如下。
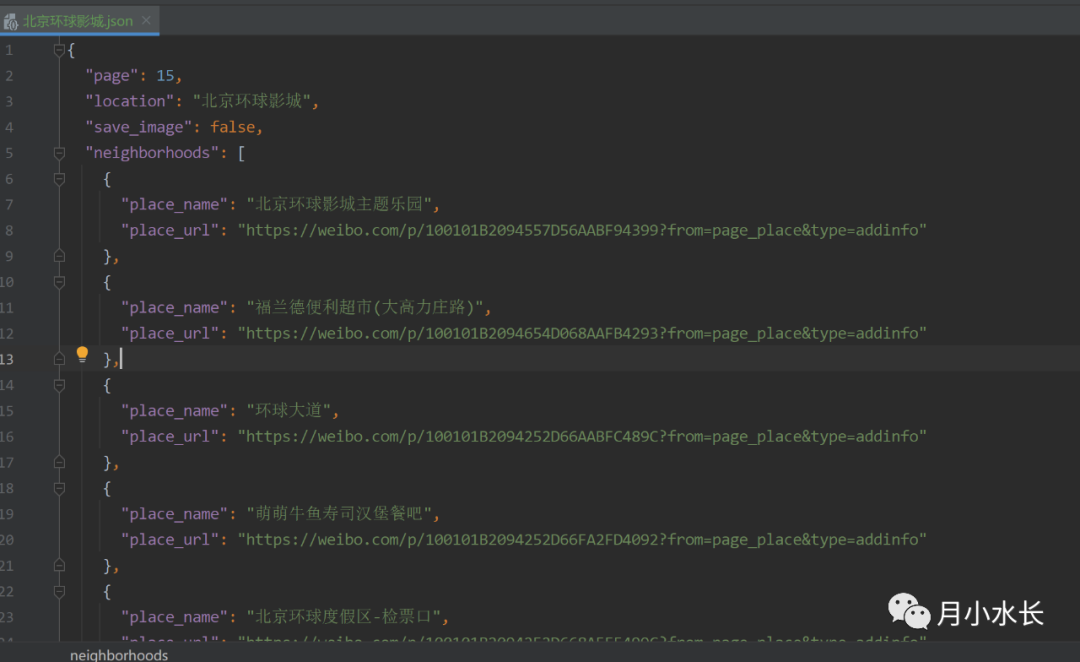
用想要抓取附近地点的 place_name 替代 location,比如 location 值改成 北京环球影城主题乐园
location 同级新增一个 page_root_url 字段,取值为上一步 place_name 对应的 place_url
把 page 改成 1
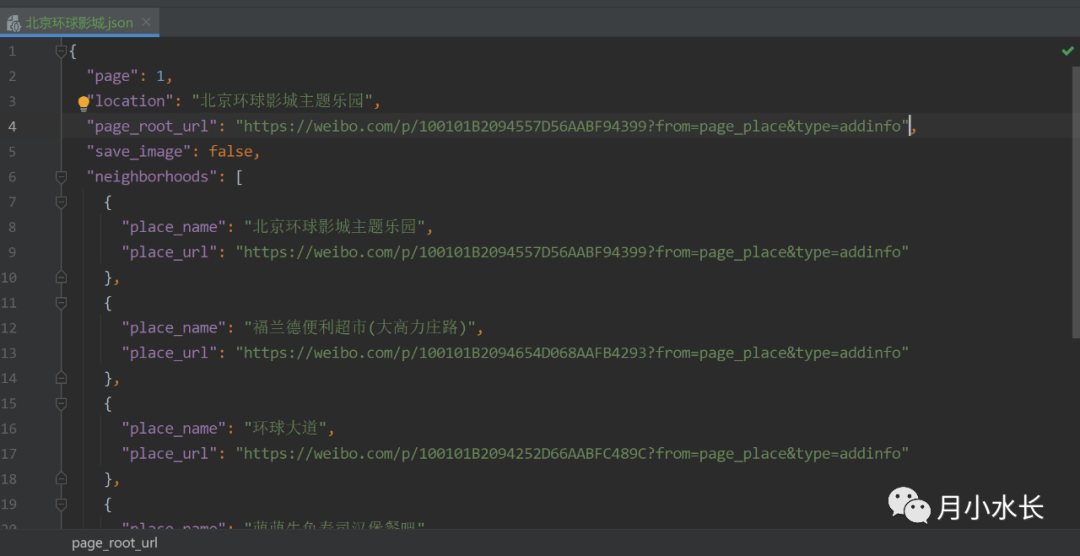
from WeiboLocationSpider import WeiboLocationSpiderif __name__ == '__main__':WeiboLocationSpider(location_title='北京环球影城主题乐园',cookie='改成你自己的 cookie',save_image=False)