
这招可以让Pandas 数据帧处理速度提高400倍!

数据处理是数据科学模型开发流程的重要组成部分之一。数据科学家需要花费80%的时间准备数据集以使其适合建模。有时,对大型数据集执行数据整理和探索变得繁琐的工作,只有等待很长时间才能完成计算,或者转移到某些并行处理。
Pandas 是拥有大量API的著名 Python 库之一,但是在可伸缩性方面却失败了。对于大型数据集,迭代整个循环有时会花费很多时间,有时甚至是数小时,甚至对于小型数据集,使用标准循环对数据框架进行迭代也非常耗时。
在本文中,我们将讨论在大型数据集上加快迭代过程的技术或技巧。
1、Pandas 内置函数:iterrows()
iterrows() 是内置的 Pandas 库函数,它返回一系列的每个实例或行。它将数据帧作为一对索引和列特征作为Series进行迭代。
我使用了一个具有1000万条记录和5列的数据集。我们在数据集中使用字符串类型的特征"name",必须将其删除以删除空格。
temp=[]
for i,row in df.iterrows():
name_new = row['name'].strip()
temp.append(name_new)
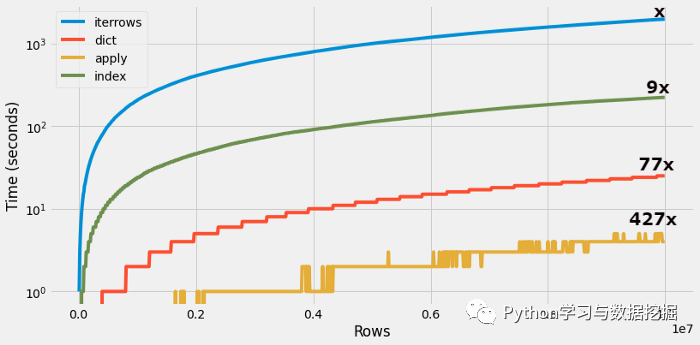
该代码段执行了将近「1967秒」。现在,让我们找出其他技术来遍历数据帧并比较其时间复杂度。
按索引迭代
数据框是具有行和列的Pandas对象。数据帧的行和列都已建立索引,并且可以遍历索引以遍历行。
temp=[]
for idx in range(0,df.shape[0],1):
name_new = df['name'].iloc[idx].strip()
temp.append(name_new)
遍历数据帧并执行剥离操作花了将近「223秒」(比iterrows函数快9倍)。
使用 to_dict()
只需将Pandas数据框转换为字典,即可遍历数据框并以闪电般的速度执行操作。你可以在Pandas中使用.to_dict()函数将数据框转换为字典。现在,与iterrows()函数相比,在字典上进行迭代相对非常快。
df_dict = df.to_dict('records')
temp=[]
for row in df_dict:
name_new = row['name'].strip()
temp.append(name_new)
对数据集的字典格式进行处理后耗时「25.5秒」,这比iterrows()函数快77倍。
使用 apply()
apply() 是内置的Pandas函数,它允许传递一个函数并将其应用于Pandas系列的每个值。apply()函数本身并不快,但是它对Pandas库有很大的改进,因为该函数有助于根据所需条件隔离数据。
temp = df['name'].apply(lambda x: x.strip())
apply() 函数执行耗时「4.60秒」,比iterrows() 函数快427倍。
结论
在本文中,我们讨论了在Pandas数据帧上进行优化的几种技术,并比较了它们的时间复杂度。建议在非常特殊的情况下使用iterrows()函数。
可以轻松地从使用iterrows()或索引方法转变为基于字典的迭代技术,该技术将工作流程的速度提高了77倍。Apply函数的速度提高了约400倍,但用途有限,人们需要对代码进行大量更改才能转换为这种方法。
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|
年度爆款文案
点阅读原文,领AI全套资料!

