
CVPR再度上演抄袭大戏!IBM中稿论文被指照搬自己承办竞赛第二名的idea

新智元报道
新智元报道
编辑:拉燕 好困
【新智元导读】CVPR再曝抄袭门!这次是「大厂直抄,很会包装」。IBM,在?来解释解释?
一波未平,一波又起,CVPR 2022又被曝出论文抄袭!
这两天,来自中国的研究团队发现,自己去年参加ICDAR竞赛的idea,竟然被IBM拿去投中了今年的CVPR。
而这件事最讽刺的一点在于,ICDAR 2021正是由IBM自己承办的。
目前,作者已经将相关举证信息发给了CVPR的Program Chairs。
这件事的热度还在发酵。Reddit上的讨论热度即将破千。

然而,挑战大厂的权威,又何谈容易呢。
作者自述
下面,让我们用第一人称,还原一下原作者的自述。感受一下原作者的愤怒和委屈。
「我叫Xianbiao Qi,在计算机视觉领域搞研究已经十多年了。我写这篇博客是为了揭露一起明目张胆的剽窃行为。IBM苏黎世研究院剽窃了我们的研究。」
「他们抄的不是文本内容,他们抄的是我们辛辛苦苦做出来的idea。」
Xianbiao Qi所说的论文是「PingAn-VCGroup's Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B: Table Recognition to HTML」,于2021年6月上传至arXiv,合作者有Jiaquan Ye, Xianbiao Qi和Yelin He等人。
此外,代码也一并进行了开源。

论文地址:https://arxiv.org/abs/2105.01848
而抄袭团队则是来自IBM苏黎世研究院的Ahmed Nassar, Nikolaos Livathinos, Maksym Lysak和Peter Staar等人。
他们把最精华的点子吃干抹净带走,然后把文章改头换面地发在了IEEE/CVF计算机视觉和模式识别会议论文集上。
剽过来的文章名叫「TableFormer: Table Structure Understanding with Transformers」,请大家擦亮慧眼。

论文地址:https://arxiv.org/abs/2203.01017
Xianbiao Qi表示,Nassar等人的文章把我们的整体方法,以及预处理和后期处理的部分、可视化部分、推理部分、给出的系统解决方案都抄了过去。甚至还有代码和预训练模型。
但是,Nassar等人没什么别的本事,完美包装却熟练得很。他们的文章没有一个字引用了Xianbiao Qi团队的文章内容。他们以为这样就能把查重蒙骗过去了。
通俗地讲就是,研究生抄袭一般直接抄文字,而这位苏黎世的博士后更「高级」——重写idea。
实际上,这办法还真行。Nassar等人的文章确实没被判定为抄袭。最后还是其他很多专家发现了两篇文章在idea上的雷同,转告给了Xianbiao Qi团队。
在Reddit上,有不少网友表示支持作者维权,同时也提醒他在举证的时候尽量不要带有情绪,虽然很难做到。
也有网友指出,现在列出的证据远非决定性的:
这两个团队在同一个问题上,使用相同的公开数据,解决方案也有相似之处。但这并不意味着一方抄袭了另一方。

