
神经网络中,设计loss function有哪些技巧?
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自:视学算法
作者:Alan Huang
https://www.zhihu.com/question/268105631/answer/335246543
对于 gradient balancing问题,刘诗昆同学回答得挺不错。我这边再额外补充一些。
multi-task learning 中, tasks之间彼此的相容性对结果也会有一些影响。当两个任务矛盾的时候, 往往结果会比单任务还要差不少。
Multi-task learning 还需要解决的是Gradient domination的问题。这个问题产生的原因是不同任务的loss的梯度相差过大, 导致梯度小的loss在训练过程中被梯度大的loss所带走。 题主所说的问题1和2都是指这个问题。
如果一开始就给不同的Loss进行加权, 让它们有相近的梯度, 是不是就能训练的好呢? 结果往往不是这样的。 不同的loss, 他们的梯度在训练过程中变化情况也是不一样的;而且不同的loss, 在梯度值相同的时候, 它们在task上的表现也是不同的。在训练开始的时候,虽然balance了, 但是随着训练过程的进行, 中间又发生gradient domination了。 所以要想解决这个问题, 还是要合适地对不同loss做合适的均衡。
实践中应该要如何调整呢?其实很简单:
假设我们有两个task, 用A和B表示。 假设网络设计足够好, 容量足够大, 而且两个任务本身具有相关性,能够训得足够好。
如果A和B单独训练, 他们在收敛的时候的梯度大小分别记为 Grad_a, Grad_b, 那么我们只需要在两个任务一起训练的时候, 分别用各自梯度的倒数(1/Grad_a, 1/Grad_b)对两个任务做平衡, 然后统一乘一个scalar就可以了。(根据单任务的收敛时候的loss梯度去确定multi-task训练中不同任务的权重。)
因为loss的梯度在训练中通常会变小(这里用通常是因为一般mean square error等loss是这样, 其他有的Loss并不是。), 如果我们确定这个网络在multi-task训练的时候能够达到原来的效果, 我们就只需要把平衡点设在两个任务都足够好的时候。这样网络在训练过程中, 就自然能够达到那个平衡点, 即使一开始的时候会有gradient domination出现。
作者:刘诗昆
https://www.zhihu.com/question/268105631/answer/333738561
题主这个问题是 multi-task learning 里相当重要的一个核心问题。我正好在做相关的工作,很多细节将在论文投稿后再更新此答案。此外,我对 re-identfication 相关研究不熟所以无法回答第三个问题请见谅,望其他研究者补充。
理解多任务学习: Understanding Multi-task learning
Multi-task learning 核心的问题通常是可简单分为两类:
How to share: 这里主要涉及到基于 multi-task learning 的网络设计。
Share how much: 如何平衡多任务的相关性使得每个任务都能有比 single-task training 取得更好的结果。
题主的问题主要落在第二类,尽管这两个问题通常同时出现也互相关联。对于 multi-task learning 更加粗略的介绍以及和 transfer learning 的关系请参看我之前的回答:刘诗昆:什么是迁移学习 (Transfer Learning)?这个领域历史发展前景如何?其中同样包括了 task weighting 的一些讨论,以下再做更加细节的补充。
网络设计和梯度平衡的关系: The Relationship Between Network Design and Gradient Balancing
无论是网络设计还是平衡梯度传播,我们的目标永远是让网络更好的学习到 transferable, generalisable feature representation 以此来缓解 over-fitting。为了鼓励多任务里多分享各自的 training signal 来学泛化能力更好的 feature,之前绝大部分研究工作的重点在网络设计上。直到去年才有陆续一两篇文章开始讨论 multi-task learning 里的 gradient balancing 问题。
再经过大量实验后,我得出的结论是,一个好的 gradient balancing method 可以继续有效增加网络的泛化能力,但是在网络设计本身的提高强度面前,这点增加不足一提。更加直白的表达是:
Gradient balancing method 一定需要建立在网络设计足够好的基础上,不然光凭平衡梯度并不会对网络泛化能力有着显著的改变。
梯度统治: Gradient Domination
在 multi-task learning 里又可根据 training data 的类别再次分为两类:
one-to-many (single visual domain): 输入一个数据,输出多个标签。通常是基于 image-to-image 的 dense prediction。一个简单的例子,输入一张图片,输出 semantic segmentation + depth estimation。
