
利用Python实现数据偏移

现在有如下这么一张表,这张表存储了每个uid在不同周(w)的订单情况。我们想知道每个用户在不同周内消费频次的变化情况。消费频次变化的标准就是这周订单数和上周订单数的相对变化,如果这周订单比上周增加了,就说明消费频次提高了,反之则说明消费频次降低了。

要实现上面的需求,其实只需要新增一列,这一列用来存储每个uid在上一周期的订单情况,然后将两列进行做差,差的结果就是每个uid消费频次的变化。具体结果如下:
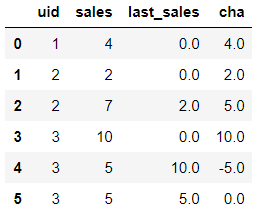
上面这个结果该如何实现呢?也就是如何让数据进行上下偏移呢?借助的就是Python中的shift函数,我们这一节就讲讲shift是怎么使用的。shift的功能是对数据进行偏移,该函数的具体参数如下:
df.shift(periods=1, freq=None, axis=0)
periods为偏移的幅度;freq只适用于时间索引的偏移,是对索引的偏移,而值不发生变化;axis用来指明是横向偏移还是纵向偏移,当axis=0时表示纵向偏移,默认就是纵向偏移,当要纵向偏移时,axis参数可以省略不写。当axis=1时表示横向偏移。如果periods为正,则表示向下/右偏移,如果peeriods为负,则表示向上/左偏移。接下来我们看一些具体实例:
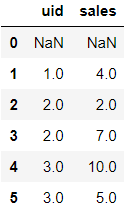
df.shift(1)
运行上面的代码,所有的数据向下偏移一行,具体结果如下:
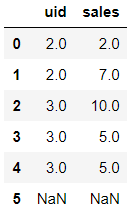
df.shift(-1)
运行上面的代码,所有的数据向上偏移一行,具体结果如下:
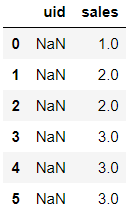
df.shift(1,axis = 1)
运行上面的代码,所有的数据向右偏移一列,具体结果如下:
df.shift(-1,axis = 1)
运行上面的代码,所有的数据向左偏移一列,具体结果如下:
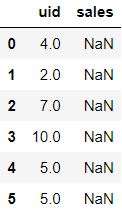
了解完了shift用法以后我们来看下我们开头那个需求该怎么做呢?新增加一列last_sales,并给其赋值为sales列,然后将last_sales这一列向上偏移一行。实现代码如下:
df["last_sales"] = df["sales"]
df["last_sales"] = df["last_sales"].shift(1)
df
运行上面代码,会得到每一行的sales_s与他的上一行的sales,这个sales不一定是他自己上一个周期的sales,比如第一个uid=2的上一个周期应该是0,但是这里面却是4:
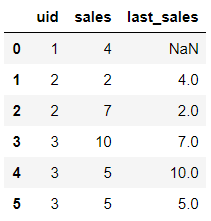
很明显,上面的结果并非我们想要的结果,我们想要的是每个uid内的上一个周期的sales,而非每一行sales对应的上一行的sales,那怎么办呢?方法就是在组内进行shift,也就是与groupby 进行组合使用,先对uid进行groupby,然后再进行shift偏移,具体代码如下:
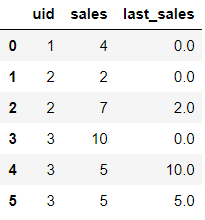
df["last_sales"] = df.groupby("uid")["sales"].shift(1).fillna(0)
df
最后运行上面的代码,就得到了我们开头想要的结果,即每个uid当期的sales和他自己上一期的sales,具体结果如下:
以上就是关于shift函数的使用情况。