而知乎上对此的讨论也非常热烈。


简要时间线
事情就是这么个事情,时间线还是有必要好好梳理一下的:
2021年4月7日,Xianbiao Qi团队结束了ICDAR 2021表格识别竞赛,并取得了第二名的成绩。这是由澳大利亚的IBM小组举办的。
同年5月5日,团队在arXiv上发表了想法的技术报告,以及预印版本。占了个坑。
两个月之后的7月29日,团队开源了相关代码,甚至还在Github上公开了相关的幻灯片。
2021年9月,团队发布了TableMASTER的预训练模型。11月,继续发布了tablemaster_mmocr的docker环境。
Xianbiao Qi自嘲道,「我们这个项目基本等于全裸了,该发布的全发布了。但我们发布是为了造福整个社区,不是方便你们抄袭来的。」
年底,来也技术团队在「表格识别方法评述及来也科技的实践」提到了这篇论文:
TableMASTER从一个非常新颖的角度来解决表格识别问题,是一次大胆的尝试,并且效果也是十分出色。PaddleOCR也用相似的思路开源了一个十分轻量的表格识别模型,并提供了PubTabNet数据集的预训练模型,略有不同的是paddleTable采用了RARE和GRU而不是MASTER和transformer。
时间来到2022年3月2日,TableFormer发布了。
当然,Xianbiao Qi愤怒之下没有丧失冷静,他列举了九大证据,实锤抄袭。
9大证据
Our methodology, you plagiarize
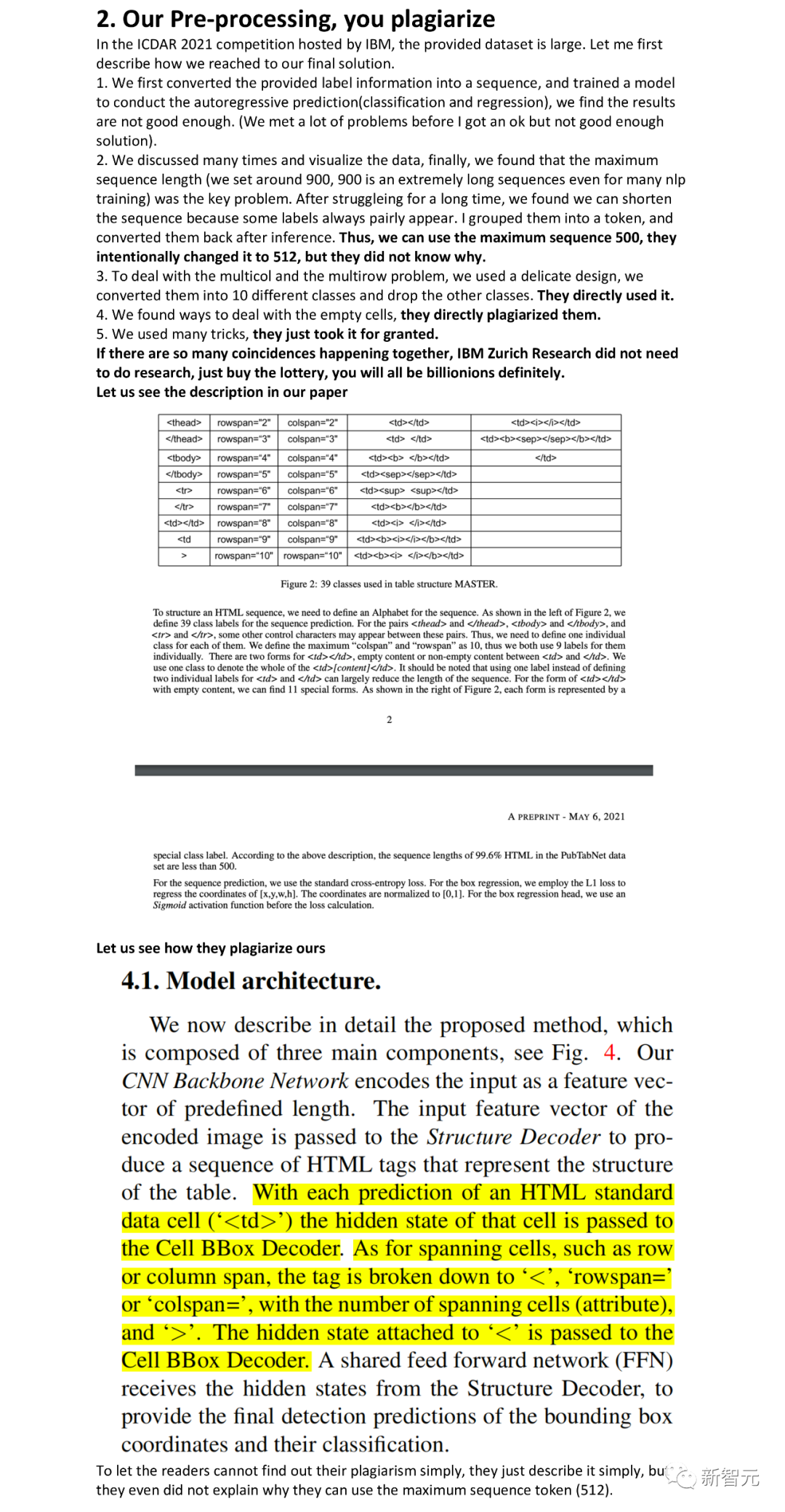
Our Pre-processing, you plagiarize
Our Post-processing, you plagiarize
Our Inference speedup method, you plagiarize
Our "tricky" work, you even plagiarize
Our text line detection and text line recognition, you plagiarize
Our systematic solution, you plagiarize
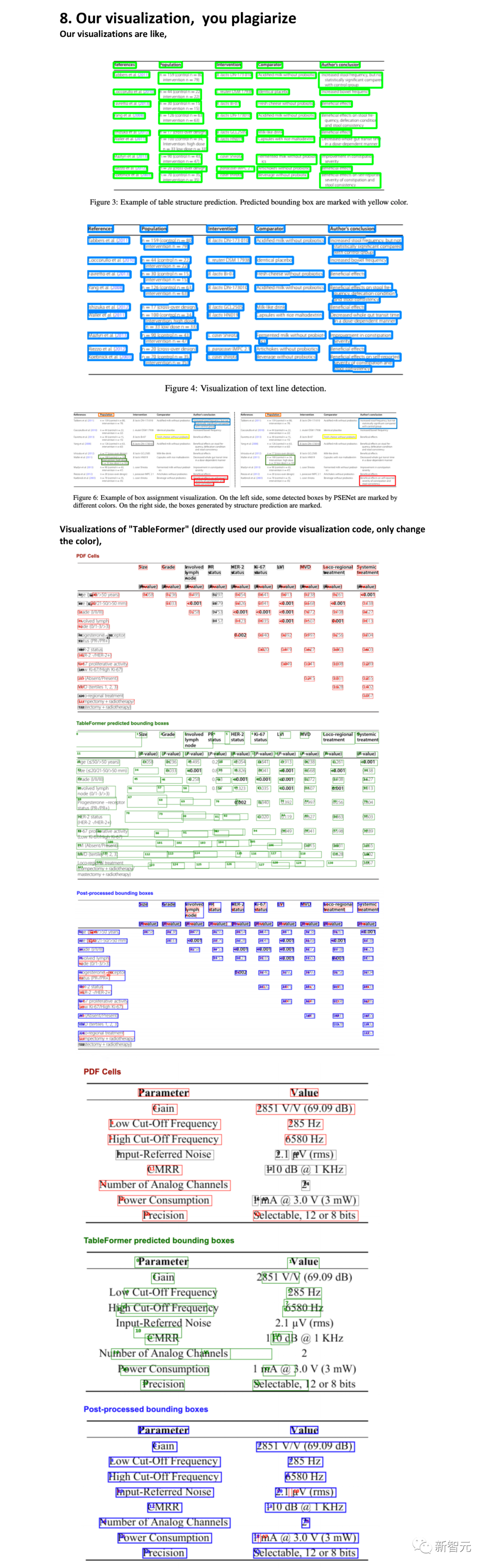
Our visualization, you plagiarize
Misleading the audiences in order to not be captured for plagiarism