many-to-many (multi visual domain):输入多个数据,输入各自标签。比如如何同时训练好多个图片分类任务。
由于不同任务之间会有较大的差异,平衡梯度的目标是为了减缓任务本身的由于 variance, scale, complexity 不同而导致的差异。
在训练 multi-task 网络时候则会因为任务复杂度的差异出现一个现象,我把他称之为: Gradient Domination, 通常发生在 many-to-many 的任务训练中。因为图片分类可以因为图片类别和本身数据数量而出现巨大差异。而基于 single visual domain 的 multi-task learning 则不容易出现这个问题因为数据集是固定的。
最极端的例子:MNIST + ImageNet 对于这种极端差异的多任务训练基本可以看成基于 MNIST initialisation 的网络对于 ImageNet 的 finetune。所以这种情况的建议就是:优先训练复杂度高的数据集,收敛之后再训练复杂度低的数据集。当然这种情况下,多任务学习也没有太大必要了。
对于一些差别比较大但是还是可接受范围的比如:SVHN + CIFAR100。这种情况的 gradient balancing 就会出现一定的效果但也取决于你输入数据的方式。输入数据的通常方法,例如在这篇文章里:Incremental Learning Through Deep Adaptation 就是通过一个 dataset switch 来决定更新哪一个数据集的参数。对于这种方法,起始 learning rate 调的低,网络本身就会有一个较好的下降速率。
动态加权梯度传播: Adaptive Weighting Scheme
即使光对优化网络调参并不能给多任务学习有着本质的改变。在考虑最 straightforward 的 loss: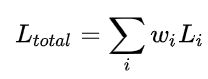 我们的目标是学习好一个
我们的目标是学习好一个  能够根据训练效果动态变化使得平衡网络的梯度传播。
能够根据训练效果动态变化使得平衡网络的梯度传播。
这个问题目前只有两篇文章做出了相关成果,
Weight Uncertainty: 这个是通过 Gaussian approximation 的方式直接对修改了 loss 的方式,并同时以梯度传播的方式来更新里面的两个参数。实际实验效果也还不错,在我复现的结果来看能有显著的提升但是比较依赖并敏感于一个合适的的 learning rate 的设置。
GradNorm : 是通过网络本身 back-propagation 的梯度大小进行 renormalisation。这篇文章写的比较草率并被最近的 ICLR 2018 拒绝收录了。个人期待他的更新作品能对方法本身有着更细节的描述。
Dynamic Weight Average: 我对于 GradNorm 一个更加简约且有效的改进,细节将会被补充。
一些总结
平衡梯度问题最近一年才刚刚开始吸引并产出部分深入研究的工作,这个方向对于理解 multi-task learning 来说至关重要,也可以引导我们去更加高效且条理化的训练多任务网络。但在之前,更重要的事情是理解泛化能力本身,个人觉得 multi-task learning 的核心目标不在于训练多个任务并得到超越单任务学习的性能,而是通过理解 multi-task learning 学习的过程重新思考并加深理解深度学习里 generlisation 的真正意义和价值。
作者:张小磊
https://www.zhihu.com/question/268105631/answer/333601828
一直认为设计或者改造loss function是机器学习领域的精髓,好的损失函数定义可以既能够反映模型的训练误差,也能够一定程度反映模型泛化误差,可以很好的指导参数向着模型最优的道路进发。接下来关于设计损失函数提一些自己的看法:
1、设计损失函数之前应该明确自己的具体任务(分类、回归或者排序等等),因为任务不同,具体的损失定义也会有所区别。对于分类问题,分类错误产生误差;对于排序问题,样本的偏序错误才产生误差等。
2、设计损失函数应该以评价指标为导向,因为你的损失函数需要你的评价指标来评判,因此应该做到对号入座,回归问题用均方误差来衡量,那么损失函数应为平方损失;二分类问题用准确率来衡量,那么损失函数应为交叉熵损失,等等。
3、设计损失函数应该明确模型的真实误差和模型复杂度(有种说法是,经验误差最小化和结构误差最小化),既要保证损失函数能够很好的反映训练误差,又要保证模型不至于过度繁琐(过拟合的风险),也就是奥卡姆剃刀原理,如无必要,勿增实体。
4、设计损失函数时我们应该善于变通、善于借鉴、善于迁移。以2017年WWW上的Collaborative metric learning为例,该文将SVM的hinge loss引入到了metric learning里边,使得越相近的类里的越近,不相近的类距离越远,同时会有一个最大边界来处理分类错误的点(软间隔),最后将该损失函数又引入到了推荐系统中的协同过滤算法(CF)中。可以看出对于自己的研究领域,我们可以借鉴经典的损失函数来为我所用,以此来提升该领域的性能。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~