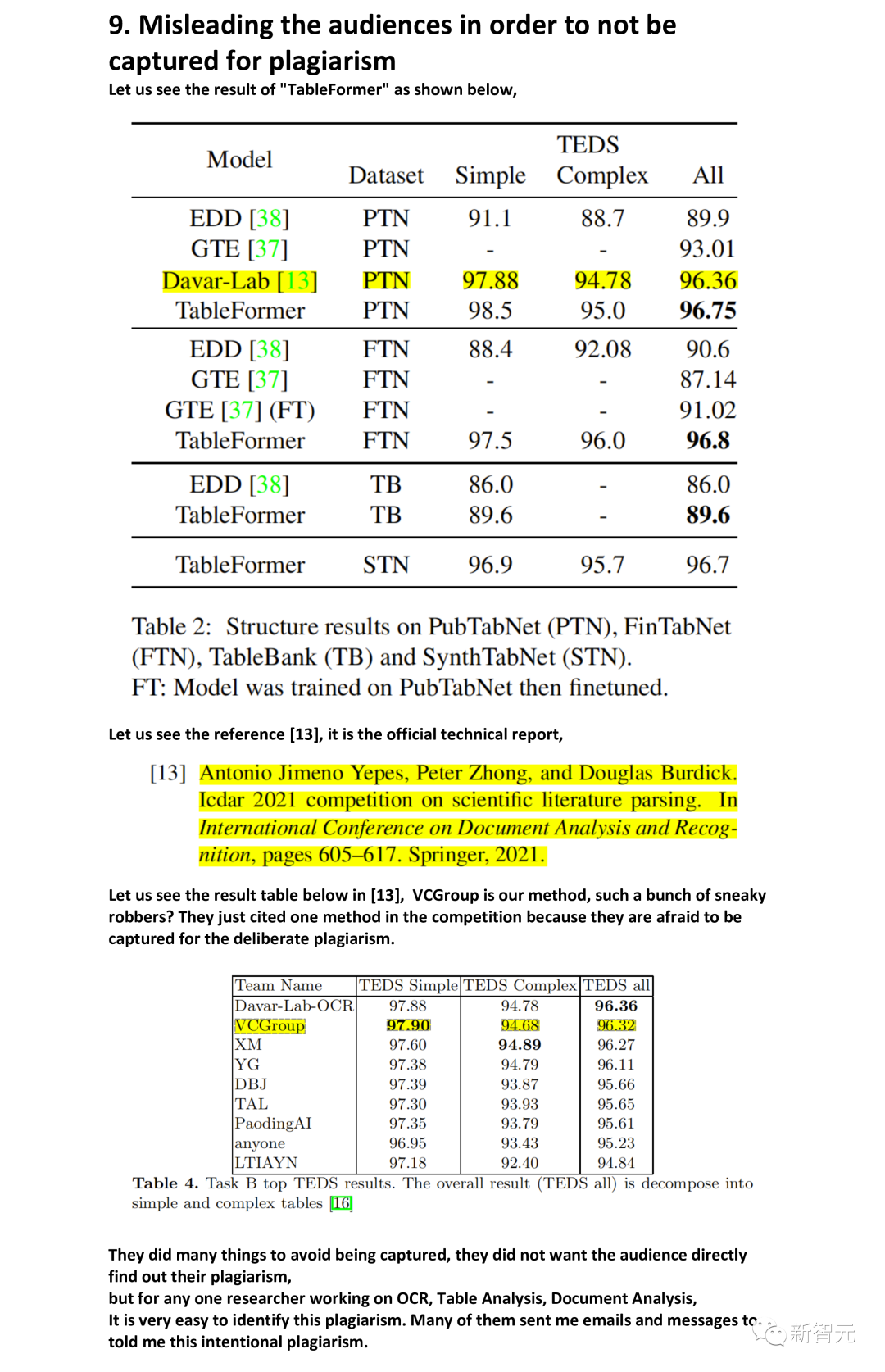
最后,作者表示这次学到的最深刻的教训就是:「即使开源了代码,也不要开源自己训练好的模型。」
参考资料:
